










MOTR: End-to-End Multiple-Object Tracking with Transformer
论文地址:arXiv
论文源码:code
1. 概述
现有方法的缺点:缺乏从数据中学习时间变化的能力。采用简单的启发式方法(空间或外观相似性),这些方法简单不足以模拟复杂的变化,例如通过遮挡进行跟踪。
本文介绍的MOTR是一个完全端到端的多目标跟踪框架,学习模拟物体的长时间变化,隐式的执行时间关联,避免以前的显示启发式。在Transformer,DETR,MOTR的基础上引入轨迹查询的概念。每个轨迹查询对对象的整个轨迹进行建模,被逐帧传输和更新,以无缝方式执行对象监测和跟踪。提出了结合多帧训练的时态聚合网络来建模长程时态关系。
总结现有的tracker:将问题分为两部分:目标定位和时间关联。
目标定位:Fast R-CNN,Object as Points,Yolov3被用于逐帧检测
时间关联:使用IoU或者使用外观相似性(ReID)的方法进行检测。
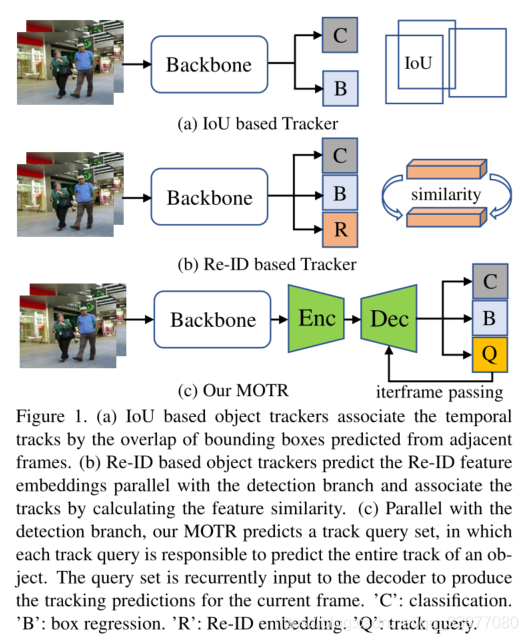
前两种方法很难对一个物体在长时间间隔内的空间和外观变化的复杂性进行建模,即缺乏从数据中建模时间变化的机制。IoU对于遮挡问题束手无策,ReID对于异质问题束手无策。本文是设计一种没有任何关联过程的端到端跟踪框架来寻找解决这些缺点的替代方法。
每个轨迹查询负责预测对象的整个轨迹。如图1©所示,与分类和回归分支平行,MOTR预测每一帧的轨迹查询集。轨迹查询集被输入到解码器网络,以直接产生当前帧的跟踪预测和更新的轨迹查询(由解码器输出)。更新的轨迹查询被进一步传递给下一帧的解码器。这种查询传递和预测过程对整个视频序列逐帧重复,称为连续查询传递。因为一旦查询被一个对象匹配,每个跟踪查询就一直跟随同一个对象,所以连续的查询传递可以自然地去除时间关联和一些手工操作,比如NMS。为了对长期时间关系建模,我们进一步引入了多帧训练和时间聚合网络(Temporal Aggregation Network) TAN。他建立一个查询内存库来收集历史终于被跟踪对象相对应的查询。当前帧的轨迹查询会通过多头关注与记忆库中的每个查询进行交互。
论文的工作:
- 完全端到端的多目标跟踪框架。和前两种方法不同,在没有任何显式关联的情况下直接生成跟踪预测。
- 引入跟踪查询和连续查询传递机制的概念,这种机制从数据中学习对象的长期时间变化的建模。
- 进一步提出结合多帧训练的时间聚合网络,以帮助对长期时间关系进行建模。允许MOTR有效地减少因缺乏时间信息而导致的身份转换。
我们的工作基于DETR,TransTrack和TransFormer也是基于Transformer的MOT框架。TransTrack只是一个联合训练检测和跟踪的统一框架,tracks仍然通过IoU匹配来关联。尽管本文的方法和TrackFormer相似,但是也有些许不同:1)我们的MOTR是一个完整的端到端的MOT框架,消除了在TrackFormer中使用NMS的需要。2)提出了结合多帧训练的时态聚合网络来建模长程时态关系。
2. 方法
2.1 DETR介绍
近年来,DETR使用Transformer在目标检测方面取得了成功。在DETR中,有一些特定数量的学习位置嵌入的对象查询代表了一些可能实例的建议框。一个对象只和使用二分匹配的一个对象匹配。考虑到DETR存在高复杂性和慢收敛的问题,Deformable DETR简单地用多尺度可变形注意替代了Transformer中的自注意。为了表示对象查询如何通过解码器与特征进行交互,我们reformulate了Deformable DETR解码器。
