









题
编写程序,能够把如下程序中的词法单元都识别出来
int asd = 0;
int bc = 10;
while ( asd < bc)
{
if(bc - asd < 2)
printf("they are close.");
asd = asd + 1;
}
代码
import ply.lex as lex
# C语言保留字
reserved = {
'if' : 'IF',
'then' : 'THEN',
'else' : 'ELSE',
'while' : 'WHILE',
'int' : 'INT',
'printf' : 'PRINTF'
}
tokens = ['LPAREN', 'RPAREN', 'DIVIDE', 'TIMES', 'MINUS', 'PLUS', 'NUMBER', 'FENHAO', 'DENGHAO', 'XIAOYU', 'DAYU', 'ZUODAKUOHAO', 'YOUDAKUOHAO', 'YINHAO', 'DIANHAO', 'ID'] + list(reserved.values())
# ID规则
def t_ID(t):
r'[a-zA-Z_][a-zA-Z_0-9]*'
t.type = reserved.get(t.value,'ID') # Check for reserved words
return t
# 规则
t_PLUS = r'\+'
t_MINUS = r'-'
t_TIMES = r'\*'
t_DIVIDE = r'/'
t_LPAREN = r'\('
t_RPAREN = r'\)'
t_FENHAO = r';'
t_DENGHAO = r'='
t_XIAOYU = r'<'
t_DAYU = r'>'
t_ZUODAKUOHAO = r'{'
t_YOUDAKUOHAO = r'}'
t_YINHAO = r'"'
t_DIANHAO = r'\.'
# 规则
def t_NUMBER(t):
# 识别数字
r'\d+'
t.value = int(t.value)
return t
# 对于空行的规则
def t_newline(t):
r'\n+'
t.lexer.lineno += len(t.value)
# 忽略空格
t_ignore = ' \t'
# 输出错误的规则
def t_error(t):
print ("Illegal character '%s'" % t.value[0])
t.lexer.skip(1)
# Build the lexer
lexer = lex.lex()
# 测试数据
data = '''
int asd = 0;
int bc = 10;
while ( asd < bc)
{
if(bc - asd < 2)
printf("they are close.");
asd = asd + 1;
}
'''
lexer.input(data)
while True:
tok = lexer.token()
if not tok: break
print (tok)
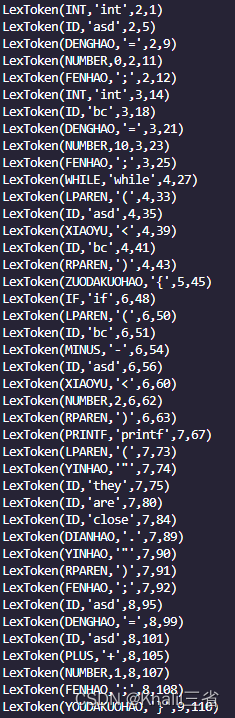
结果
新手上路,有错请指正。
















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











