









文章目录
1、问题分析
1.1 赛题理解
1.2 评价指标
-
本赛题评价指标:
MAE(Mean Absolute Error)平均绝对误差。即绝对误差的平均值:

y i y_i yi:第i个样本实例的真实值
y i ^ \hat{y_i} yi^:第i个样本的预测值
MAE值越小,则模型越准确。 -
MAE由来:衡量回归模型拟合的是否准确,首先会想到取各个点的差值求平均。
-
MAE缺点: 实际拟合时,差值可能有正有负,那么求均值时会相互抵消,导致最终MAE值可能很小,但其实真实值和预测值是有差距的。
且含绝对值的函数,其曲线是不光滑的,在某些点无法求导,也就没法寻找使MAE最小的点。
于是引申出下面几个指标: -
回归模型常用的评价指标:
1、
均方误差MSE(Mean Squared Error)。即误差平方的均值,因为对误差做了平方计算,所以MSE相比于MAE,对异常值更敏感。
MSE缺点:与目标变量的量纲不一致。需要对MSE进行开方。

2、
均方根误差RMSE(Root Mean Squared Error),为MSE的方根。
但RMSE仍然是一个量纲化的指标。
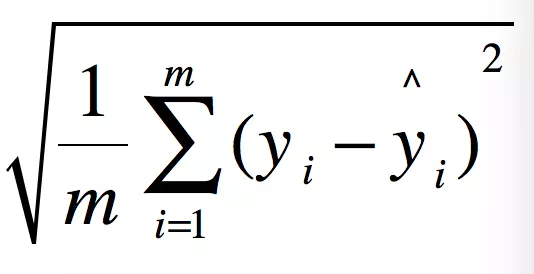
3、
决定系数R-SquaredR 2 R^{2} R2(Coefficient of determination )
如果结果为0,说明模型不能预测因变量(因变量的结果是一个常数)。如果为1则说明是函数关系(预测出的就是真实的函数)。越接近1拟合效果越好。
实践经验:从理论上来说,只要增加特征的个数,R2的值是一直增加的,不管这个特征x和目标y是否有关。因此,R2通常用于特征选择。如果增加一个特征,模型的R2值上升很多,那就说明这个特征和目标有关。
更多参考:https://zhuanlan.zhihu.com/p/36305931
https://www.cnblogs.com/HuZihu/p/10300760.html

