







Flume的介绍及入门案例
一、Flume介绍
Flume是一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统。Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS,Hbase,hive,kafka等众多外部存储系统中。
- 运行机制
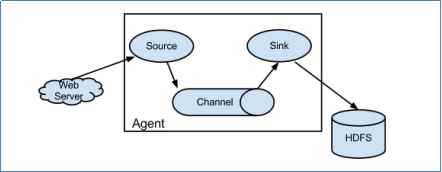
Flume分布式系统中最核心的角色是agent,Flume采集系统就是由一个个agent所连接起来形成的。
每一个agent中,内部有三个组件:
Source:采集源,用于跟数据源对接,以获取数据。
Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者传递给存储系统
Channel:agent内部的数据传输通道,用于从source将数据传递到Sink。
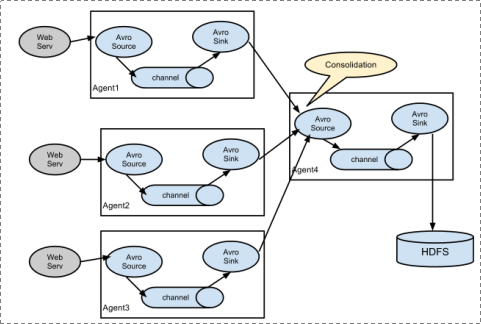
- agent多级串联
除此之外,agent还可以进行多级串联使用,如下图:
二、Flume安装和配置文件
- 下载
进行Flume的下载页面,选择对应的版本进行下载即可。
下载地址:
下载相应的apache-flume-x.x.x-bin.tar.gz包
- 解压安装
解压安装包:
tar -zxvf apache-flume-x.x.x-bin.tar.gz
- 修改配置文件
进入到解压后的flume目录下的conf目录,修改flume-env.sh中的JAVA_HOME配置,改为绝对路径。
export JAVA_HOME=/java/jdk1.8.0_161三、Flume的入门使用案例之logger输出
- 创建一个flume-first.conf文件,配置flume的agent的信息
在flume的conf目录下,使用
vim flume-first.conf创建并编辑文件。具体内容如下:
# 定义这个agent中各组件的名字,其中a1表示agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
# a1.sources.r1.type表示source源的类型
# 常用type的类型有:
# netcat:监听一个指定端口,并将接收到的数据的每一行转换为一个事件
# avro:接受avro序列化数据
# exec:命令输出作为源
# spooldir:监视该目录,并将解析新文件的出现
#
# 每一种type,对应的配置信息不一样。
a1.sources.r1.type = netcat
# source源绑定的主机名
a1.sources.r1.bind = localhost
# source源绑定的端口
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
# a1.sinks.k1.type表示sink下沉地的类型
# type的类型有很多:
# logger:表示logger输出
# hdfs:表示输出到hdfs
# hive:表示输出到hive
# avro:表示avro序列化输出
# file_roll:文件
# null:表示不用sink
# kafaka:表示输出到kafka
#
# 每一种sink的type,会对应一些type类型的配置信息。这里就不详细解释了。
# 表示logger输出
a1.sinks.k1.type = logger
# 描述和配置channel组件
# a1.channels.c1.type表示channel的类型
# 常用的type有:
# memony:event数据存储在内存中
# file:event数据存储在file中
# kafka:event数据存储在kafka中
#
# 每一种type对应的配置不一样
# channel使用内存储存
a1.channels.c1.type = memory
# channel的容量大小
a1.channels.c1.capacity = 1000
# channel每一次提交的event数量
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1这个配置信息,source–channel–sink是一对一的关系,可以通过定义多个source,channel,sink。进行描述多对多的指定。
- 指定flume使用flume-first.conf配置进行启动
# 指令参数介绍
# -c:表示指定flume自身配置文件所在目录
# -f:表示flume执行的配置文件
# -n:表示agent的名称,和配置文件中的一致
# -Dflume.root.logger=INFO,console:输出INFO级别信息到控制台
bin/flume-ng agent -c conf -f conf/flume-first.conf -n a1 -Dflume.root.logger=INFO,console- 测试
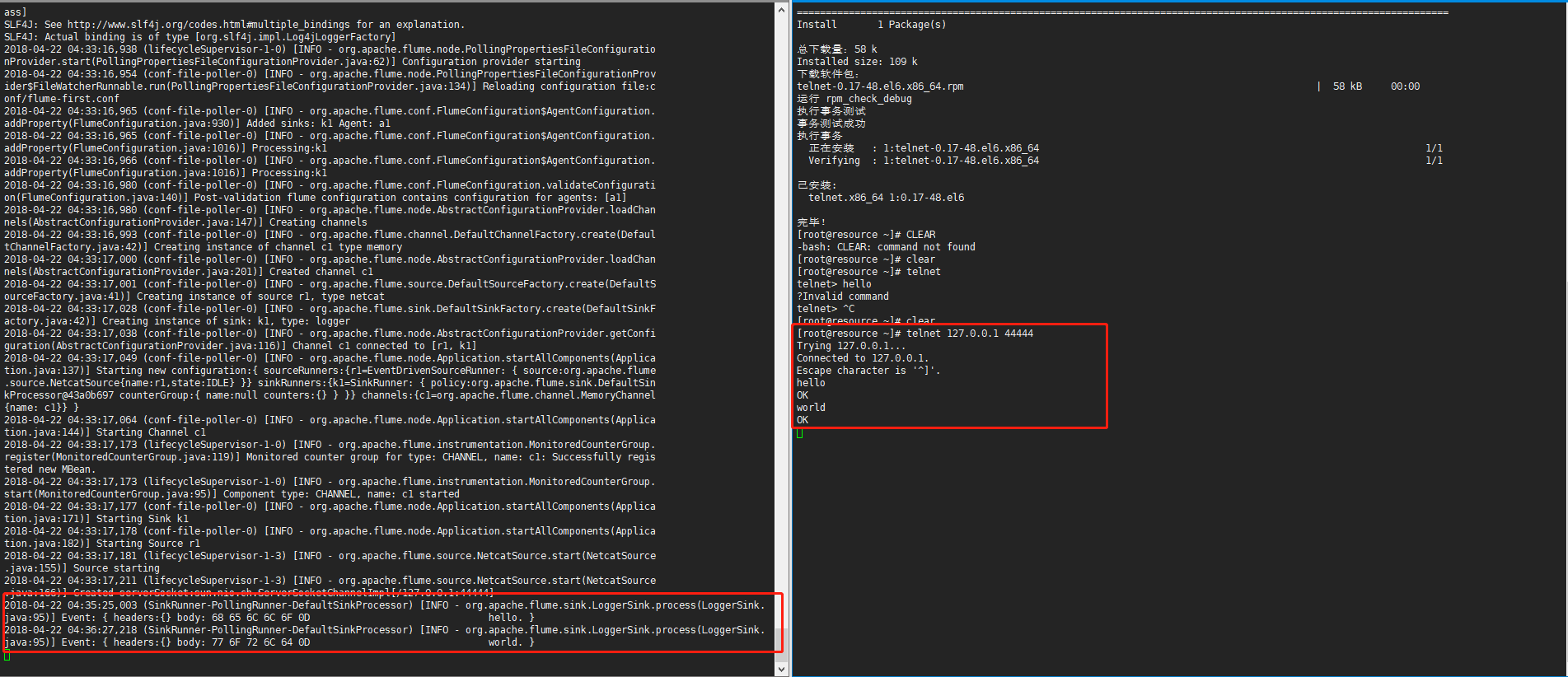
在另外一个窗口使用telnet命令进行测试
端口号是44444,在配置文件中指定
telnet 127.0.0.1 44444
如图:
如果没有telnet命令。可以使用yum安装一下:
