





量子神经网络
概述
整部笔记描述了qiskit-machine-learning包中提供的的不同量子神经网络(quantum neural network, QNN)实现,以及它们如何被整合到基础量子机器学习(quantum machine learning, QML)工作流中.
整部笔记结构如下:
- 简介
- 如何例示QNN
- 如何运行正向传递(forward pass)
- 如何运行反向传播(backward pass)
- 高阶功能
- 结论
简介
量子神经网络 vs. 经典神经网络
经典神经网络是一种算法模型,其受到人脑结构的启发,可以在训练后用于识别图式(pattern)并学习解决复杂问题.它们基于一系列相互连接的节点或神经元(neurons),由一种层状结构组织起来,其中还有若干参数用于模型的学习(通过应用机器学习和深度学习策略).
量子机器学习(QML)的动机是将量子计算的记号和经典机器学习整合到一起,以此开辟一条通向崭新且进步的学习模式.QNN通过结合传统神经网络和参数化量子电路来实现这一普适性原理.因为二者处在两个领域的交集,QNN可以从两个观点来看待:
-
立足机器学习观点,我们不厌其烦地指出,QNN如同经典神经网络,是可以被训练用于寻找相似行为数据中隐藏图式的算法模型.这些模型可以将传统数据(输入)加载为量子态,而后通过借助可训练权重(trainable weights)参数化的量子门对其进行处理.图1展示了一个包含了数据载入和处理步骤的普适性QNN例子.测量的输出结果可以被插入到损失函数中通过反向传播(backpropagation)去训练权重.
-
立足量子计算观点,QNN是基于参数化量子电路的量子算法,可以通过经典优化器在可变化的行为中进行训练.这些电路包含带有输入参数的特征映射(feature map)和带有可训练权重的拟设(ansatz),就像我们在图1中看到的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rz3oqdJS-1680164448545)(1.png)]
正如你所看到的,这两种观点是互补的,并不一定依赖于诸如“量子神经元”或构成QNN“层”概念的严格定义.
qiskit-machine-learning中的实现
qiskit-machine-learning中的QNN是与应用程序无关的计算单元,可以用于不同的用例,它们的设置将取决于需要它们的应用程序.该模块包含一个用于QNN的接口和两个特定的实现:
-
神经网络(NeuralNetwork):神经网络的接口.这是所以QNN用以继承的抽象类(abstract class).
-
估计器QNN(EstimatorQNN):一个基于量子力学观测量取值的网络.
-
样本器QNN(SamplerQNN):一个基于测量量子电路返回样本的网络.
这些实现基于qiskit原类(qsikit primitives).原类是在模拟器或真正的量子硬件上运行QNN的入口点.每个实现,EstimatorQNN和SamplerQNN,都接受其对应原类的一个可选实例,该原类可以分别是BaseEstimator和BaseSampler的任何子类.
qiskit-primitive模块为Sampler和Estimator类提供了运行状态向量模拟的参考实现.默认情况下,如果没有实例传递给一个QNN类,相应的引用原类(Sampler或Estimator)的实例将由网络自动创建.有关原语的更多信息,请参阅原类文档.
NeuralNetwork类是qiskit-machine-learning中可用的所有QNN的接口.它公开了一个向前和向后传递,将数据样本和可训练权重作为输入.
需要注意的是,神经网络是“无状态的”.它们不包含任何训练功能(这些功能被推到实际的算法或应用程序中:分类器、回归器等),也不存储可训练权重的值.
现在让我们看看两个NeuralNetwork实现的具体示例.但首先,让我们设置算法种子,以确保结果在运行之间不会改变.
from qiskit.utils import algorithm_globals
algorithm_globals.random_seed = 42
QNN演示
EstimatorQNN
EstimatorQNN采用参数化量子电路作为输入,以及可选的量子力学可观测值,并输出正向传递的期望值计算.EstimatorQNN还接受可观测值列表来构建更复杂的QNN.
让我们通过一个简单的例子来看看EstimatorQNN的实际应用.我们从构造参数化电路开始.这个量子电路有两个参数,一个表示QNN输入,另一个表示可训练权重:
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit
params1 = [Parameter("input1"), Parameter("weight1")]
qc1 = QuantumCircuit(1)
qc1.h(0)
qc1.ry(params1[0], 0)
qc1.rx(params1[1], 0)
qc1.draw("mpl")
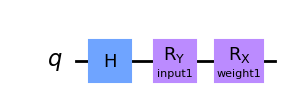
现在我们可以创建一个可观察对象来定义期望值的计算.如果没有设置,那么EstimatorQNN将自动创建默认的可观测量 Z ⊗ n Z^{\otimes n} Z⊗n.在这里, n n n是量子电路的量子比特数.