In DETR, the object queries, a fixed number of learned positional embeddings, represent the proposals of some possible instances,
Decoder:
q
∈
R
C
q \in R^C
q∈RC表示一组对象查询,
f
∈
R
C
f \in R^C
f∈RC表示来自自编码器网络的特征图,C代表特征维度。解码器的过程可以表示为:
q
k
=
G
c
a
(
G
s
a
(
q
k
−
1
)
,
f
)
q^k = G_{ca}(G_{sa}(q^{k-1}),f)
qk=Gca(Gsa(qk−1),f)
其中,
k
∈
1
,
.
.
.
,
k
k \in 1, ..., k
k∈1,...,k和
K
K
K是解码器的总层数。
q
k
q^k
qk是第k层解码层的输入结果。
G
s
a
G_{sa}
Gsa是DETR中自注意机制。
G
c
a
G_{ca}
Gca代表多尺度可变注意力。
2.2 MOTR
在MOTR,我们引入了跟踪查询和连续查询传递,以完全端到端的方式执行跟踪预测。时间聚集网络被进一步提出以增强多个帧的时间信息。
2.2.1 端到端跟踪查询传递
检测查询vs跟踪查询:DETR引入目标检测不是对特定的目标进行预测,因此,随着输入图像的变化,一个对象查询可以预测不同的对象。跟踪查询中每个轨迹查询负责预测对象的整个轨迹,一旦轨迹查询与一个帧中的对象匹配,它总是预测该对象,直至对象消失。因此,来自同一轨迹查询的所有预测结果自然地形成对象的轨迹,而没有显式的关联。轨迹查询的保序是通过目标确定的轨迹查询监督来学习的。为了处理当前帧中出现的新对象,我们进一步引入了空查询。

MOTR使用的轨迹查询和目标检测中的检测查询比较:a),该查询与对象所处的位置相关。当对象的位置发生变化时,查询身份会随机切换。b),多对象跟踪的轨迹查询:一旦轨迹查询与一个对象匹配,对象的查询标识将不会切换,直到对象消失。
连续查询传递:基于上述轨迹查询,文章提出了连续查询机制。在这种机制中,跟踪查询被逐帧传送,以迭代地更新与查询匹配的对象的表示和定位。MOTR就是一个通过连续查询传递的完全端到端的MOT框架。在MOTR,对象的时间变化模型是由解码器的多头注意力隐式学习的,而不是显式关联。
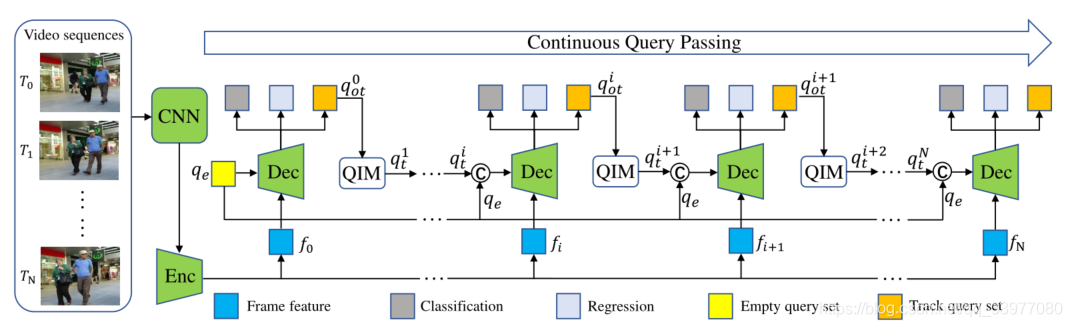
对于初始的 T 0 T_0 T0帧,基本特征 f 0 f_0 f0和黄框的空查询 q e q_e qe一起被输入到解码器网络,已定位初始对象并为 T 1 T_1 T1帧生成初始查询轨迹,对于 T i T_i Ti帧,通过前一帧预测的原始轨迹查询 q o t i q^i_{ot} qoti通过交互查询模块和空查询更新,已生成当前帧的轨迹查询。执行连续查询传递,以在整个视频序列内传递轨迹查询。
