







离线与实时的区别并不是快慢
大数据的应用场景一般分为离线处理场景和实时处理场景。这个放在传统开发这里也成立,都是一样的。
大家对离线和实时这两种计算场景,有什么想法没有?
大家第一印象可能觉得,离线处理场景比较慢,实时处理场景相对快一些,比较及时能够得到处理的一个结果。
但本质上其实不是这样去区分离线和实时的。实际上,数据量小的情况下,离线处理也可以很快;数据量大的情况下,实时处理也可能很慢。
离线和实时它本质的区别是在于,它处理的数据是有界数据还是无界数据。
究竟什么是离线处理场景?
比方说我们以离线处理场景为例,数据从数据源产生以后,我们先给它存起来。你不管存到哪个地方,假设保存的数据是10个GB,这10个GB的数据在后续的运算过程中它是不会增加或者减少的。它就是固定10个GB。
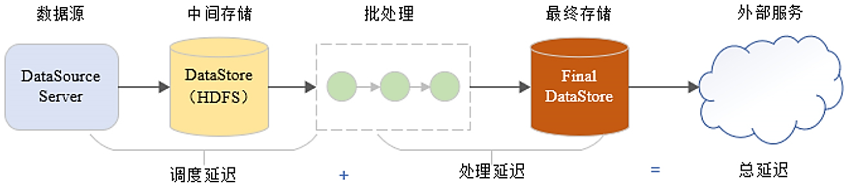
我们基于这10个GB的数据,进行运算,这个时候完成的运算就是离线运算。离线运算最适合批处理这种方式来完成。处理完以后得到最终结果后进行输出,做一个保存。
以批处理程序它的视角来看,我们处理的数据它是存起来的数据集,它是有边界的数据。存起来是10个G,处理的时候也是10个G,它不会增加和减少。
当然离线有另外一层含义,就是说数据存起来以后可以直接断网。即使网络中断也能完成这部分数据的处理。
什么是实时处理场景?
实时处理场景则不太一样,数据从数据源产生后,它就立马交给流处理任务去处理。计算任务可以是Java写的,也可以是Python写的,不管是哪种流处理计算任务,它都需要7*24小时不中断运行,才能保证数据的及时处理。
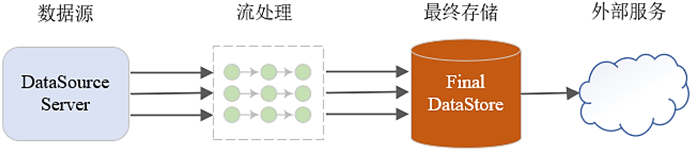
处理得到的结果,可以实时进行存储与更新,从而让外部的服务去做实时的调用与展示。
因为数据源的数据是实时产生的,所以在流处理任务的它的视角来看,这个数据是有界的还是无界的?它一定是没有边界的。它实时在产生,好像没有边界,一直在流动过来。
处理这种无界的数据,我们称为实时处理。
数据处理的两种方式:批处理与流处理
处理这种实时数据的时候,我们一般会采用流处理的这种方式。所以有时候提到离线批处理和实时流处理,它是放在一起说的。离线场景适合批处理运算,实时场景适合流处理运算。
那批处理运算,它其实是把这个数据拿到之后,先让整体数据通过第一个阶段的处理,得到最终的结果以后再送往下一个阶段处理。
也就意味着说批处理方式,在任意一个时间点去观察的时候,可以发现所有的数据一定是同时处在某一个阶段。
对于流处理方式不一样,流处理方式是怎么样的呢?
流处理方式就和流水线的工人一样,第一个工人负责第一个阶段,第二个负责第二个阶段,以此类推。
它们在等待数据传输过来,数据过来之后,就开始处理,处理完成后立马将处理结果送给下一个阶段。然后继续等待新的数据传输进来。
有数据之后就处理,处理完以后交给下一个阶段。每个阶段都是这样的。
流处理这种方式,你在任意一个时间去观察的时候,可能会发现多个阶段都会有数据存在。这是它们的不同之处。
小结:离线批处理与实时流处理的区分
离线批处理和实时流处理,这个概念大家一定要区分明白。离线处理和实时处理,主要是针对于数据是有界是否有界。有界就是离线处理,无界就是实时处理。
离线的数据,它适合批处理这种处理方式去做计算。实时数据它适合流处理这种方式。
典型的离线批处理场景有数据仓库、搜索与检索、图计算、数据分析,这些都属于离线场景。
实时处理场景的话,有实时数仓、实时数据分析、流上机器学习等,所有需要实时处理的任务都属于这个场景。
OK,这一节就和大家聊到这里,配套的视频合集,可以在B站【数舟】中观看。传送门:如何区分大数据离线与实时场景
















 1777
1777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