yum -y install telnet
四、Flume的入门使用案例之HDFS输出
- 在flume的conf目录下,创建一个flume-hdfs.conf的配置文件,文件内容如下:
#定义三大组件的名称
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 配置source组件
# type指定为spooldir
a1.sources.source1.type = spooldir
# 设置监视的spooldir目录
a1.sources.source1.spoolDir = /home/hadoop/logs/
# 是否添加存储绝对路径文件名的头文件,默认false
a1.sources.source1.fileHeader = false
# 配置拦截器
# flume提供了一些拦截器,如host,timestmap,static,regex_filter等
# 过滤器是在source的内容的header字段中添加信息,进行过滤或分区等处理
#
# 添加拦截器
a1.sources.source1.interceptors = i1
# 设置拦截器类型
a1.sources.source1.interceptors.i1.type = host
# 设置host是hostname
a1.sources.source1.interceptors.i1.hostHeader = hostname
# 如果将useIP设置为false,则默认使用hostname,设置true,name使用IP
a1.sources.source1.interceptors.i1.useIP=false
# 配置sink组件
#
# sink 类型设置hdfs
a1.sinks.sink1.type = hdfs
# hdfs输出路径
a1.sinks.sink1.hdfs.path = /weblog/flume-log/%y-%m-%d/%H-%M
# 文件前缀
a1.sinks.sink1.hdfs.filePrefix = access_log
# 最大允许打开的HDFS文件数,当打开的文件数达到该值,最早打开的文件将会被关闭,默认5000
a1.sinks.sink1.hdfs.maxOpenFiles = 5000
# 每个批次刷新到HDFS上的events数量,默认100
a1.sinks.sink1.hdfs.batchSize= 100
# 文件格式,包括:SequenceFile, DataStream,CompressedStream,当使用CompressedStream时候,必须设置一个正确的hdfs.codeC值
a1.sinks.sink1.hdfs.fileType = DataStream
# 输出格式
a1.sinks.sink1.hdfs.writeFormat =Text
# 当临时文件达到该大小(单位:bytes)时,滚动成目标文件,默认1024,单位byte,如果设置成0,则表示不根据临时文件大小来滚动文件
a1.sinks.sink1.hdfs.rollSize = 1024
# 当events数据达到该数量时候,将临时文件滚动成目标文件,默认10,如果设置成0,则表示不根据临时文件大小来滚动文件
a1.sinks.sink1.hdfs.rollCount = 10
# hdfs sink间隔多长将临时文件滚动成最终目标文件,单位:秒。如果设置成0,则表示不根据时间来滚动文件
a1.sinks.sink1.hdfs.rollInterval = 60
# 是否启用时间上的"舍弃",这里的"舍弃",类似于四舍五入,如果启用,则会影响除了%t的其他所有时间表达式。默认false。
a1.sinks.sink1.hdfs.round = true
# 时间上进行“舍弃”的值,默认1
a1.sinks.sink1.hdfs.roundValue = 10
# 时间上进行”舍弃”的单位,包含:second,minute,hour,默认second
a1.sinks.sink1.hdfs.roundUnit = minute
# 是否使用当地时间,默认false
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Channel使用类型memony
a1.channels.channel1.type = memory
a1.channels.channel1.keep-alive = 120
a1.channels.channel1.capacity = 50000
a1.channels.channel1.transactionCapacity = 600
# source channel sink之间的绑定
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1- 启动flume
bin/flume-ng agent -c conf -f conf/flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console- 查看结果:
















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