视频序列首先输入到CNN(ResNet50)网络和Deformable DETR来提取基本特征列表 f = f 0 , f 1 , . . . , f N f = {f_0,f_1,...,f_N} f=f0,f1,...,fN。对于 T 0 T_0 T0帧而言,basic feature f 0 f_0 f0和空的查询集合 q e q_e qe被输入到解码网络用于定位所有初始对象并生成原始轨迹查询集合 q o t 1 q^1_{ot} qot1。原始轨迹查询集合 q o t 1 q^1_{ot} qot1通过查询交互模块QIM(Query Interaction Module)生成 T 1 T_1 T1帧的查询轨迹集合 q t 1 q^1_{t} qt1。对于 T i T_i Ti帧 i ∈ [ 1 , N ] i \in [1,N] i∈[1,N]而言,通过从第 T i − 1 T_{i-1} Ti−1帧QIM生成的跟踪查询集合 q t i q^i_{t} qti和空的查询机和 q e q_e qe将会被连接。级联的查询集与基本特征一起被输入到共享解码器,以直接生成当前帧的预测以及 T i + 1 T_{i+1} Ti+1帧的原始轨道查询集 q o t i + 1 q^{i+1}_{ot} qoti+1。对整个视频序列重复这样的过程。
理解:首先视频帧通过CNN和Enc网络进行特征提取生成列表,然后逐特征进行分析,空查询集合和f0被送入到Dec解码器中,生成查询轨迹然后送入到QIM中生成下一帧的查询轨迹,知道分析完所有的视频帧得到查询轨迹集合。
2.2.2 Query Interaction Module
QIM主要包括物理进出机制和时间聚集网络。
Object Entrance and Exit:每个查询轨迹代表完整的轨迹。但是视频序列中对象往往在中间帧出现或消失,下来介绍MOTR的物体进入和退出的情况。
训练阶段,轨迹查询的学习可以通过监督二分匹配的GTs来实现,**对于推断,使用轨迹的预测分数来确定轨迹何时出现或消失。**在下图中,对于
T
i
T_i
Ti帧,从
T
i
−
1
T_{i-1}
Ti−1帧生成的轨迹查询集合
q
t
i
q^i_t
qti和空查询集合
q
e
q_e
qe被连接。被连接的查询集合输入到解码器然后生成具有轨道分数的原始轨迹查询集合
q
o
t
i
q^i_{ot}
qoti。然后被分为两个子查询集合:
q
e
n
i
=
q
o
t
i
[
:
d
e
]
,
q
c
e
i
=
q
o
t
i
[
d
e
:
]
q^i_{en}=q^i_{ot}[:d_e],q^i_{ce}=q^i_{ot}[d_e:]
qeni=qoti[:de],qcei=qoti[de:],其中,
d
e
d_e
de是在空查询集合
q
e
q_e
qe的查询数,
q
e
n
i
q^i_{en}
qeni包含进入的目标当
q
c
e
i
q^i_{ce}
qcei包含已跟踪和退出的目标。对于目标入口,保留跟踪分数高于入口阈值
τ
e
n
\tau_{en}
τen的
q
e
n
i
q^i_{en}
qeni查询对象(3),同时删除左侧的查询:
q
‾
e
n
i
=
{
q
k
∈
q
e
n
i
∣
s
k
>
τ
e
n
}
{\overline q}^i_{en} = \{q_k \in q^i_{en}|s_k \gt \tau_{en}\}
qeni={qk∈qeni∣sk>τen}
s
k
s_k
sk对应于在
q
e
n
i
q^i_{en}
qeni的第k个查询
q
k
q_k
qk的分类分数。在目标退出的过程,跟踪分数低于连续M帧退出阈值
τ
e
x
\tau_{ex}
τex的
q
i
q_i
qi中的查询(对象2)将被删除,而查询1将会被保留。
q
‾
c
i
=
{
q
k
∈
q
c
e
i
∣
max
{
s
k
i
,
.
