






C 题 就业状态分析与预测
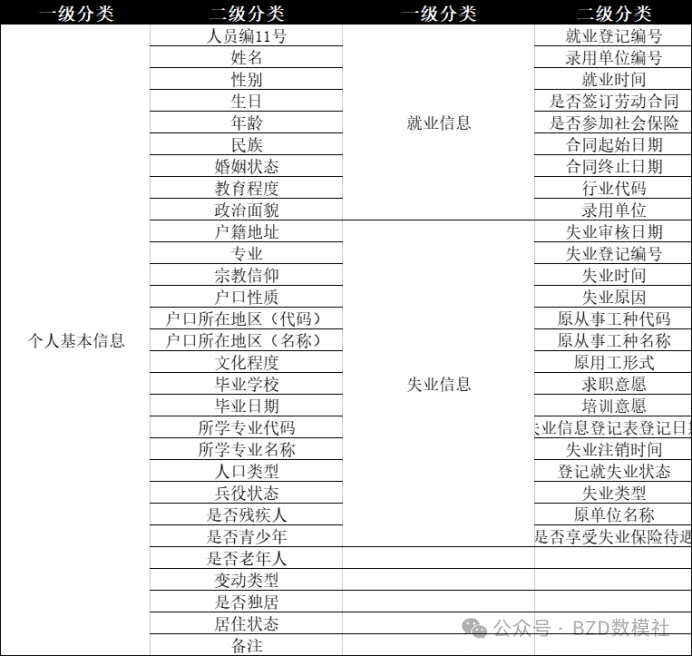
本文将为大家来带2025年华中杯C题超详细解题思路+初步代码分享,以便大家可以尽快上手C题。对于数据类型题目,首先需要进行数据清洗工作。 基于给出的下述各项指标,数据清洗主要分析 缺失值处理、异常值处理、描述性分析
缺失值处理:
以下为初步筛选的缺失数据
| 具体名称 | 缺失项数 | 具体内容 |
| 户籍地址 | 3 | 1145 6601958 郑** |
| 专业 | 1146 | 3 4928113 赵** |
| 毕业学校 | 1 | 4188 629904 饶** |
异常数据处理:
1、逻辑异常
示例1 出生年份 计算填写人信息 是否年龄真实
示例2 户籍地址 无效信息
| 具体名称 | 异常项数 | 具体内容 |
| 户籍地址 | 3 | 1411 6459331 谭** |
| 文化程度 | 1 | 5957676 张** |
| 就业时间 | 1 | 1905/7/10 0:00 |
1、边缘值异常
当前就业状态判定,我们以表格中“失业注销时间”为标准,存在注销时间我们认为该人已经是就业状态,无失业注销时间记录则为失业状态(5000个样本都是最开始失业的样本)
最终清洗后,得到3827个样本,后续可以进行必要的描述性分析
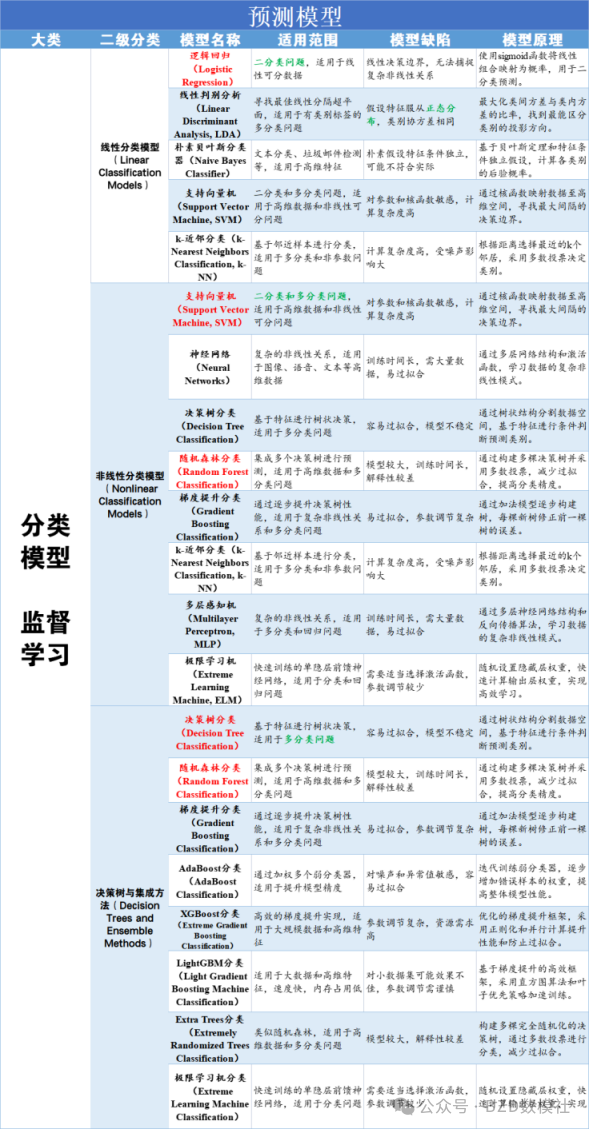
问题一:数据特征分析
问题一的主要目的是通过筛选,从50+个变量中,选出对失业就业状态最有影响的几个以便进行后续建模。因此,通过统计人员按照年龄、性别、学历、专业、行业与失业的关系即可。下面是,基于上述数据清洗后的数据进行的统计分析。
| 变量名 | 值 | 描述 | 变量名 | 值 | 描述 |
| 性别 | 1 | 男 | 婚姻状态 | 10 | 未婚 |
| 2 | 女 | 20 | 已婚 | ||
