







本文在MatlabR2016b上使用自带的深度学习工具实现RCNN来进行车辆检测。
实验环境
训练图片数量:825(网上收集+部分公共数据集)
图片车辆数量:2300(对每张图片手工标注label得到)
实验环境:MatlabR2016b(自带深度学习工具)
CPU:I7-4510U
显卡:NVIDIA GeForce840M(必须是N卡,因为需要使用cuda加速)
内存:8G
图片标注
使用matlab自带的M文件trainingImageLabeler.m来对图片进行标注,which一下就知道这个文件在哪了。
which trainingImageLabeler.m打开之后运行就会出现这个界面
选择AddImages将要训练的图片放进去(可以放入多张图片),在ROI Label区域右键可以选择改变label 的color和name,如果要训练多个类,也可以点击Add ROI Label来添加label。
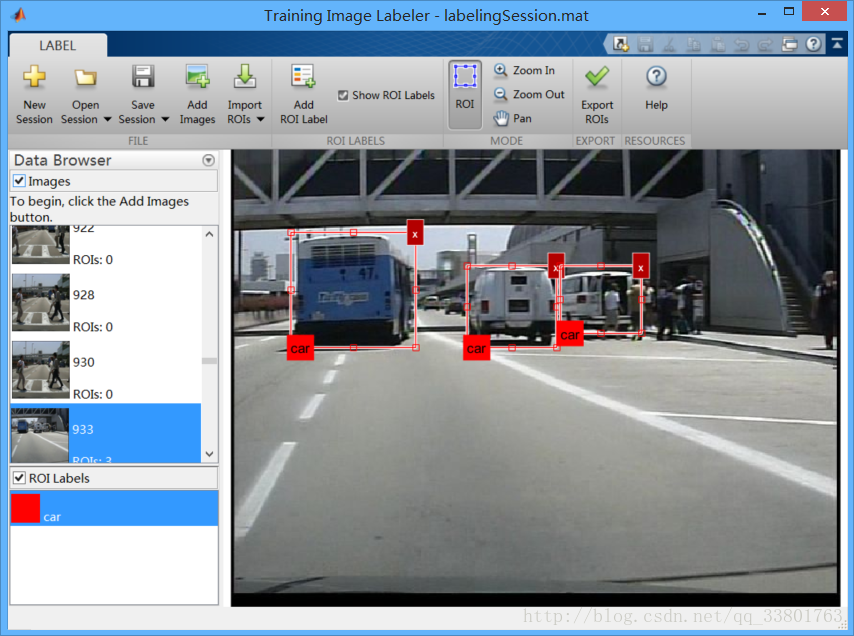
所有label标注完后点击 Export ROIs 就会得到像这样的一个table文件。
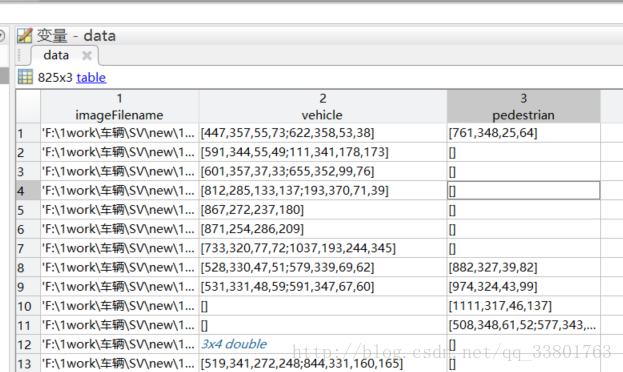
imageFilename代表了图片所存储的位置;
vehicle和pedestrian代表了图片中标注的车辆和行人,用矩阵存储,分别为图片左上的坐标(x,y)和图片的大小(width,height);
在有的公共数据集中,可能会提供原始图片和图片的标注信息,只要将标注信息做成这样的table就可以。如BIT-vehicle数据集中就提供了图片标注信息,用以下代码做成类似RCNN的数据格式。
clear;clc;
load('VehicleInfo.mat');
n=size(VehicleInfo,1);
a=cell(n,2);
d='F:\1work\车型识别\BIT-vehicle\BITVehicle_Dataset\';
for i=1:n
path=[d VehicleInfo(i).name];
m=VehicleInfo(i).nVehicles;
b=[];c=[];
for j=1:m
x=VehicleInfo(i).vehicles(j).left;
y=VehicleInfo(i).vehicles(j).top;
w=VehicleInfo(i).vehicles(j).right-VehicleInfo(i).vehicles(j).left;
h=VehicleInfo(i).vehicles(j).bottom-VehicleInfo(i).vehicles(j).top;
b=[x,y,w,h];
c=[c;b];
end
a{i,1}=path;
a{i,2}=c;
endRCNN训练
trainRCNNObjectDetector
RCNN的训练主要使用trainRCNNObjectDetector.m函数
