







本期实习最后做的一件事情,就是整理好几个文本读取的API。依稀记得几个接口 ReadFileToBuf, ReadUtf8FileToBuf, ReadAnsiFileToBuf。之间写读取ini文本的接口的时候,是使用了std::wfstream以及getline来读取Unicode文本,不过这里C++自动跳过文件头,这个std::codecvt_utf16也是个神奇的东西:
std::wifstream wFileStream(pFilePath, std::ios::binary);
if (wFileStream.is_open())
{
wchar_t buf[2] = {0};
wFileStream.read(buf, 2);
wFileStream.clear();
wFileStream.seekg(0, ios::beg);
bool isUnicode = (buf[0] == wchar_t(0xFF) && buf[1] == wchar_t(0xFE)) || (buf[0] == wchar_t(0xFE) && buf[1] == wchar_t(0xFF)) ;
assert(isUnicode == true);
// apply BOM-sensitive UTF-16 facet
wFileStream.imbue(std::locale(wFileStream.getloc(), new std::codecvt_utf16 < wchar_t, 0x10ffff, std::consume_header >));//第二个参数是此平面将读或写而不出错的wchar_t最大值
std::wstring wLine;
while (std::getline(wFileStream, wLine)) .....因为我们的字符串本来就是Unicode字符串,所以读取文本的内容,直接放到wfstream里面也是理所当然的。
那么,如果是UTF8文本呢,如何处理呢?不妨先从简单的开始,ANSI文本如何读取呢?
好像很简单的呀。传统的文本读取都是读取ANSI文本呀。
直接用一个std::ifstream, 调用read传到一个char*——像二进制读取一般即可!这个char* 就存储了整个文本文件的内容啦。
那么读取UTF8文件呢,一个方法就是像读取ANSI文本那样,全部存储到一个char*中,不过这里要先去除掉文件头的标志。那么也像二进制流一样读取到一个buffer中,随后调用MultiByteToWideChar的windows API函数,最后存储到Unicode字符串里面种,我们就可以正常使用文本的内容。
涉及到文本编码的问题,这里简单地总结一下:
最简单的ANSI文本使用ASCII编码,一个字节代表一个字符,8位其实只用了7位,范围是0~127,对应的字符可以查看ASCII标准表
windows的宽字符所用的Unicode,也就是UTF-16,顾名思义,使用16个位(也就是wchar, 2个字节)来代表一个字符,它基本可以囊括世界上所有的符号,优点就是规则整齐,缺点就是占用的空间比较大。如果我的字符串里面只有英文,那么用ANSI可以省下一半的空间。
UTF-8是使用变长编码,在英文之后,它的编码和ASCII是一样的。但是其余的符号则不是,有些字符可能使用8位,而其他字符可能是其他的位数(这也是本人不太熟悉的编码)
| 编码的16进制例子 | ASCII | UTF8 | Unicode |
| a | 61 | 61 | 61 |
| b | 62 | 62 | 62 |
| c | 63 | 63 | 63 |
| 我 | - | E68891 | 6211 |
| 来 | - | E69DA5 | 6765 |
| 了 | - | E4BA86 | 4e86 |
还有一个比较困惑问题就是二进制流读取了。在读取字符串的时候,如果遇到了‘\0’(不是'0','0'的ASCII十进制是48,二进制是0011 0000,‘\0’的二进制是 0000 0000)就认为到了结尾。如果是二进制流读取呢,不管遇到了什么,反正一样读,在二进制的世界里,是不会理会这个符号代表什么意思的,它所做的就只有读取一个又一个字节,不管它是啥,直到读取完最后一个字节为止。
那么问题来了——我们读取文本的时候,如果文本中间有一个'\0'字符(当然,我也不知道是否可以存在这种情况)。诸如ifstream之类的流的Read函数会如何操作呢?(这就是涉及到我们文本读取Read函数是不是读取二进制的操作呢?)
于是,我去写了一个简单的测试代码:
ofstream ofs("file.txt");
char szTemp1[100] = "abcde\0fghijk"; //中间有一个'\0'
ofs.write(szTemp1, 100); //写入100个字节,那么文本中间就有一个'\0'
ofs.close();
char szTemp2[100] = { 0 };
ifstream ifs;
ifs.open("file.txt");
int nLen = 0;
if (ifs.is_open())
{
ifs.seekg(0, ios::end);
nLen = static_cast<int>(ifs.tellg()); //得到文本大小
ifs.seekg(0, ios::beg);
ifs.read(szTemp2, nLen); //szTemp2是"abcde\0efghijk00000....000",但是到\0会截断,只能显示'abcde'
string str = szTemp2; //'abcde'
ifs.close();
}文本写入读取操作是按照二进制读取的,不管遇到到什么内容,即使是'\0',它都不管,照做!在以上示例代码进去写文本操作后,文本如下:
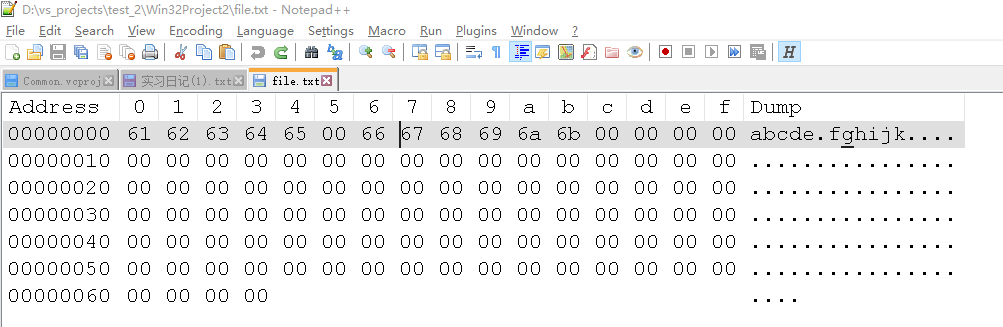
读取的时候先获取文件的大小,然后把整个文件都读进char数组里,char数组里一样存储了fghijk,只不过被中间的'\0'截断了,通过vs的调试模式就可以很清楚地直到这一点。















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









