







Flume+Kafka+Storm+Redis流计算实现wordcount示例
一、前言
本文采用Flume、kafka、storm、redis来实现一个流计算的wordcount的小案例。
集群机器为server01,server02,server03。
3台机器上同时执行生成数据的python脚本,Flume的采集程序,zookeeper集群,kafka集群
在server01上启动redis-server服务。
二、生成数据的python脚本
python脚本文件:produce_log2.py
采用python3实现,逻辑是:每一秒从list集合中随机获取一条数据,写入/home/hadoop/log/access.log文件。
在server01,server02,server03机器上创建/home/hadoop/log目录
mkdir -p /home/hadoop/log以下是produce_log2.py脚本代码
import os
import time
import sched
import random
def create_log():
file = open("/home/hadoop/log/access.log", mode="a+", encoding='utf-8')
file.write(random.sample(list, 1)[0])
file.flush()
if __name__ == '__main__':
"""
python3.0 定时执行任务
"""
list = ['天魁星 呼保义 宋江\n', '天罡星 玉麒麟 卢俊义\n', '天机星 智多星 吴用\n', '天闲星 入云龙 公孙胜\n', '天勇星 大刀 关胜\n', '天雄星 豹子头 林冲\n',
'天猛星 霹雳火 秦明\n', '天威星 双鞭 呼延灼\n', '天英星 小李广 花荣\n', '天贵星 小旋风 柴进\n', '天富星 扑天雕 李应\n', '天満星 美髯公 朱仝\n',
'天孤星 花和尚 鲁智深\n', '天伤星 行者 武松\n', '天立星 双枪将 董平\n', '天捷星 没羽箭 张清\n', '天暗星 青面兽 杨志\n', '天佑星 金枪手 徐宁\n',
'天空星 急先锋 索超\n', '天速星 神行太保 戴宗\n', '天异星 赤发鬼 刘唐\n', '天杀星 黒旋风 李逵\n', '天微星 九纹龙 史进\n', '天究星 没遮拦 穆弘\n',
'天退星 插翅虎 雷横\n', '天寿星 混江龙 李俊\n', '天剑星 立地太岁 阮小二\n', '天平星 船火儿 张横\n', '天罪星 短命二郎 阮小五\n', '天损星 浪里白跳 张顺\n',
'天败星 活阎罗 阮小七\n', '天牢星 病关索 杨雄\n', '天慧星 拼命三郎 石秀\n', '天暴星 两头蛇 解珍\n', '天哭星 双尾蝎 解宝\n', '天巧星 浪子 燕青\n',
'地魁星 神机军师 朱武\n', '地煞星 镇三山 黄信\n', '地勇星 病尉迟 孙立\n', '地杰星 丑郡马 宣赞\n', '地雄星 井木犴 郝思文\n', '地威星 百胜将 韩滔\n',
'地英星 天目将 彭玘\n', '地奇星 圣水将 单廷圭\n', '地猛星 神火将 魏定国\n', '地文星 圣手书生 萧让\n', '地正星 铁面孔目 裴宣\n', '地阔星 摩云金翅 欧鹏\n',
'地阖星 火眼狻猊 邓飞\n', '地强星 锦毛虎 燕顺\n', '地暗星 锦豹子 杨林\n', '地轴星 轰天雷 凌振\n', '地会星 神算子 蒋敬\n', '地佐星 小温侯 吕方\n',
'地佑星 赛仁贵 郭盛\n', '地灵星 神医 安道全\n', '地兽星 紫髯伯 皇甫端\n', '地微星 矮脚虎 王英\n', '地慧星 一丈青 扈三娘\n', '地暴星 丧门神 鲍旭\n',
'地然星 混世魔王 樊瑞\n', '地猖星 毛头星 孔明\n', '地狂星 独火星 孔亮\n', '地飞星 八臂哪吒 项充\n', '地走星 飞天大圣 李衮\n', '地巧星 玉臂匠 金大坚\n',
'地明星 铁笛仙 马麟\n', '地进星 出洞蛟 童威\n', '地退星 翻江蜃 童猛\n', '地满星 玉幡竿 孟康\n', '地遂星 通臂猿 侯健\n', '地周星 跳涧虎 陈达\n',
'地隐星 白花蛇 杨春\n', '地异星 白面郎君 郑天寿\n', '地理星 九尾亀 陶宗旺\n', '地俊星 铁扇子 宋清\n', '地乐星 铁叫子 乐和\n', '地捷星 花项虎 龚旺\n',
'地速星 中箭虎 丁得孙\n', '地镇星 小遮拦 穆春\n', '地羁星 操刀鬼 曹正\n', '地魔星 云里金刚 宋万\n', '地妖星 摸着天 杜迁\n', '地幽星 病大虫 薛永\n',
'地僻星 打虎将 李忠\n', '地空星 小霸王 周通\n', '地孤星 金钱豹子 汤隆\n', '地全星 鬼脸儿 杜兴\n', '地短星 出林龙 邹渊\n', '地角星 独角龙 邹润\n',
'地囚星 旱地忽律 朱贵\n', '地蔵星 笑面虎 朱富\n', '地伏星 金眼彪 施恩\n', '地平星 鉄臂膊 蔡福\n', '地损星 一枝花 蔡庆\n', '地奴星 催命判官 李立\n',