.
.
,
s
k
i
−
M
}
>
τ
e
x
}
{\overline q}^i_c = \{q_k \in q^i_{ce}| \max \{s^i_k,...,s^{i-M}_k\} \gt \tau_{ex} \}
qci={qk∈qcei∣max{ski,...,ski−M}>τex}
这里,
τ
e
n
=
0.8
,
τ
e
x
=
0.6
,
M
=
5
\tau_{en} = 0.8, \tau_{ex} = 0.6, M = 5
τen=0.8,τex=0.6,M=5.
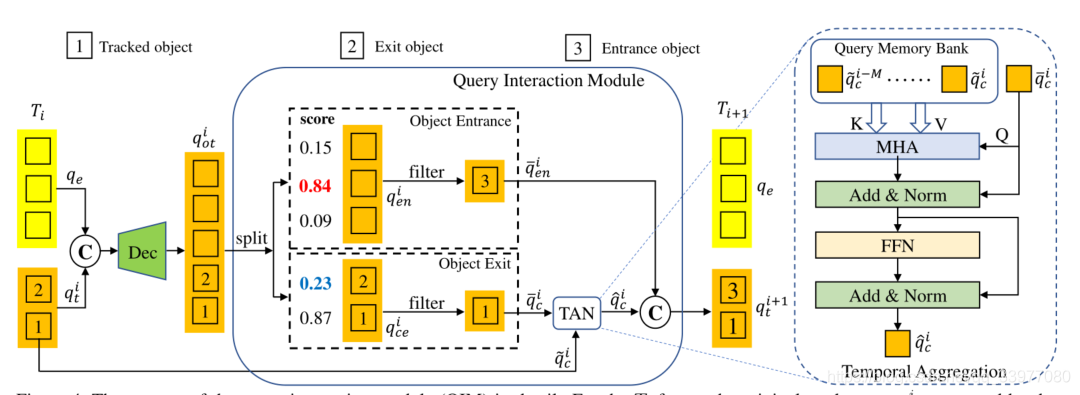
理解:经过Dec网络的跟踪轨迹们被分成两部分,一部分是探索是否有目标淡入视野,一部分是有目标淡出视野,这两个都有相应的阈值,如果高于阈值就选择它们进行后续操作,同时将子集合中其他目标移除。阈值是连续五帧中的分类得分最大值高于给定值。这两个子查询集合也很有意思,前半部分意思是目标出现了,表示最近5帧中有了该目标,后半部分是目标淡出视线,最近五帧或更小没有该目标。
时态聚集网络:这部分引入时间聚集网络来增强时间关系,并未被跟踪对象提供上下文先验。首先为跟踪对象的时间聚合建立所谓的查询内存库。记忆库
q
b
a
n
k
=
{
q
~
c
i
−
M
,
.
.
.
,
q
~
c
i
}
q_{bank}=\{\tilde q^{i-M}_c,...,\tilde q^i_c\}
qbank={q~ci−M,...,q~ci}首先收集历史中对应于被跟踪对象的查询。存储体中的查询被连接在一起:
t
g
t
=
q
~
c
i
−
M
⊕
.
.