detector = trainRCNNObjectDetector(groundTruth,network,options)groundTruth - 具有2个或更多列的表。 第一列必须包含图像文件名。 图像可以是灰度或真彩色,可以是IMREAD支持的任何格式。 其余列必须包含指定每个图像内对象位置的[x,y,width,height]边框的M×4矩阵。 每列表示单个对象类,例如。 人,车,狗。 其实就是之前使用trainingImageLabeler做标注得到的数据。
network - 即为CNN的网络结构
options - 即为网络训练的参数。包括初始化学习率、迭代次数、BatchSize等等。
除了以上三个参数外,还有
‘PositiveOverlapRange’ - 一个双元素向量,指定0和1之间的边界框重叠比例范围。与指定范围内(即之前做图片标注画出的框)的边界框重叠的区域提案被用作正训练样本。Default: [0.5 1]
‘NegativeOverlapRange’ - 一个双元素向量,指定0和1之间的边界框重叠比例范围。与指定范围内(即之前做图片标注画出的框)的边界框重叠的区域提案被用作负训练样本。Default: [0.1 0.5]
在训练之前,RCNN会从训练图片中得到很多候选框,其中满足正样本要求的会被当做训练正样本,而满足负样本要求的会被当做训练负样本。
‘NumStrongestRegions’ - 用于生成训练样本的最强区域建议的最大数量(即最后得到的候选框数量)。 降低该值以加快处理时间,以训练准确性为代价。 将此设置为inf以使用所有区域提案。Default: 2000
迁移学习
CNN的训练是非常耗费时间的,所以直接使用网上训练好的模型继续训练可以大大的节约训练时间。cifar10Net是matlab自带的,其结构如下图。同时也可以去http://www.vlfeat.org/matconvnet/models/ 下载alexnet、VGG16等结构。(由于显卡配置太低,跑了一晚上alexnet都没反应,所以无法使用复杂结构的CNN结构,无奈)
load('rcnnStopSigns.mat','cifar10Net');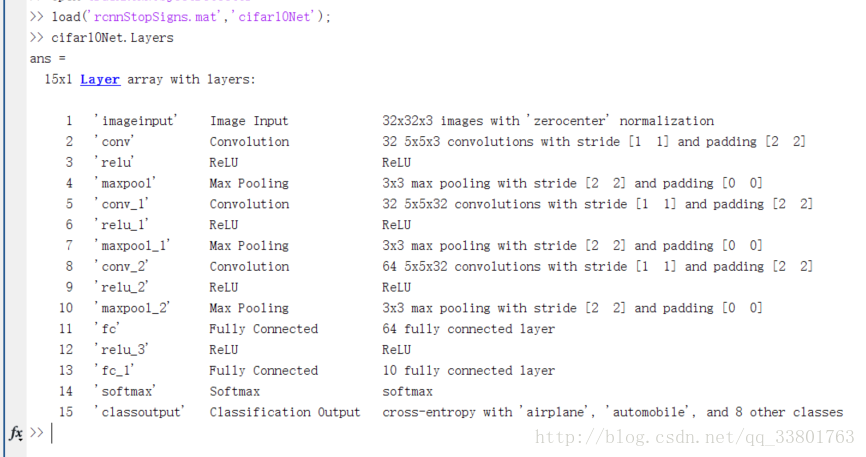
由于是车辆检测,只有有车和无车两类,所以需要将最后一个全连接层输出改为2,后面接上softmax层和classoutput层。整个训练过程如下:
clear;clc;
load data_v.mat;
load('rcnnStopSigns.mat','cifar10Net');
x=cifar10Net.Layers(1:end-3);
lastlayers = [
fullyConnectedLayer(2,'Name','fc8','WeightLearnRateFactor',1, 'BiasLearnRateFactor',1)
softmaxLayer('Name','softmax')
classificationLayer('Name','classification')
];
mylayers=[x;lastlayers];
options = trainingOptions('sgdm', ...