2、EDA
2.1 初步特征处理
删除倾斜严重的特征,(倾斜严重的特征含信息量少,对于预测的帮助很小)
# 查看特征的值分布
train_data['seller'].value_counts()
#删除特征,可以用del或drop
del train_data['seller']
del train_data['offerType']
del test_data['seller']
del test_data['offerType']
2.2 标签分布
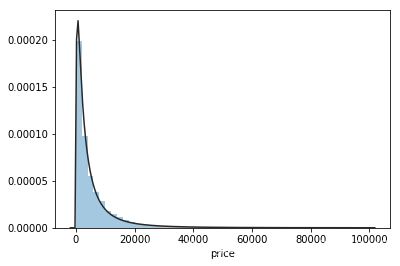
2.2.1 拟合各种分布并作图
# 拟合无界约翰逊分布
import scipy.stats as st
y=train_data['price']
plt.figure(1)
sns.distplot(y,kde=False,fit=st.johnsonsu)
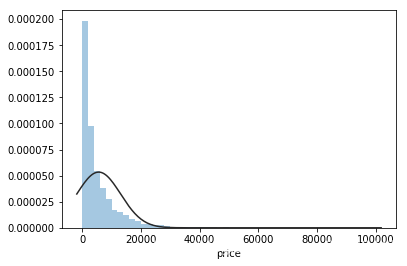
# 拟合正态分布
sns.distplot(y,kde=False,fit=st.norm)
- 为什么在回归前需要看标签符合的分布?
1、能查到的多数回答:因为线性回归的基本假设之一是随机项服从正态分布,进行正态检验就是看数据是否适合做回归。若不服从正态分布,就要考虑使用非线性模型。
2、 进一步查阅:Is Normal Distribution Necessary in Regression? How to track and fix it? 这篇文章中说到,在做回归预测时,需要使其服从正态分布的只是预测误差(prediction error),预测误差即模型真实值和预测值的差值。
当基于5%的显著性水平选择了一些用于预测的特征,如果此时预测误差不服从均值为0的正态分布,那么所选择的特征可能并不是对预测目标真正重要的特征。如果要选择真正重要的特征,需要确保预测误差服从正态分布。
3、判断是否服从正态分布的方法:
①对预测误差分布作图(可以使用sns.displot()方法)肉眼进行判断是否服从正态分布;
②或者直接检查p值(通常在5%的显著性水平下,p值>0.05 就认为服从正态分布。)
③作QQ图,QQ图上的点近似地在一条直线附近就说明是正态分布。直线的斜率为标准差,截距为均值。
4、为何会不服从正态分布?
可能存在少许异常点outliers 或极端值。可以先处理异常点(删除或替换),若还不服从正态分布,可以使用box-cox对不服从正态分布的变量进行抓换。
5、关于自变量(即回归拟合中的特征)是否需要服从特定分布?待解决
scipy.stats模块的常见用法
1、生成服从指定分布的随机数norm.rvs
参数loc、scale分别指定随机变量的偏移和缩放。(在正态分布中偏移和缩放对应的是期望和标准差)。参数size指定得到随机数数组的形状。
2、正态检验、卡方检验、独立分布检验、F分布检验
3、求概率密度函数在指定点的值stats.norm.pdf(α,均值,方差),即已知正态分布曲线和x值,求y值。
4、求累计分布函数在指定点的值stats.norm.cdf(α,均值,方差),即已知正态分布函数的曲线和指定的x值,求函数在x点左侧的积分。
# 示例1-生成服从正态分布的随机数数组
import scipy.stats as st
st.norm.rvs(loc=0,scale=0.1,size=10)
#示例2-正态检验
st.normltest(st.norm.rvs(size=10))
# 示例3-求概率密度函数值
st.norm.pdf(0,loc=0,scale=1)
#示例4-求累计分布函数在指定点的值
st.norm.cdf(0,loc=0,scale=1)
5、常用分布
| 函数名 | 分布 |
|---|---|
| norm | 正态分布 |
| poisson | 泊松分布 |
| uniform | 均匀分布 |
| f | F分布 |
| lognorm | 对数正态分布 |
| t | T分布 |
2.2.2 偏度和峰度
为什么需要看label的偏度和峰度:了解label的分布偏斜情况。
偏度skewness
是描述数据分布形态的统计量,描述的是某总体取值分布的对称性。
1)skewness=0,分布形态与正态分布偏度相同。
2)skewness>0,正偏差数值较大,为正偏或右偏。长尾在右边,数据右端有较多极端值。
3)skewness<0,负偏差数值较大,为负偏或左偏。长尾在左边,数据左端有较多极端值。
4)数值的绝对值越大,表明数据分布越不对称,偏斜程度大。
峰度kurtosis
是描述某变量所有取值分布形态陡缓程度的统计量,即数据分布顶的尖锐程度。
1)Kurtosis=0 与正态分布的陡缓程度相同。
2)Kurtosis>0 比正态分布的高峰更加陡峭——尖顶峰。
3)Kurtosis<0 比正态分布的高峰来得平台——平顶峰。
2.3 数值特征和类别特征
2.3.1 数值型特征分析
相关性分析
-
相关性分析一方面是各特征和label的相关性、另一方面是各数值特征之间的相关性。