.
q
~
c
i
−
1
⊕
q
~
c
i
tgt = \tilde q^{i-M}_c \oplus ... \tilde q^{i-1}_c \oplus \tilde q^i_c
tgt=q~ci−M⊕...q~ci−1⊕q~ci
被连接的查询作为值和关键元素被输入到多头注意力(MHA)模块来生成注意力权重,
q
‾
c
i
\overline q^i_c
qci作为MHA的查询元素通过点积生成进行更新。
q
s
a
i
=
σ
s
(
t
g
t
⋅
t
g
t
T
d
)
⋅
q
‾
c
i
q^i_{sa} = \sigma_s (\frac { tgt \cdot tgt^T} {\sqrt d}) \cdot \overline q^i_c
qsai=σs(dtgt⋅tgtT)⋅qci
其中
σ
s
\sigma_s
σs是softmax函数,d是跟踪查询的维度。之后,
q
s
a
i
q^i_{sa}
qsai通过前馈网络(FNN forward neural network)进一步完善.
t
g
t
~
=
L
N
(
q
s
a
i
+
q
‾
c
i
)
q
c
i
^
=
L
N
(
F
C
(
σ
r
(
F
C
(
t
g
t
~
)
)
+
t
g
t
~
)
)
\tilde {tgt} = LN(q^i_{sa} + \overline q^i_c)\\ \hat{q^i_c} = LN(FC(\sigma_r(FC(\tilde{tgt}))+\tilde {tgt}))
tgt~=LN(qsai+qci)qci^=LN(FC(σr(FC(tgt~))+tgt~))
FC代表线性投影层,LN是layer normalization。
σ
r
\sigma_r
σr是ReLU激活函数。TAN的输出
q
^
c
i
\hat q^i_c
q^ci和
q
‾
e
n
i
\overline q^i_{en}
qeni连接在一起产生
T
i
+
1
T_{i+1}
Ti+1帧的追踪查询集合
q
t
i
+
1
q^{i+1}_t
qti+1。
理解:将前几帧的轨迹送入到MHA中生成注意力权重,Add&Norm是通过点积将 q ‾ c i \overline q^i_c qci引入进行更新,之后通过FNN进行完善,在通过激活函数进行加工产生 T i + 1 T_{i+1} Ti+1帧的追踪查询集合。
2.2.3 总体优化
MOTR的训练过程:给定一个视频序列作为输入,训练损失(轨迹损失)是与逐帧生成的预测一起逐帧计算的。总的轨迹损失是所有帧的轨迹损失之和,由训练样本上的所有几何图形的数量归一化:
L
o
t
(
Y
,
Y
^
)
=
∑
n
=
0
N
L
t
(
Y
i
,
Y
^
i
)
∑
n
=
0
N
(
V
i
)
L_{ot}(Y,\hat Y) = \frac { \sum^N_{n=0}L_t(Y_i,\hat Y_i)} {\sum^N_{n=0}(V_i)}
Lot(Y,Y^)=∑n=0N(Vi)∑n=0NLt(Yi,Y^i)
其中,N是总视频序列的长度,
Y
i
,
Y
^
i
Y_i,\hat Y_i
Yi,Y^i分别是在
T
