









学习R-drop R-Drop: Regularized Dropout for Neural Networks
文章链接 https://arxiv.org/pdf/2106.14448v1.pdf
意思就是用dropout 去模拟bert中的mask 牛蛙牛蛙

一个输入x将经过模型两次,得到两个分布P1和P2,由于dropout的随机性导致两个输出有差异,
为了减少两个模型的输出的差异性,就使用了下面这个损失函数KL距离(相对熵)(Kullback-Leibler Divergence)衡量的是相同事件空间里的两个概率分布的差异情况
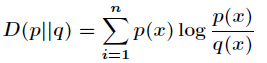
这个Dkl(P1||P2) 如何算的,如下面代码
def compute_kl_loss(self, p, q pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss回顾bert 预训练 词向量之BERT
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