| 民族 | 1 | 汉族 | 30 | 丧偶 | |
| 2 | 蒙古族 | 40 | 离婚 | ||
| 3 | 回族 | 政治面貌 | 0 | 群众 | |
| 6 | 苗族 | 1 | 中国共产党党员 | ||
| 11 | 满族 | 3 | 中国共产主义青年团团员 | ||
| 15 | 土家族 | 9 | 中国致公党党员 | ||
| 97 | 其他 | 文化程度 | 31 | 大学专科 | |
| 婚姻状态 | 10 | 未婚 | 41 | 中等专科 | |
| 20 | 已婚 | 21 | 大学本科 | ||
| 30 | 丧偶 | 14 | 硕士研究生 | ||
| 40 | 离婚 | 90 | 其他 |
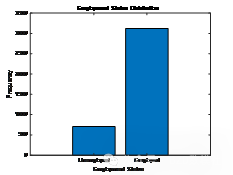
整体就业状态分析:
就业人数:3122
失业人数:705
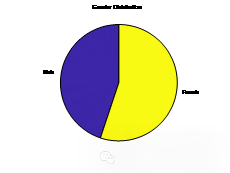
按性别分析就业状态:
Gender Employed Unemployed
______ ________ __________
1 1444 274
2 1678 1431
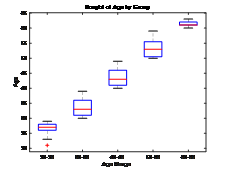
AgeGroup Employed Unemployed
_________ ________ __________
{'20-29'} 1549 290
{'30-39'} 1354 312
{'40-49'} 169 79
{'50-59'} 40 24
{'60-69'} 10 0
{'70-79'} 0 0
按学历分析就业状态:
EducationLevel Employed Unemployed
______________ ________ __________
14 8 1
21 1733 278
31 1968 398
41 12 5