'地察星 青眼虎 李云\n', '地悪星 没面目 焦挺\n', '地丑星 石将军 石勇\n', '地数星 小尉遅 孙新\n', '地阴星 母大虫 顾大嫂\n', '地刑星 菜园子 张青\n',
'地壮星 母夜叉 孙二娘\n', '地劣星 活闪婆 王定六\n', '地健星 険道神 郁保四\n', '地耗星 白日鼠 白胜\n', '地贼星 鼓上蚤 时迁\n', '地狗星 金毛犬 段景住\n']
schedule = sched.scheduler(time.time, time.sleep)
while True:
schedule.enter(1, 0, create_log)
schedule.run()
代码可单独测试
三、Flume配置
进入/hadoop/flume/conf目录
cd /hadoop/flume/conf创建一个flume-sink-kafka.conf文件,并编辑,内容如下:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type=exec
a1.sources.s1.command=tail -F /home/hadoop/log/access.log
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
#设置Kafka接收器
a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a1.sinks.k1.brokerList=server01:9092,server02:9092,server03:9092
#设置Kafka的Topic
a1.sinks.k1.topic=fksrtest
#设置序列化方式
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder
a1.sinks.k1.requiredAcks = 1
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1 四、kafka相关集群启动及主题创建
4.1 启动zookeeper集群
在每server01,server02,server03机器上启动zookeeper
zkServer.sh start关于zookeeper集群搭建,参考:Zookeeper集群环境搭建
4.2 启动kafka集群
关于kafka集群搭建,可参考:Kafka集群搭建及生产者消费者案例
在每一台机器上启动kafka集群
进入到/hadoop/kafka
cd /hadoop/kafka指定启动命令
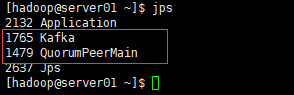
./bin/kafka-server-start.sh -daemon ./config/server.properties4.3 启动之后通过jps查看进程
每台机器上都包含以下进程,则是启动成功
Kafka
QuorumPeerMain如图:
4.4 创建kafka的主题topic
# 主题topic为fksrtest
kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic fksrtest
五、生产端测试
对生产数据端进行测试,以保证前面的操作是没问题的。
5.1 执行produce_log2.py的生成数据脚本
在每一台机器上执行该python脚本
python produce_log2.py执行脚本,查看access.log数据变化
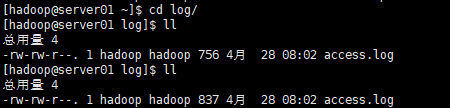
通过查询比对数据大小,access.log文件是不断在追加数据的
5.2 启动flume的数据采集程序
在每一台机器上执行flume的采集程序
# 进入/hadoop/flume目录
cd /hadoop/flume
# 执行flume的采集程序
bin/flume-ng agent -c conf -f conf/flume-sink-kafka.conf -name a1 -Dflume.root.logger=INFO,console5.3 在server01机器上,执行kafka-console-consumer.sh命令,以观察kafka数据的一个情况
cd /hadoop/kafka
./bin/kafka-console-consumer.sh --zookeeper server01:2181,server02:2181,server03:2181 --from-beginning --topic fksrtest结果如图:
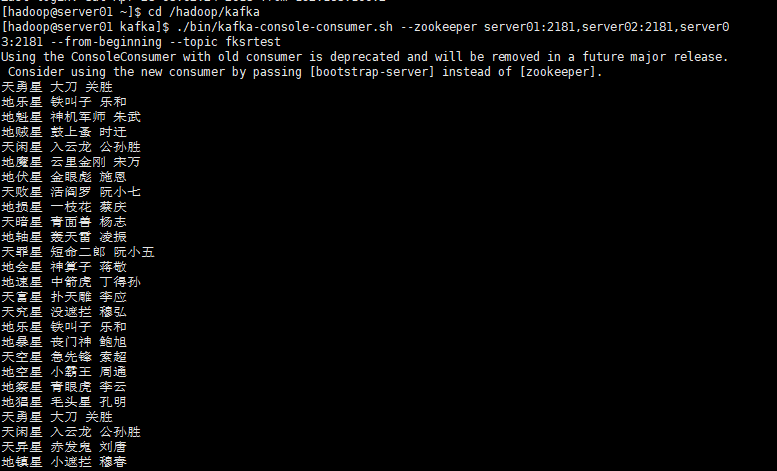
并且末尾还在不停的写入数据到命令窗口
以上测试表示,我们生产端的执行操作是OK的,接下来我们需要完成消费端的执行流程。
六、编写storm处理逻辑
6.1 pom.xml配置依赖
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<!--如果需要打成jar包,在storm集群上跑,则需要打开下面注释-->
<!-- <scope>provided</scope>-->
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>6.2 执行类MyTopology
