







Pyraformer: Low-Complexity Pyramidal Attention for Long-Range T-S Modeling and Forecasting
低复杂度的金字塔型注意力模型,用于长时序列建模和预测
我们研究的时空数据类任务(预测或异常检测等),需要考虑时间和空间两个维度。目前的研究成果在空间维度基本是以图卷积为主导,不同之处在于不同工作中定义的图类型有所不同,一般是静态图(即地理位置形成的天然拓扑图),还有结合时间或POI等额外信息计算得到的节点拓扑关系,一般称为动态图。在时间维度,其中的多尺度特征和长期预测也是大家都在探索的点。多尺度,在于不同周期范围序列表现出来的不同的规律性。长期预测,是因为从更长的序列中可以得到更加准确的预测结果。时序预测任务是一个古老的且独立的任务,在做时空任务研究的过程中,对一般的序列任务的特征与建模需要熟悉,这个就是我分享本文的原因。这里要分享的论文是ICLR 2022接收为Oral Presentations的一篇文章,这篇文章在Transformer的基础上,设计了一个低复杂度的金字塔注意机制,用于长时间序列数据的建模与预测。
有问题导向型的阅读论文,如下是我的几个问题:
- 时序预测任务的挑战:长时依赖问题(what)【记忆】
- 原本的Transformer是如何解决的长时问题?存在怎样的缺陷?(how)【复杂度过高】
- 本文在Transformer的基础上做了什么改进?有什么效果?
- 数据集是什么样的?模型输入输出以及内部结构如何?
时间序列预测是很多下游问题的基石,
重点在于短期预测和长期预测;
难点在长期预测;
为了有效长期预测,需要增加序列长度;
从而,需要降低时间和空间复杂度;
目前方法,CNN RNN former变体都无法实现保持较低复杂度的同时获取长期依赖;
长期依赖与最长信号遍历路径相关,因此需要使长度降低;
本文设计的模型就是可以实现获取长期依赖的同时,降低复杂度;
文中有PAM以及一堆定义,两个定理的推导;
CSCM构建C叉树。