90 106 23
问题二:就业状态预测
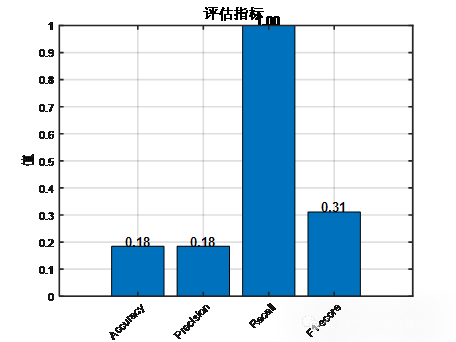
根据分析结果,我们可以看出年龄 性别 学历 专业 婚姻状态都能够对失业与否产生较大影响。使用机器学习模型(具体模型大纲,可看文末),如 决策树、随机森林、支持向量机(SVM) 或 逻辑回归 来建立预测模型。
这里以逻辑回归模型为例进行示例说明,后续将加入多模型精度对比进一步丰富
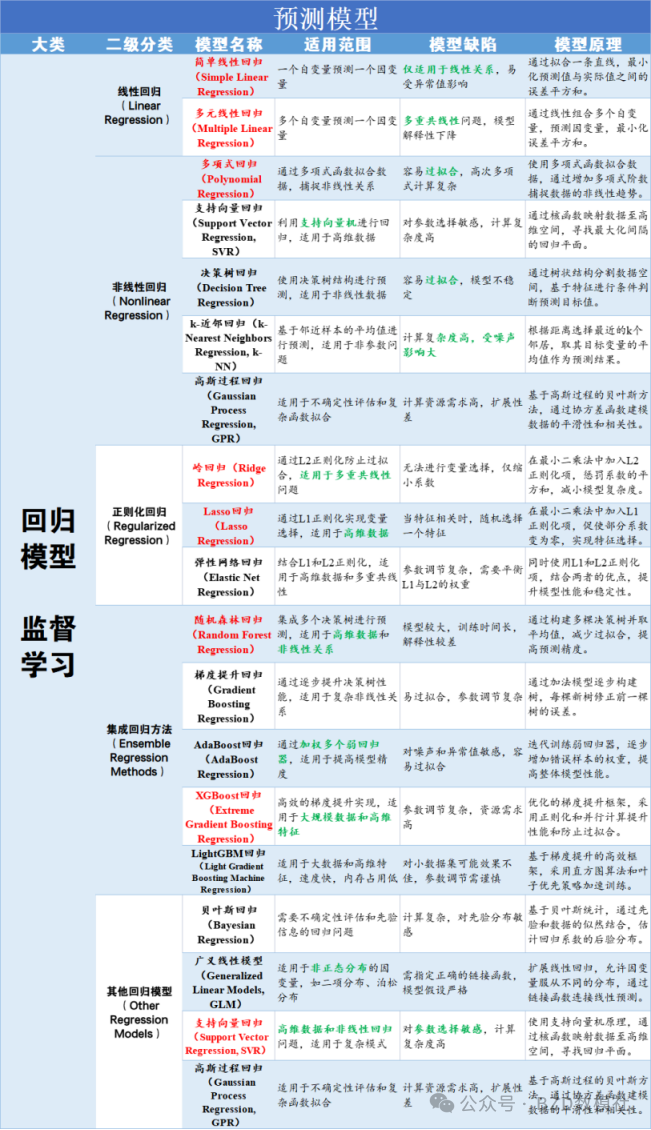
问题三:就业状态预测模型优化
除了个人层面因素影响外,宏观经济、政策、劳动力市场状况、宜昌市居民、消费价格指数、招聘信息等也可能会影响就业状态。因此,我们从国家统计局收集了近20年每个月的各种指标
| 指标 | 国民总收入(亿元) | 劳动力(万人) | 居民消费价格指数(1978=100) | 年末总人口(万人) |
| 2024年 | 1339672 | 140828 | ||
| 2023年 | 1283680.3 | 77216 | 708 | 140967 |
| 2022年 | 1223706.8 | 76863 | 706.6 | 141175 |
| 2021年 | 1165816.8 | 78024 | 692.7 | 141260 |
| 2020年 | 1026751.9 | 78392 | 686.5 | 141212 |
根据问题三需求,在国家统计局下载了2000-2025年各指标数据,我们利用居民失业就业时间识别对应时刻下的各项指标数据,作为模型输入变量进行输入
|
|
| |
| 失业、就业分析对比 | 各年龄段人数统计 | 各指标数据相关性热分析 |
|
|

















 5304
5304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









