







摘要:总结一些经典的NLP面试题 ,会陆续更新。
如果有谬误,欢迎批评指正~
:)笔者明天就有一个面试,然而觉得自己还是一个NLP小白,所以今天加急整理一下知识点。
Q为面试管 A为面试者 模拟面试
word2vec
Q: word2vec有两种经典的训练方式
A: skip-gram 和 CBOW
Q: 介绍一下这两种训练方式
A: skip-gram:给定中心词预测上下文, (in, out)对形式为 若干个 中心词与上文下文词组成的词对;

CBOW:给定上下文,预测中心词,(in, out)形式为 (上下文词组成的列表,中心词)
Q: skip-gram 与 CBOW的优缺点比较
A: skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
但是在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。
cbow预测行为的次数跟整个文本的词数几乎是相等的(每次预测行为才会进行一次backpropgation, 而往往这也是最耗时的部分),复杂度大概是O(V);
在计算时,cbow会将context word 加起来, 在遇到生僻词是,预测效果将会大大降低。skip-gram则会预测生僻字的使用环境
| skip-gram | CBOW | |
|---|---|---|
| 单词训练输入 | 一个中心词 | 多个上下文 |
| 单词训练标签 | 一个上下文 | 一个中心词 |
| 训练复杂度 | 高 | 低 |
| 训练时间 | 长 | 短 |
| 训练效果 | 好 | 稍差 |
| 生僻词 | 好 | 稍差 |
Q: 加速训练的方式
A: 负采样, 层次化softmax
LSTM
RNN公式(摘自https://zhuanlan.zhihu.com/p/30844905):

LSTM公式:

Q:LSTM结构
A: 输入门,输出门,遗忘门
Q: RNN有什么优缺点?LSTM会梯度消失和爆炸吗?
A: RNN,循环神经网络。
优点:适用于时间序列预测问题。(因为这一时刻的状态和输出,除了受输入影响外,还受到上一时刻状态的影响。)
缺点:会发生梯度消失/梯度爆炸问题;无法解决长时间依赖问题
LSTM可以缓解RNN的缺点。
Q: RNN为什么会出现梯度消失/梯度爆炸问题?LSTM怎么缓解梯度消失,梯度爆炸问题?
A: 简单来说,由于链式法则,RNN的损失函数求导式中出现很多tanh’和W连乘。由于tanh’=1-tanh^2 < 1, 当 W < 1时, 损失函数求导式会趋向于0; 而W > 1时,损失函数求导式很大。
LSTM缓解梯度消失:cell state两部分加和更新;门控机制
LSTM缓解梯度爆炸: 设定阈值;使用正则化减少权重;梯度裁剪
Attention
Q: attention是怎么计算的?
A: decoder和encoder隐藏层向量相乘得到alignment vector, 再进行softmax,然后这个结果再和encoder的隐藏层向量相乘得到上下文向量,作为decoder的输入。
Q: 有哪几种attention?特点和区别?
A: 针对decoder和encoder隐藏层向量相乘得到的式子进行不同操作:
Soft-attention: 保留所有分量进行加权
Hard-attention: 以某种策略选取部分,只focus一个位置
Local-attention: 局限在一定的窗口, alignment vector长度可变
Global-attention: alignment vector长度=编码器时间序列长度
Self-attention与一般的attention区别:Attention发生在Target的元素Query和Source中的所有元素之间。举例:机器翻译。Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制。
Q : Self-attention公式
A:
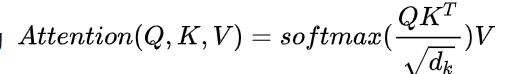
Transformer

机器学习问题
Q: dropout 训练和测试时有什么不同
A: 训练的时候时随机选取一些神经元屏蔽,权重不更新;测试的时候,是所有的神经元都选用,但是输出值乘以(1-丢弃率),使得训练和测试时候输出的均值相同
Q: 过拟合是什么?怎么解决?
A: 过拟合就是模型过度拟合了训练集中的不是很普遍的特征,导致训练loss不断降低,但是验证集的loss升高。
解决方法:正则化;增加数据;batchnormalization;dropout
Q: 正则化有哪几种?区别?
A: L1正则,L2正则。L1正则化是w各个元素绝对值的和,L2正则化是w各个元素平方和开根号。
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,一定程度上,L1也可以防止过拟合
L2正则化可以防止模型过拟合(overfitting),对于大数值的权重向量进行严厉惩罚,倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。
Q: 正则化背后的数学原理?
A: 解空间

左面是L2约束下解空间的图像,右面是L1约束下解空间的图像。黄色图像的边缘与损失函数等值线的交点,便是满足约束条件的损失函数最小化的模型的参数的解。
由于L1正则化约束的解空间是一个菱形,所以等值线与菱形端点相交的概率比与线的中间相交的概率要大很多,端点在坐标轴上,一些参数的取值便为0。L2正则化约束的解空间是圆形,所以等值线与圆的任何部分相交的概率都是一样的,所以也就不会产生稀疏的参数。
Bert
Q: Bert基本介绍 (可能会问Bert的两个基本任务)
A:Bert: 1.使用了Transformer 作为算法的主要框架,Transformer能更彻底的捕捉语句中的双向关系;
2.使用了Mask Language Model(MLM)和 Next Sentence Prediction(NSP) 的多任务训练目标;
3.大规模预料预训练模型
Q: Bert 的 MLM任务介绍
A: 15%的WordPiece Token会被随机Mask掉;在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
Q: Bert的缺点
A: 1.预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;
2.Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