-
为什么进行相关性分析?
特征和label的相关性:可以删除和label相关性很低的特征,因为这种特征对于label的影响很小。
特征与特征的相关性:可以通过分析减少冗余特征,相关性高的几个特征,在其中选取若干,其余压缩或删除。起到降维的作用。 -
方法:数值型特征和label的相关性 ,使用
corr()方法;使用sns.heatmap()作出相关性热力图。 -
使用
sns.pairplot()作出特征与特征关系的可视化图。
2.3.2 类别型特征分析
- 处理类别特征常用 独热编码one-hot(但独热编码会造成过多的0,往往采取①转为稀疏向量②用一些降维方法,如PCA降维等)
3、数据处理
异常处理(nσ原则)
- 分位箱线图、3σ原则来判断异常值
- BOX-COX 转换 处理有偏分布
注意:根据使用经验,使用3σ进行异常值筛选时,要首先了解样本的数量级和分布情况,因为对于量级小且分布集中的数据集,3σ可能将正常值判断为异常值。
可以采取n*σ方法,即原3σ方法中的3随着数量级大小而变化。
# 3σ原则判断异常值
# 考虑各特征的数量级不一,采用nσ方式判断异常值
import numpy as np
import pandas as pd
class ThreeSigma:
def __init__(self, set):
self.set = set
def sigma_params(self):
mean = np.array(self.set).mean()
std = np.array(self.set).std()
return mean, std
def three_sigma_detect(set):
sigma_model = ThreeSigma(set)
mean, std=sigma_model.sigma_params()
abnormal_list=[]
for i in set:
if 0 <= mean < 1000:
n = 6 if 0 <= mean < 100 else 5
else:
n = 3
result = np.abs(i - mean) - n * std
if result > 0:
abnormal_list.append(i)
return abnormal_list
#计算power特征的nσ异常值判断结果
print('数值特征{},3sigma异常值列表{},异常值数量{}'.format(numeric_features[0],three_sigma_detect(train_data[numeric_features[0]]),
len(three_sigma_detect(train_data[numeric_features[0]]))))
#查看所有数值特征的nσ异常判断结果
for f in numeric_features:
print('数值特征{},异常值数量{}'.format(f,
len(three_sigma_detect(train_data[f]))))
# 共25w条训练数据
# 根据各数值特征的异常值数量结果,可将power、v_6两个特征的异常值进行清洗
数据分桶
- 为什么做数据分桶?
1)分桶后,对异常数据有很强的鲁棒性。
2)逻辑回归模型中,单变量离散化为N个哑变量后,每个哑变量有单独的权重,相当于为模型引入了非线性,使模型更好地拟合数据。
3)分箱后降低模型运算复杂度,提升模型运算速度,利于后期生产上线。
-
分桶方法分为无监督分桶和有监督分桶。
1)无监督分桶:等频分桶、等距分桶和聚类分桶。
2) 有监督分桶:best-ks分桶和卡方分桶。 -
Pandas 实现连续数据的离散化处理主要基于两个函数:
pandas.cut:根据指定分界点对连续数据进行分箱处理
pandas.qcut:根据指定箱子的数量对连续数据进行等宽分箱处理
4、特征工程
4.1 特征构造
4.2 特征筛选
使用corr()方法,计算特征与特征的相关系数,可以通过分析减少冗余特征,相关性高的几个特征,在其中选取若干,其余压缩或删除。起到降维的作用。
4.3 降维
对类别型特征做one-hot编码后,如果特征值很多,会造成过多的0,往往采取 ①转为稀疏向量;②用一些降维方法,如PCA降维等)
-
主成分分析可以在训练集中识别出哪条轴对差异性的贡献度最高。
-
对于每个主要成分,PCA都找到一个指向PC方向的零中心单位向量。
由于两个相对的单位向量位于同一轴上,因此PCA返回的单位向量的方向不稳定,如果稍微扰动训练集并再次运行PCA,则单位向量可能会指向原始向量的相反方向。但是,它们通常仍位于相同的轴上,它们定义的平面通常保持不变。 -
如何找到主成分?
称作奇异值分解(SVD)的标准矩阵分解技术,该技术可以将训练集矩阵X分解为三个矩阵 的矩阵乘法,其中V包含定义所有主要成分的单位向量。
的矩阵乘法,其中V包含定义所有主要成分的单位向量。














 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