在本例中,我们将更改内容并使用
可观测量
Y
⊗
n
Y^{\otimes n}
Y⊗n:
from qiskit.quantum_info import SparsePauliOp
observable1 = SparsePauliOp.from_list([("Y" * qc1.num_qubits, 1)])
加上上面定义的量子电路,以及我们创建的可观察量,EstimatorQNN构造函数接受以下关键字参数:
- estimator: 可选的原类实例
- input_params: 被当作“网络输入”的量子电路参数列表
- weight_params: 被当作“网络权重”的量子电路参数列表
在这个例子中,我们之前确定params1的第一个参数应该作为输入,而第二个参数应该作为权重.由于我们正在进行本地状态向量模拟,因此我们不会设置估计器参数.网络将为我们创建一个 Estimator原类实例的引用.如果我们需要访问云资源或Aer模拟器,则必须定义各自的估计器实例并将它们传递给EstimatorQNN.
from qiskit_machine_learning.neural_networks import EstimatorQNN
estimator_qnn = EstimatorQNN(
circuit=qc1, observables=observable1, input_params=[params1[0]], weight_params=[params1[1]]
)
estimator_qnn
我们将在以下几节中看到如何使用QNN,但在此之前,让我们先看看SamplerQNN类.
SamplerQNN
SamplerQNN以类似于EstimatorQNN的方式实例化,但由于它直接从测量量子电路中消耗样本,因此不需要自定义可观测量.
默认情况下,这些输出样本被解释为测量对应位串的整数索引的概率.然而,SamplerQNN还允许我们指定一个interpret函数来对样本进行后处理.这个函数应该被定义为一个测量的整数(从一个位字符串)并将其映射到一个新的值,即非负整数.
(!)重要的是要注意,如果定义了自定义的interpret函数,则网络无法推断出output_shape,需要显式提供.
(!)同样重要的是要记住,如果没有使用interpret函数,概率向量的维度将随着量子比特的数量呈指数级扩展.使用自定义的interpret函数,这种缩放可以改变.例如,如果将索引映射到对应位串的奇偶校验,即映射到0或1,结果将是长度为2的概率向量,与量子比特的数量无关.
让我们为SamplerQNN创建一个不同的量子电路.在这种情况下,我们将有两个输入参数和四个可训练的权重,它们将两个局部电路参数化.
from qiskit.circuit import ParameterVector
inputs2 = ParameterVector("input", 2)
weights2 = ParameterVector("weight", 4)
print(f"input parameters: {[str(item) for item in inputs2.params]}")
print(f"weight parameters: {[str(item) for item in weights2.params]}")
qc2 = QuantumCircuit(2)
qc2.ry(inputs2[0], 0)
qc2.ry(inputs2[1], 1)
qc2.cx(0, 1)
qc2.ry(weights2[0], 0)
qc2.ry(weights2[1], 1)
qc2.cx(0, 1)
qc2.ry(weights2[2], 0)
qc2.ry(weights2[3], 1)
qc2.draw(output="mpl")
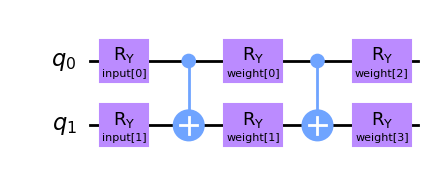
与EstimatorQNN类似,在实例化SamplerQNN时,我们必须指定输入和权重.在这种情况下,关键字参数将是:
- sampler: 可选的原始实例
- input_params: 应被视为“网络输入”的量子电路参数列表
- weight_params: 应被视为“网络权重”的量子电路参数列表
请注意,我们再次选择不将Sampler实例设置为QNN,而是依赖默认值.
from qiskit_machine_learning.neural_networks import SamplerQNN
sampler_qnn = SamplerQNN(circuit=qc2, input_params=inputs2, weight_params=weights2)
sampler_qnn
除了上面显示的基本参数之外, SamplerQNN还接受另外三个设置:input_gradients、interpret和output_shape.这些将在第4节和第5节中介绍.