本文的模型主体架构:将多层时序构造成金字塔结构,降低了节点之间相似度计算的次数,从而降低复杂度;也正因为金字塔结构使得长期历史时序的任意两个节点之间的信号传递距离在常数级别,保证了获取长期依赖的有效性。下面详细介绍本文的工作。
时间序列预测往往是基于历史时间序列数据对未来(的某个时刻或多个时刻的状态)进行预测(的过程),这个任务是至关重要的。并且我们在做的时空序列预测中,充分做好时间维度特征获取是非常重要的一步。
时间序列数据通常在短期和长期都表现出一定的变化模式,或者是周期性、变化规律等。在预测过程中,能够同时捕获不同范围的时间依赖关系是准确预测的关键。当前大多数时序模型对于短期依赖的获取已经比较成熟,但是处理长期时间依赖会比较困难一些。
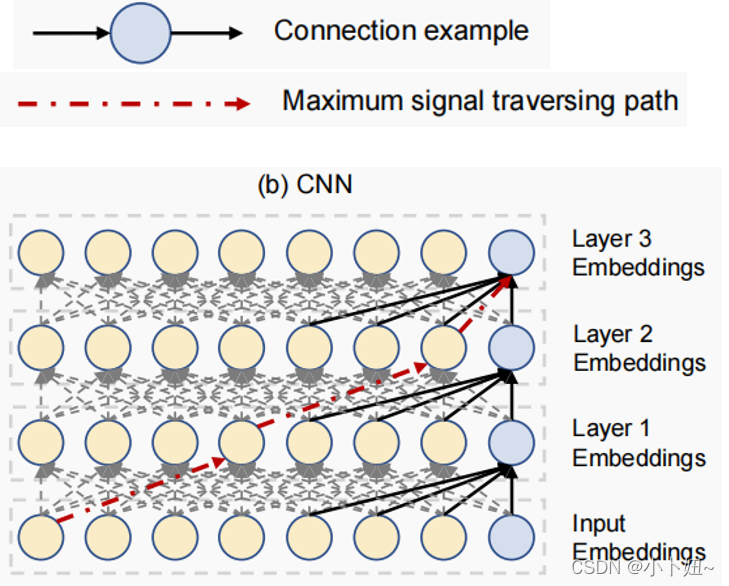
上图显示的是一个经典的CNN模型,当使用CNN模型获取长期依赖特征时,往往需要堆叠多层卷积层用于获取远距离时间节点的特征关系。因此长期依赖特征的获取范围与堆叠的层数相关,当需要获取比较长期的节点之间依赖关系,必然就会产生很大的计算复杂度。
本文提到一个最大信号遍历/传递路径的概念,将历史序列的时间戳(对应的信息)看作一个节点,在提取多节点之间关系的过程中构成图结构(也就是当需要获取较远节点之间关系时进行的信号传递过程),图中任意两个节点之间的连接的最短距离就是信号遍历路径的长度。那么在整个图中 ,最长遍历路径自然是序列的最左端节点和最右端节点之间的路径,距离最长。以右图为例,CNN的典型特点是卷积核,关注周边相邻几个节点的信息,(如果需要获得最左端节点到最右端节点之间的长时依赖特征时,就需要堆叠四层卷积层,那么)如图中所示,序列长度为8,卷积核的kernel_Size为4,那么该图的最长信号遍历路径长度为3(信号的传递每次只能传递一阶邻居,因此最长距离需要传递3次)CNN的路径长度与序列长度L线性相关。(由于kernel的size、stride等在训练过程中一般是固定的,当需要获得更长期序列的特征时,那么最长信号传递路径的长度就和序列长度呈线性相关)