public class MyTopology {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
BrokerHosts hosts = new ZkHosts("server01:2181,server02:2181,server03:2181");
String topic = "fksrtest";
String zkRoot = "/fksr";
String id = "fksrtest_id";
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
builder.setSpout("spout", new KafkaSpout(spoutConf), 2);
builder.setBolt("bolt1", new Bolt1(), 4).shuffleGrouping("spout");
builder.setBolt("bolt2", new Bolt2(), 2).shuffleGrouping("bolt1");
StormTopology topology = builder.createTopology();
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("fksrwordcount", new Config(), topology);
}
}6.3 Bolt1类
Bolt1类主要负责切分line数据成word,然后将word,num数据发送给Bolt2处理
public class Bolt1 extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
byte[] bytes = (byte[]) input.getValueByField("bytes");
String line = new String(bytes);
String[] splits = line.split(" ");
for (String word : splits) {
collector.emit(new Values(word, 1));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}6.4 Bolt2类
Bolt2类,将word,num数据存放到一个map集合中,再将map集合存放到redis缓存中
public class Bolt2 extends BaseBasicBolt {
private Jedis jedis;
private HashMap<String, String> map = new HashMap<String, String>();
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
jedis = new Jedis("server01", 6379);
}
public void execute(Tuple input, BasicOutputCollector collector) {
String word = (String) input.getValueByField("word");
Integer num = (Integer) input.getValueByField("num");
String result = map.get(word);
if (StringUtils.isNotEmpty(result)) {
int res = Integer.parseInt(result);
map.put(word, (num + res) + "");
} else {
map.put(word, num + "");
}
jedis.hmset("fksrtest", map);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}为了方便测试,这里直接使用了storm的本地模式。
七、启动redis服务
在server01机器上启动redis-server
redis-server /usr/local/redis/redis-conf八、消费端启动测试
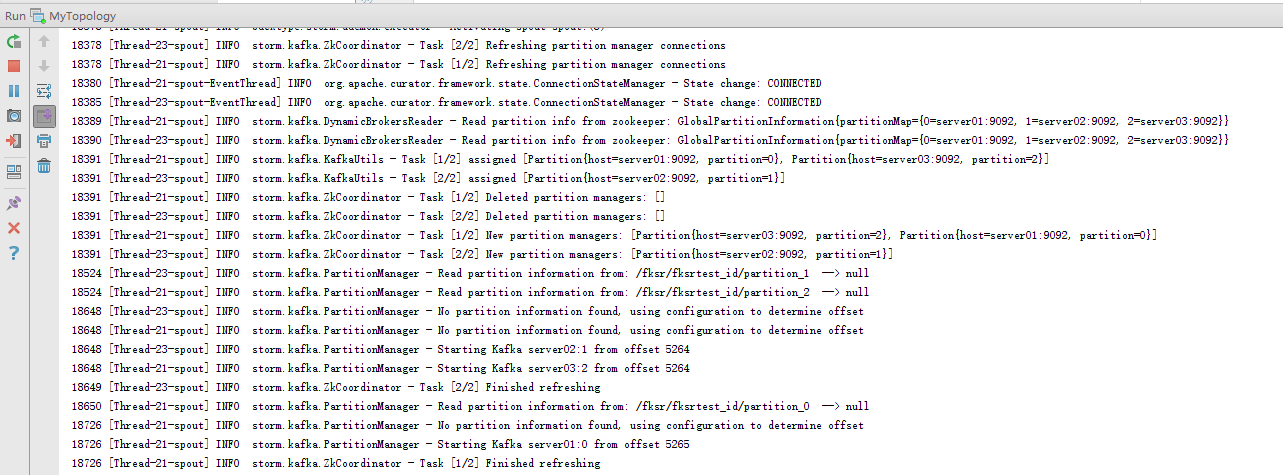
8.1 启动storm的程序
直接运行MyTopology类
8.2 执行Redis的java测试代码
public class RedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("server01", 6379);
for (String key : jedis.hkeys("fksrtest")) {
System.out.println(key + ":" + jedis.hmget("fksrtest", key));
}
}
}我们可以看到redis中的数据:
这样我们的这个小案例就完成了















 6847
6847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