如何运行正向传递
配置
在真实环境中,输入由数据集定义,权重由训练算法定义,或者作为预训练模型的一部分.然而,在本教程中,我们将指定随机输入集和正确维度的权重:
EstimatorQNN示例
estimator_qnn_input = algorithm_globals.random.random(estimator_qnn.num_inputs)
estimator_qnn_weights = algorithm_globals.random.random(estimator_qnn.num_weights)
print(
f"Number of input features for EstimatorQNN: {estimator_qnn.num_inputs} \nInput: {estimator_qnn_input}"
)
print(
f"Number of trainable weights for EstimatorQNN: {estimator_qnn.num_weights} \nWeights: {estimator_qnn_weights}"
)
SamplerQNN 示例
sampler_qnn_input = algorithm_globals.random.random(sampler_qnn.num_inputs)
sampler_qnn_weights = algorithm_globals.random.random(sampler_qnn.num_weights)
print(
f"Number of input features for SamplerQNN: {sampler_qnn.num_inputs} \nInput: {sampler_qnn_input}"
)
print(
f"Number of trainable weights for SamplerQNN: {sampler_qnn.num_weights} \nWeights: {sampler_qnn_weights}"
)
一旦我们有了输入和权重,让我们看看批处理和非批处理的结果.
非批处理正向传递
EstimatorQNN示例
对于EstimatorQNN,正向传递的预期输出形状是(1,num_qubits * num_observables),在我们的例子中,1是样本的数量:
estimator_qnn_forward = estimator_qnn.forward(estimator_qnn_input, estimator_qnn_weights)
print(
f"Forward pass result for EstimatorQNN: {estimator_qnn_forward}. \nShape: {estimator_qnn_forward.shape}"
)
SamplerQNN示例
对于SamplerQNN(没有自定义解释函数),正向传递的预期输出形状是(1,2 **num_qubits).使用自定义的解释函数,输出的形状将是(1,output_shape),在我们的例子中,1是样本的数量:
sampler_qnn_forward = sampler_qnn.forward(sampler_qnn_input, sampler_qnn_weights)
print(
f"Forward pass result for SamplerQNN: {sampler_qnn_forward}. \nShape: {sampler_qnn_forward.shape}"
)
批处理向正向传递
EstimatorQNN示例
对于EstimatorQNN,正向传递的预期输出形状是(batch_size, num_qubits * num_observables):
estimator_qnn_forward_batched = estimator_qnn.forward(
[estimator_qnn_input, estimator_qnn_input], estimator_qnn_weights
)
print(
f"Forward pass result for EstimatorQNN: {estimator_qnn_forward_batched}. \nShape: {estimator_qnn_forward_batched.shape}"
)
SamplerQNN示例
对于SamplerQNN(没有自定义解释函数),正向传递的预期输出形状是(batch_size, 2**num_qubits).使用自定义的解释函数,输出的形状将是(batch_size, output_shape).
sampler_qnn_forward_batched = sampler_qnn.forward(
[sampler_qnn_input, sampler_qnn_input], sampler_qnn_weights
)
print(
f"Forward pass result for SamplerQNN: {sampler_qnn_forward_batched}. \nShape: {sampler_qnn_forward_batched.shape}"
)
如何运行反向传播
让我们利用上面定义的输入和权重来展示反向传递的工作原理.这一次传递返回一个元组(input_gradients, weight_gradients).默认情况下,反向传递将只计算关于权重参数的梯度.
如果你想启用关于输入参数的梯度,则应该在QNN实例化期间设置以下标志:
qnn = ...QNN(..., input_gradients=True)
请记住,使用TorchConnector进行PyTorch集成需要输入梯度.
无输入梯度的反向传播
EstimatorQNN示例
对于EstimatorQNN,权重梯度的预期输出形状是(batch_size, num_qubits * num_observables, num_weights):
estimator_qnn_input_grad, estimator_qnn_weight_grad = estimator_qnn.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(
f"Input gradients for EstimatorQNN: {estimator_qnn_input_grad}. \nShape: {estimator_qnn_input_grad}"
)
print(
f"Weight gradients for EstimatorQNN: {estimator_qnn_weight_grad}. \nShape: {estimator_qnn_weight_grad.shape}"
)
SamplerQNN示例
对于SamplerQNN(没有自定义解释函数),正向传递的预期输出形状是(batch_size, 2**num_qubits, num_weights).使用自定义的解释函数,输出的形状将是(batch_size, output_shape, num_weights):
sampler_qnn_input_grad, sampler_qnn_weight_grad = sampler_qnn.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(
f"Input gradients for SamplerQNN: {sampler_qnn_input_grad}. \nShape: {sampler_qnn_input_grad}"
)
print(
f"Weight gradients for SamplerQNN: {sampler_qnn_weight_grad}. \nShape: {sampler_qnn_weight_grad.shape}"
)
带有输入梯度的反向传播
让我们启用input_gradients来显示此选项的预期输出大小.