那么这个信号传递路径有什么用呢?本文提出这个概念是为了衡量一个模型处理长期依赖的容易程度。当我们想要获取更远距离的时间依赖的,信号传递路径长度越短,远距离节点的依赖关系就容易捕获。为了使模型可以学习到序列长期依赖,我们对模型的输入,即历史序列长度,需要越长越好。如果使用一般的模型,这就会导致计算复杂度的剧增,因此,在捕获长期依赖关系的同时,降低时间复杂度和空间复杂度是比较重要的。而目前的模型无法同时满足这两个条件。
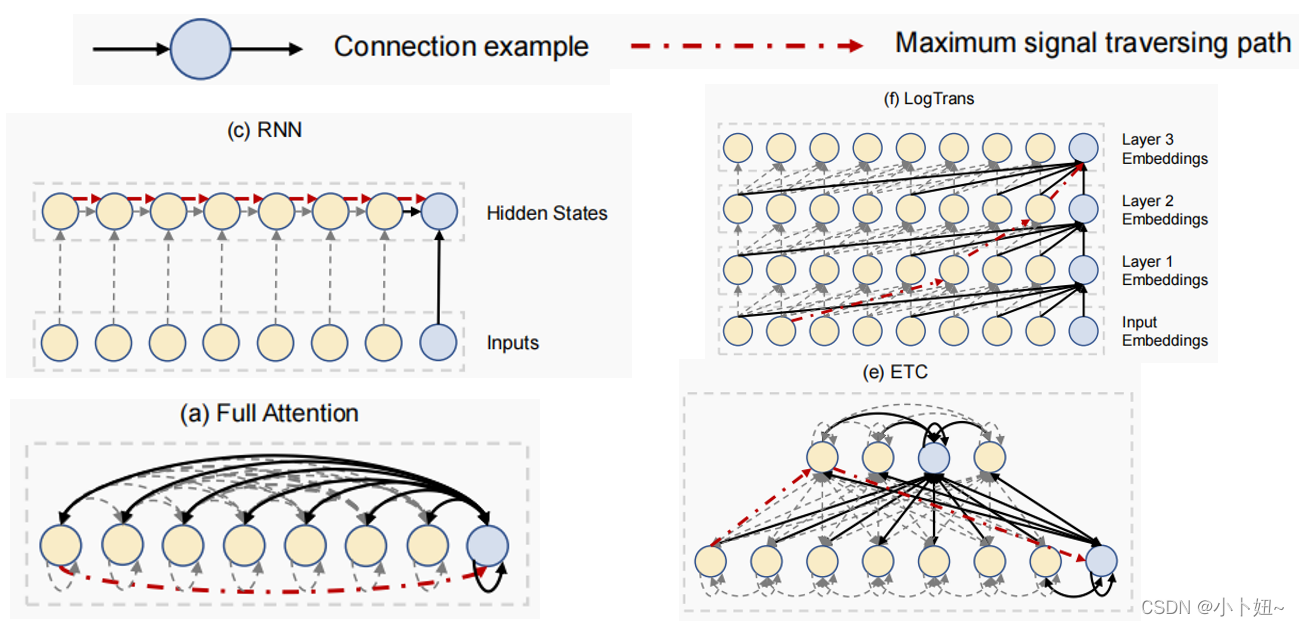
然后这里是其他几个模型的信号传递图。一类是CNN或RNN模型,这两个模型每一层的计算复杂度与L线性相关,是比较低的。而对于长期依赖的获取,这两个模型的最长信号传播路径同样与序列长度L呈线性相关,因此对于学习遥远的位置之间的依赖关系仍然是存在困难的。
RNN模型是串行执行的,接收当前时刻输入和上一时刻的隐态,逐个处理每一个时刻的信息,汇聚到最后一个节点。这个模型的最长信号传播路径等于序列长度L。
近几年,Transformer在许多NLP任务中取得了非常优秀的效果,因此许多研究者将其引入时间序列领域中,通过Transformer的自注意力机制捕捉长期依赖,尤其是对于较长时间序列数据的特征提取有非常优异的效果。
相比于CNNRNN,Transformer可以有效地捕获时序的长期依赖性,如图a所示,即Transformer的自注意力机制,在任意时间节点之间都有信息传递,他将将最大路径降低为O(1),因此可以处理很长节点间关系。但牺牲了增加到O(L2)的时间复杂度。因此,它不能处理很长的序列。为了降低计算压力,找到复杂度和预测长度之间的折衷,近些年提出了许多transformer变体。
19年的LogTrans提出将序列中的每个点限制在该点之前 2 n 2^n 2n步内,因此该模型对应的最长路径长度为对数级别的,每一层复杂度也由原来的L方降低为LlogL;
20年的ETC模型为了获取全局信息,引入了一组额外的全局标记,导致O(GL)时间和空间复杂度和O(1)最大路径长度,其中G是全局标记的数量。然而,G通常随L的增加而增加,因此的复杂性仍然是超线性的。