'MiniBatchSize', 32, ...
'InitialLearnRate', 1e-6, ...
'MaxEpochs', 100);
myRCNN = trainRCNNObjectDetector(data_v, mylayers, options, ...
'NegativeOverlapRange', [0 0.3]);RCNN测试
tic;
detectedImg = imread('15.bmp');
[bbox, score, label] = detect(myRCNN2, detectedImg, 'MiniBatchSize', 20);
%显示最强检测结果
% [score, idx] = max(score);
idx=find(score>0.9);
bbox = bbox(idx, :);
% annotation = sprintf('%s: (Confidence = %f)', label(idx(1)), score(idx(1)));
% detectedImg = insertObjectAnnotation(img, 'rectangle', bbox(1,:), annotation);
n=size(idx,1);
for i=1:n
annotation = sprintf('%s: (Confidence = %f)', label(idx(i)), score(idx(i)));
detectedImg = insertObjectAnnotation(detectedImg, 'rectangle', bbox(i,:), annotation);
end
figure
imshow(detectedImg);
toc;部分测试结果如下图:


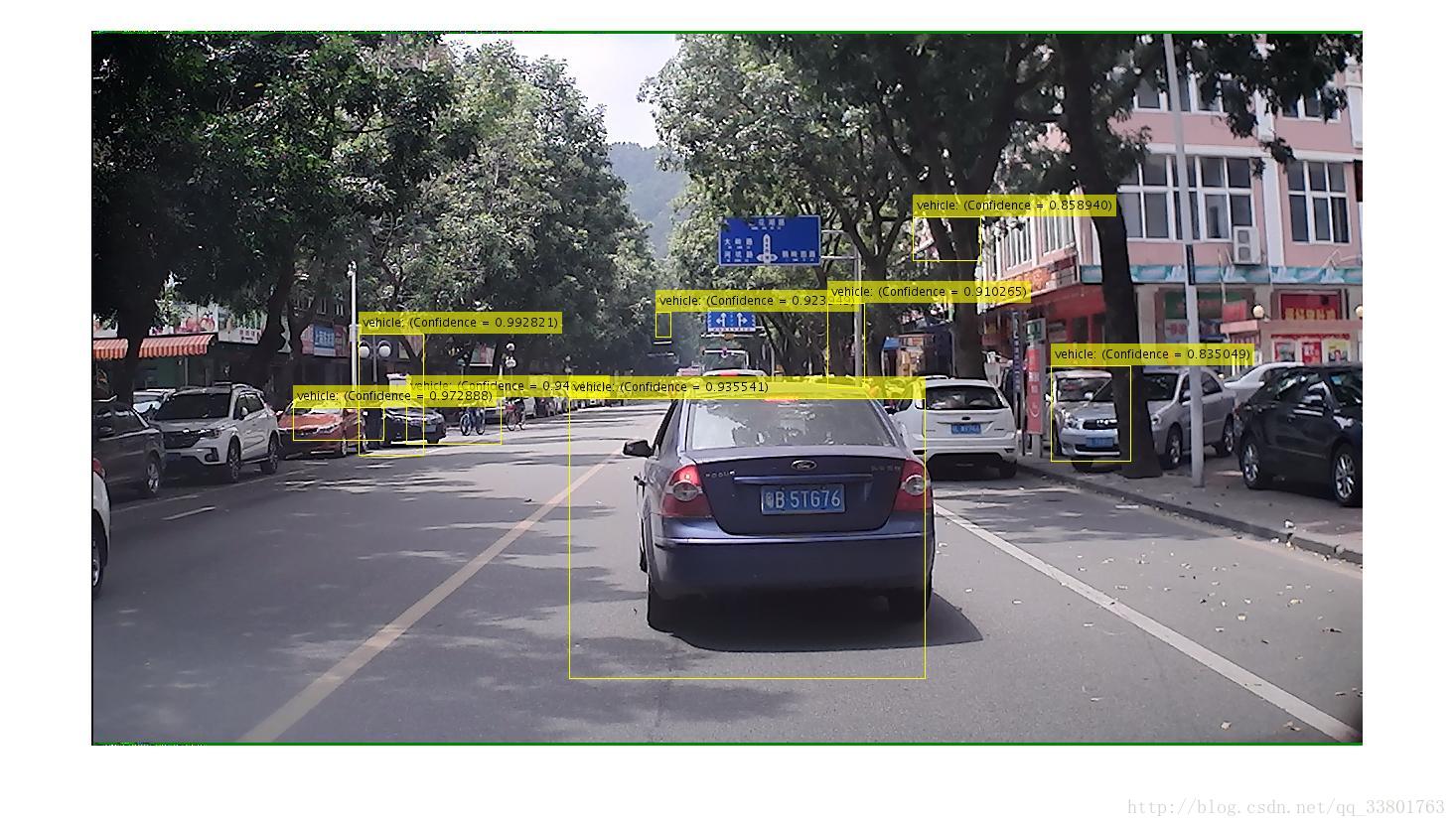
从检测结果看出:
1.对于背景简单且车辆数目不多的图像,检测效果良好;