i
T_i
Ti帧预测和Ground Truth的值。
V
i
=
V
t
i
+
V
e
i
V_i = V^i_t + V^i_e
Vi=Vti+Vei代表在
T
i
T_i
Ti帧的GT的总数量。加号两端分别是跟踪目标的数量和新的跟踪的数量。
L
t
L_t
Lt是单帧的损失类似于Deformable DETR的检测损失,可以被表示为:
L
t
(
Y
i
,
Y
^
i
)
=
λ
c
l
s
L
c
l
s
+
λ
l
1
L
l
1
+
λ
g
i
o
u
L
g
i
o
u
L_t(Y_i,\hat Y_i)=\lambda_{cls}L_{cls}+\lambda_{l1}L_{l1}+\lambda_{giou}L_{giou}
Lt(Yi,Y^i)=λclsLcls+λl1Ll1+λgiouLgiou
L
c
l
s
L_{cls}
Lcls是focal loss。
L
l
1
L_{l1}
Ll1表示L1损失,
L
g
i
o
u
L_{giou}
Lgiou表示广义的IoU损失。
本文的跟踪损失和Deformable-DETR的检测损失的主要不同可能是标签的分配(如何将标签分配给预测作为监督)。对于检测损失,标签分配完全由所有GT和预测的匈牙利匹配来决定。而对于跟踪丢失,因为跟踪查询响应于特定目标轨道的预测,跟踪查询的GT对象由查询跟踪的对象的身份决定。对于空查询,其预测的GT对象由空查询的预测和新轨迹的GT之间的匈牙利匹配来确定。
3. 实验
3.1 数据集和参数设置
实验室用MOT16和MOT17.在公共检测方面,MOT16使用DPM检测器而MOT17使用DPM,Faster R-CNN和SDP目标检测器。
评估指标:多目标跟踪精度(MOTA),最大跟踪轨迹比(MT),最大损失轨迹(ML),特征转换(IDS),特征F1分数(IDF1)
IDF1被用于测量轨迹同一性精度,MOTA是衡量整体检测和跟踪性能的主要指标。
M
O
T
A
=
1
−
∑
i
F
P
i
+
F
N
i
+
I
D
S
W
i
∑
i
G
T
i
MOTA = 1 - \frac {\sum_i FP_i + FN_i + IDSW_i} {\sum_i GT_i}
MOTA=1−∑iGTi∑iFPi+FNi+IDSWi
其中,分母和分子的含义分别为:真实值边框的个数,假正例数,假反例数,第i帧特征转换数量。
采用中心轨迹数据增强(随机翻转随机裁剪)的方法,图像大小800*1536.使用 p d r o p p_{drop} pdrop为入口生成更多的样本,使用 p i n s e r t p_{insert} pinsert生成假正例模拟对象淡出视野, p d r o p , p i n s e r t p_{drop},p_{insert} pdrop,pinsert和采样间隔设置为0.1,0.3,10。
主干网络是ResNet50的Deformable-DETR网络。基本网络在COCO上预处理,用0.0002的AdamW优化器处理200个epoch,在150epoch后衰减到0.00002。batchsize为1包含5帧。
在MOT17和CrowdHuman的val集合上训练MOTR。