21年的Informer利用注意力分数的稀疏性,将复杂度降低到O(LlogL),其代价是节点路径长度比一般Transformer要高。
20年的LongFormer在局部滑动窗口或扩张滑动窗口间计算注意力,复杂度降低到O(AL),A是局部窗口的长度,而这个局部窗口也限制了获取全局信息。因此该模型的最大路径长度是O(L/A)。作为一种替代方案,
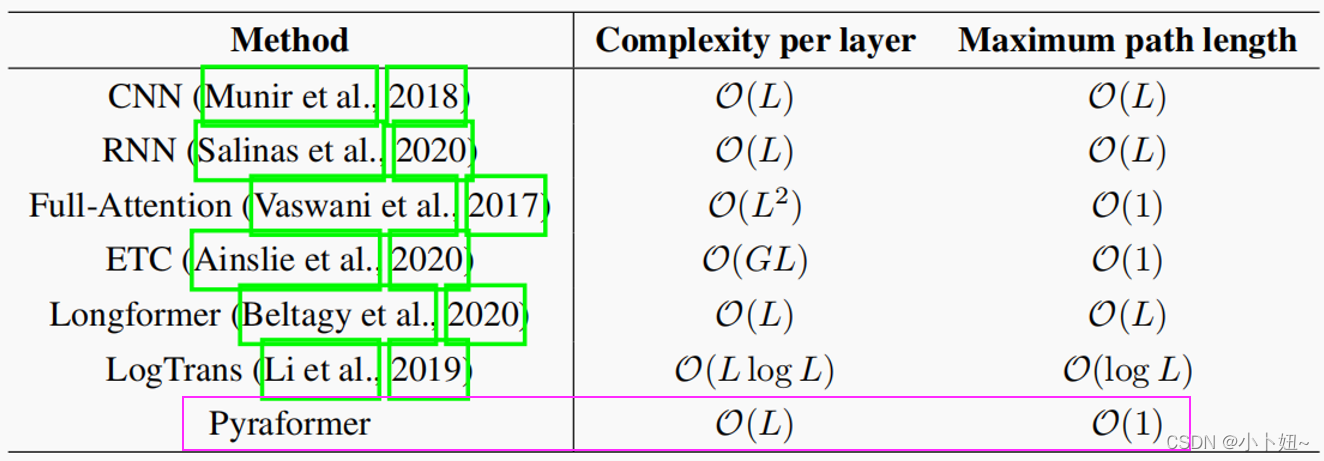
这个表为各个模型捕获时序依赖特征时,每一层的复杂度和路径长度。可以看到,这些方法的最大路径长度几乎没有低于O(L)的,也没有过多降低时间、空间的复杂度。本文提出的pyraformer可以将复杂度保持在线性级别,同时保持路径长度为常数级别。
定义
时序预测问题可以形式化表示为:给定历史L步观测信息和相关协变量信息(自己手动从数据获取的特征,如一天中的第几个小时等),用于预测未来M步的过程。
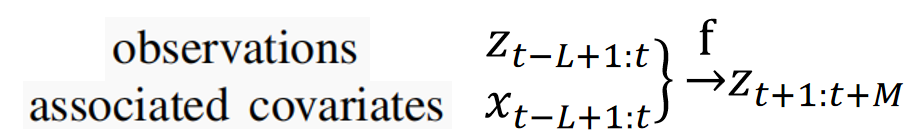
整体框架
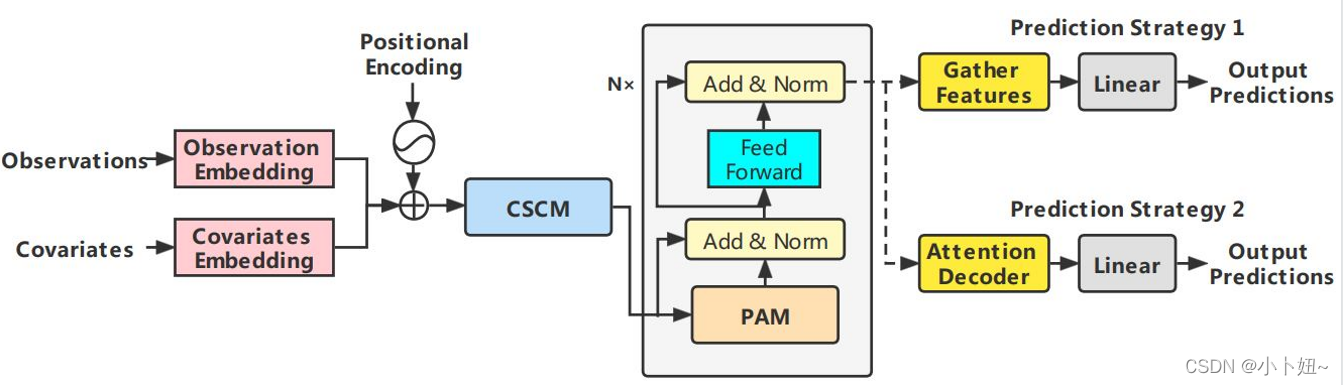
本文提出的pyraformer整体结构如图所示。首先将观测数据、协变量和位置信息分别嵌入并叠加在一起,然后通过CSCM模块构建一个多尺度/粒度C叉树,(原始时间序列节点可以看成细粒度的)降细尺度的C个节点信息的聚合得到粗尺度节点。为了进一步捕获不同范围的时间依赖,引入金字塔注意力模型PAM,使用金字塔状图结构用于注意力信息传递。最后,基于下游任务,采用不同的网络结构得到最后的预测输出。
CSCM
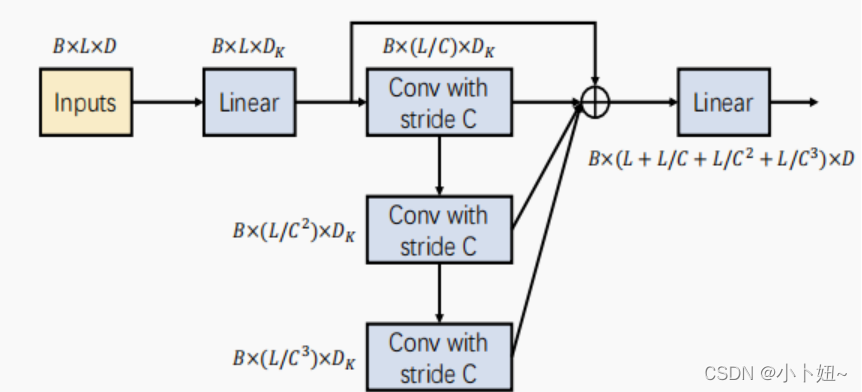
CSCM的目标是在金字塔图的较粗的尺度上初始化节点,以便于后续的PAM在这些节点之间交换信息。具体来说,通过对相应的子节点C(s)ℓ进行卷积,从下到上引入粗尺度节点。