2.对于背景复杂且车辆数目较多的图像,容易出现误检测和多个重复的检测窗口;
3.外观类似车辆外形的物体也容易被检测出来;
4.有的图像只能检测出车辆的一部分,检测不出车辆整体;
5.有的图像中车辆部分的score高于车辆整体;
6.远处小物体的检测,误检率更高。
如何改进:
1.增加训练样本的数量和多样性以及训练的次数,让网络更好地学习到车辆的特征;(本次实验的样本单一,且数量较少,以及只有100次的迭代次数,loss较高)
2.CNN网络改为AlexNet、VGG16或者其他泛化能力更好的结构,提高识别率;(显卡性能太低,无法使用更好的网络结构)
3.训练样本的选择优先选择车辆数量较少的图像且单独不密集;(在图片训练的过程中,选择PositiveOverlapRange,NegativeOverlapRange两个参数的值获得正训练样本和负训练样本。如果车辆较密集且遮挡物较多,做标注的时候很难将所有车辆标注出来,很容易在训练时将车辆的部分当成负样本处理,同时在检测的时候也会将多个车辆用一个框标出来)
4.尽量不要选取远处车辆作为label;(由于远处的车辆目标较小,导致特征少,在检测的时候很容易混淆一些小物体和车辆)
个人理解:RCNN的优点在于使用了CNN对目标进行识别,近几年来证明CNN的识别效率高于其他传统算法;而缺点就是对于候选框的搜索还是用的前几年的传统方法,在时间效率上虽然高于传统方法DPM,但是对于实时检测还是略显不足。后来的YOLO弥补了这方面的缺点,直接使用CNN预测检测框,不再proposal,大大缩短了检测时间。
特别说明:本文为本人学习所做笔记。
具体参考:http://blog.csdn.net/Mr_Curry/article/details/53286562















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