3.2 结果比较
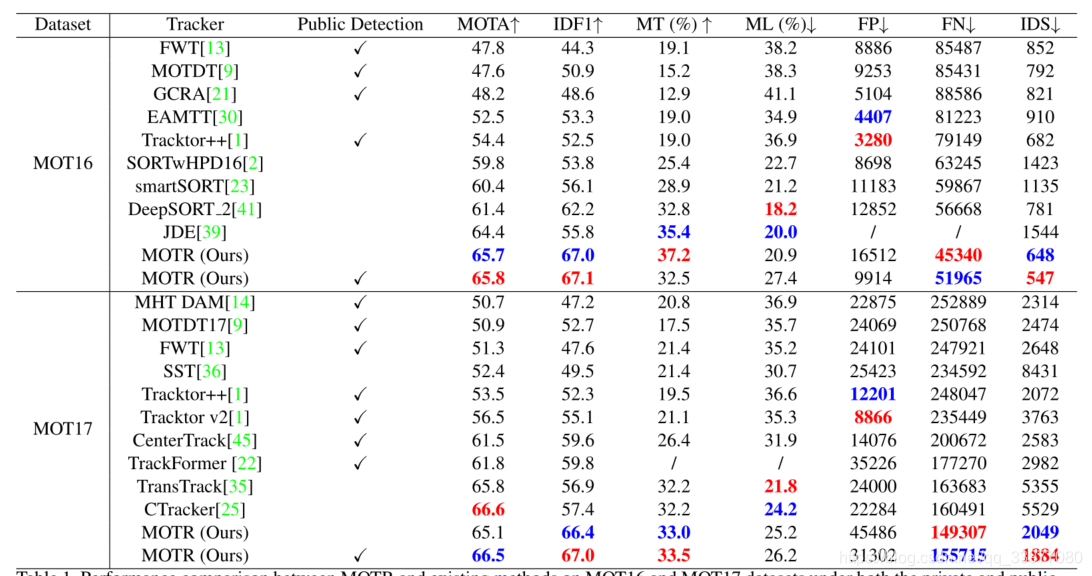
MOT16结果:
| - | MOTR vs. JDE | MOTR vs. DeepSORT |
|---|---|---|
| IDF1 | 11.3% ↑ | 4.9% ↑ |
| IDS | 547 vs. 1544 ↓ | 547 vs. 781 ↓ |
| MOTA | 65.8 vs. 64.4 ↑ | 65.8 > 61.4 ↑ |
MOT17结果:
| - | MOTR vs. TransFormer | MOTR vs. TransTrack |
|---|---|---|
| IDF1 | 7.2% ↑ | 10.1% ↑ |
| IDS | 1884 vs. 5355 ↓ | 1884 vs. 2982 ↓ |
| MOTA | 66.5 vs. 61.8 ↑ | 66.5 vs. 65.8 ↑ |
跟踪性能好表现在更高的IDF1和更低的IDS。我们的MOTR是一个真正的端到端的MOT框架,没有任何基于连续查询传递机制的显式关联过程。
3.3 消融研究
消融研究使用DC5的单特征级别进行快速训练,在2DMOT15训练数据集上进行验证。
MOTR组件:TAN-时间聚合网络 MFT-多帧训练
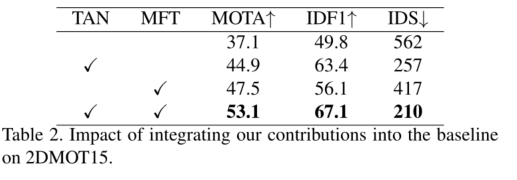
帧序列的长度:
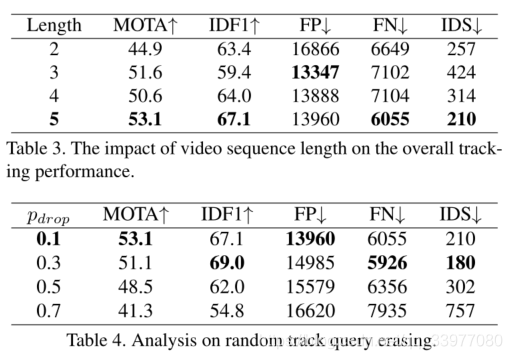
需要注意的是,当视频剪辑长度增加时,重复框会显著减少。不同于跟踪模型[22],它通过跟踪NMS来移除重复的盒子,我们的MOTR可以直接产生跟踪预测,而不需要这样的手工操作。

当视频序列长度设置为2,会出现重复框,当设置为5时,这种现象会消失。
q d r o p q_{drop} qdrop参数设置:在MOT数据集上,很少有目标进入到数据集中,采用概率随机擦除轨迹查询是模拟新对象进入的好方法。过高参数可能会降低跟踪性能,因为跟踪查询没有经过完全训练。
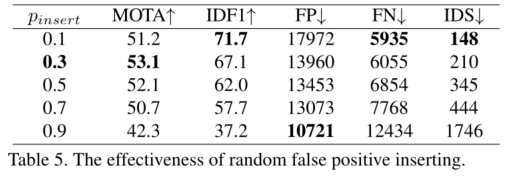
q i n s e r t q_{insert} qinsert参数设置:与上述方法类似,还有少量目标淡出视野,训练过程中,对前一帧中预测为假正例的轨迹查询进行采样,并将这些查询插入到当前帧中以模拟对象淡出视野的情况。
4. 结论
- 完全端到端的多目标跟踪框架,学习模拟物体的长时间变化,隐式的执行时间关联,每个轨迹查询对对象的整个轨迹进行建模,被逐帧传输和更新,以无缝方式执行对象监测和跟踪。提出了结合多帧训练的时态聚合网络来建模长程时态关系。
- 跟踪查询被定义为每个跟踪器,并且空查询被用来检测新对象。同时,引入了连续查询传递和查询交互模块,增强了时态关系,消除了对NMS过程的需求。
- 个人认为可能对多摄像头的跟踪问题效果不是很好,因为在多摄像头中,视频与视频序列之间存在空间异构关系,在设计的时候应该可以优化。














 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