estimator_qnn.input_gradients = True
sampler_qnn.input_gradients = True
EstimatorQNN示例
对于EstimatorQNN,输入梯度的预期输出形状为(batch_size, num_qubits * num_observables, num_inputs):
estimator_qnn_input_grad, estimator_qnn_weight_grad = estimator_qnn.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(
f"Input gradients for EstimatorQNN: {estimator_qnn_input_grad}. \nShape: {estimator_qnn_input_grad.shape}"
)
print(
f"Weight gradients for EstimatorQNN: {estimator_qnn_weight_grad}. \nShape: {estimator_qnn_weight_grad.shape}"
)
SamplerQNN示例
对于SamplerQNN(没有自定义解释函数),输入梯度的预期输出形状是(batch_size, 2**num_qubits, num_inputs).使用自定义的解释函数,输出的形状将是(batch_size, output_shape, num_inputs).
sampler_qnn_input_grad, sampler_qnn_weight_grad = sampler_qnn.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(
f"Input gradients for SamplerQNN: {sampler_qnn_input_grad}. \nShape: {sampler_qnn_input_grad.shape}"
)
print(
f"Weight gradients for SamplerQNN: {sampler_qnn_weight_grad}. \nShape: {sampler_qnn_weight_grad.shape}"
)
高阶功能
带有多个观测量的EstimatorQNN
EstimatorQNN允许为更复杂的QNN架构传递可观察对象列表.例如(注意输出形状的变化):
observable2 = SparsePauliOp.from_list([("Z" * qc1.num_qubits, 1)])
estimator_qnn2 = EstimatorQNN(
circuit=qc1,
observables=[observable1, observable2],
input_params=[params1[0]],
weight_params=[params1[1]],
)
estimator_qnn_forward2 = estimator_qnn2.forward(estimator_qnn_input, estimator_qnn_weights)
estimator_qnn_input_grad2, estimator_qnn_weight_grad2 = estimator_qnn2.backward(
estimator_qnn_input, estimator_qnn_weights
)
print(f"Forward output for EstimatorQNN1: {estimator_qnn_forward.shape}")
print(f"Forward output for EstimatorQNN2: {estimator_qnn_forward2.shape}")
print(f"Backward output for EstimatorQNN1: {estimator_qnn_weight_grad.shape}")
print(f"Backward output for EstimatorQNN2: {estimator_qnn_weight_grad2.shape}")
带有自定义解释器的SamplerQNN
SamplerQNN的一个常见解释方法是奇偶函数,它允许它执行二分类.正如在实例化一节中所解释的,使用explain函数将修改正向和反向传递的输出形状.对于奇偶校验解释函数,output_shape固定为2.因此,预期的前向梯度形状和权重梯度形状分别为(batch_size, 2)和(batch_size, 2, num_weights):
parity = lambda x: "{:b}".format(x).count("1") % 2
output_shape = 2 # parity = 0, 1
sampler_qnn2 = SamplerQNN(
circuit=qc2,
input_params=inputs2,
weight_params=weights2,
interpret=parity,
output_shape=output_shape,
)
sampler_qnn_forward2 = sampler_qnn2.forward(sampler_qnn_input, sampler_qnn_weights)
sampler_qnn_input_grad2, sampler_qnn_weight_grad2 = sampler_qnn2.backward(
sampler_qnn_input, sampler_qnn_weights
)
print(f"Forward output for SamplerQNN1: {sampler_qnn_forward.shape}")
print(f"Forward output for SamplerQNN2: {sampler_qnn_forward2.shape}")
print(f"Backward output for SamplerQNN1: {sampler_qnn_weight_grad.shape}")
print(f"Backward output for SamplerQNN2: {sampler_qnn_weight_grad2.shape}")
总结
在本教程中,我们介绍了qiskit-machine-learning提供的两个神经网络类,即EstimatorQNN和SamplerQNN,它们扩展了基本神经网络类.我们提供了一些理论背景,QNN初始化的关键步骤,前向和后向传递的基本使用,以及高级功能.
现在,我们鼓励您尝试设置问题,并了解不同的电路大小、输入和权重参数长度如何影响输出形状.

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