如图所示,将核大小为C和步幅为C的卷积层依次应用于嵌入序列,在s尺度上得到长度为L/Cs的序列。不同尺度的序列形成c-ary树(如下图)。在将这些细到粗的序列输入到PAM之前,我们将它们连接起来。为了减少参数和计算的数量,我们在将序列输入到堆叠卷积层之前,通过一个全连接层将每个节点的维数降低,并在所有卷积后恢复。这种瓶颈结构大大减少了模块中的参数数量,并可以防止过拟合。

金字塔注意力
pyraformer类似于ETC,所提出的金字塔也引入了全局标记,但以多尺度的方式,成功地降低了复杂性到O(L),而不像原始变压器以增加最大路径长度的阶数为代价。
pyraformer的核心是PAM,如图 2 所示,利用金字塔图以多分辨率方式描述观察到的时间序列的时间依赖性。我们可以将金字塔图分解为两部分:尺度间和尺度内连接。跨尺度连接形成一个 C 叉树,其中每个父节点都有 C 个子节点。例如,如果我们将金字塔图的最细尺度与原始时间序列的每小时观测值相关联,则可以更粗尺度的节点就可以被视为时间序列的每日、每周甚至每月特征。因此,金字塔图提供了原始时间序列的多分辨率表示。此外,在更粗的尺度内连接相邻节点,更容易捕获长期依赖关系。换句话说,较粗的尺度有助于描述长期相关性,这在图形上比仅用单一的、最细粒度的模型捕获要简洁得多。确实,原始的单尺度Transformer(见图1(a))采用了一个完整的图,以最细的尺度连接每两个节点,从而建模长期依赖,产生一个具有O(L2)时间和空间复杂度的计算繁重的模型。与之形成鲜明对比的是,如下图所示,所提出的金字塔图在不增加信号传递路径长度的情况下,将计算成本降低到O(L)。
原始transformer注意力计算:
在深入研究PAM之前,首先介绍一下原始的注意机制。设X和Y分别表示单头注意力的输入和输出。可以引入多个头部来从不同的角度来描述时间模式。输入X,首先线性转换为三个不同的矩阵,即Q=XWQ、键K=XWK和值V=XWV,其中WQ、WK、WV∈RL×DK。对于Q中的第i行qi,它可以处理k中的任意行(即键)。换句话说,相应的输出yi可以表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









