






本文将为大家带来华中杯赛题浅析,将会简略的介绍每个题目题目、涉及模型、后续求解中可能遇到的难点。以便大家能够快速完成选题。
初步预估 选题人数(后续会根据各平台投票结果进行更更新)
赛题难度 A:B:C:D=4:5:3:2
选题人数 A:B:C:D=2:1:4:1
一图流如下所示
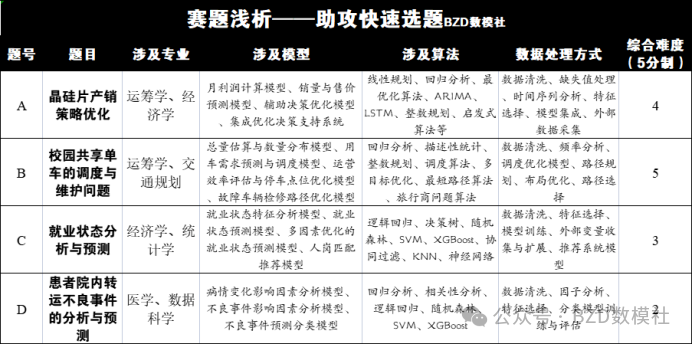
A 题:晶硅片产销策略优化
问题 1:月利润计算模型
决策变量:四型硅片的销量、售价、单晶方棒进价等。
模型建立:通过利润 = 销售收入 成本来构建月利润计算模型,考虑生产和销售的各个环节。
销售收入 = 每个型号的售价 × 销量
成本:包括硅单耗、耗材价格、生产变动成本、生产公用成本、人工成本等。
利润优化:根据模型中的敏感性分析,找到最能提高利润的因素,进行调整。
问题 2:销量、售价、单晶方棒价格等的波动趋势预测
数据分析:利用历史数据中的销量、售价等变量进行回归分析或时间序列预测(如ARIMA、LSTM等)。
模型构建:采用回归或时间序列预测模型,预测各因子的波动趋势。
波动区间:通过预测结果的置信区间来推测合理变化区间。
问题 3:辅助决策优化模型
目标函数:最大化利润。
约束条件:包括生产能力、原材料采购量、市场需求等。
优化方法:可以使用线性规划、整数规划等方法,结合生产和销售计划,给出最佳生产计划与销售策略。
问题 4:大语言模型辅助决策
数据准备与清洗:清洗历史数据,处理缺失值和异常值。
大模型融入:使用开源的预训练语言模型(如GPT系列),结合行业知识进行综合分析,提供决策支持。
集成方案:将大语言模型的预测与传统的数学优化模型结合,形成一个集成决策系统。
B 题:校园共享单车的调度与维护问题
问题 1:共享单车总量估算与数量分布
数据分析:利用统计方法估算共享单车的总量,并计算不同停车点位在不同时间的数量分布(可以用平均数、方差等指标描述分布情况)。
问题 2:用车需求模型与调度模型
用车需求模型:基于历史数据建立需求预测模型(例如回归模型或时间序列模型),预测不同时间段的用车需求。
调度模型:可以使用运筹学中的调度问题模型(如车辆路径问题、最短路径问题等),模拟调度车的路线和调度计划,最大化高峰期的车辆供给。
问题 3:运营效率评估与布局优化
运营效率模型:通过系统的模拟和评估,确定当前布局的效率,并分析各停车点的使用率和空闲率,评估其合理性。
布局调整方案:根据需求分析,优化停车点的位置和数量,以提高单车的周转效率。
问题 4:检修路线优化
巡检模型:通过路径规划算法(如最短路径算法、旅行商问题等),设计鲁迪的检修路线,以最短的时间将故障车辆运回检修处。
C 题:就业状态分析与预测
问题 1:就业状态特征分析
数据分析:对就业状态的影响因素进行统计分析,使用描述性统计和可视化方法(如柱状图、饼图)展示各因素的分布。
划分特征分析:使用分层分析或卡方检验等方法,分析不同年龄、性别、学历、行业等特征对就业状态的影响。
问题 2:就业状态预测模型
特征选择与建模:使用机器学习方法(如决策树、随机森林、SVM等)选择与就业状态相关的特征,并训练分类模型进行预测。
评估指标:使用准确率、召回率、F1等指标评估模型效果,并进行交叉验证。
问题 3:外部变量与模型优化
收集外部数据:收集宏观经济、市场等外部数据,作为模型的附加输入。
模型优化:通过加入外部变量,提升预测模型的准确性和鲁棒性。
问题 4:人岗精准匹配
人岗匹配模型:建立一个基于多维度(如技能、薪资、行业等)的匹配模型,可以使用推荐算法(如协同过滤)为失业人员提供工作推荐。
D 题:患者院内转运不良事件的分析与预测
问题 1:病情变化影响因素分析
数据分析:通过回归分析或多变量分析,评估转运过程中各因素对病情变化的影响。
问题 2:不良事件影响因素分析
相关性分析:使用皮尔逊相关系数、卡方检验等方法,分析各影响因素与不良事件之间的相关性。
问题 3:不良事件预测模型
模型选择:可以使用逻辑回归、随机森林或支持向量机等分类模型,预测不良事件的发生。
评估与优化:使用混淆矩阵、ROC曲线等指标评估模型性能,并进行模型调优。

















 6177
6177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









