







 本文详细介绍了Redis中Hash数据类型的两种编码格式:ziplist和hashtable。ziplist是一种压缩列表,适用于存储少量、短字符串,具有内存效率高、遍历速度快的优点,但不擅长修改操作。当数据量增多时,Redis会将ziplist优化为hashtable。hashtable是哈希表,适用于存储大量数据,支持高效的查找和插入操作。文章还深入解析了ziplist和hashtable的内部结构、数据项存储方式以及Redis如何在不同条件下选择合适的编码格式。
本文详细介绍了Redis中Hash数据类型的两种编码格式:ziplist和hashtable。ziplist是一种压缩列表,适用于存储少量、短字符串,具有内存效率高、遍历速度快的优点,但不擅长修改操作。当数据量增多时,Redis会将ziplist优化为hashtable。hashtable是哈希表,适用于存储大量数据,支持高效的查找和插入操作。文章还深入解析了ziplist和hashtable的内部结构、数据项存储方式以及Redis如何在不同条件下选择合适的编码格式。
写在前面
以下的知识都是建立在目前线上稳定版6.2.6版本的
而目前github上的redis源代码又更新优化了许多,譬如:hash数据类型默认的编码格式已经被替换为listpack,hashtable数据结构也被重新优化(哈希表对象dictht被废弃,字典dict直接引用dictEntry节点)
Redis hash数据类型-编码格式
redis中hash数据类型使用了两种编码格式:ziplist(压缩列表)、hashtable(哈希表)
具体使用哪种编码格式,由redis根据情况自己选择更合适的编码格式,这对于上层用户完全透明
- ziplist,又称为压缩列表,是hash数据类型默认使用的编码格式,当满足某种条件后,redis会将ziplist优化为hashtable编码格式,我们也可通过配置来更改达到条件的阈值
hash-max-ziplist-entries 512 //配置当field-value超过512时(合起来1024),使用hashtable编码 //至于为什么是1024,与ziplist有关,后面会讲述 hash-max-ziplist-value 64 //配置当key的单个field或value长度超过64时,使用hashtable编码 - hashtable,又称为哈希表,是hash数据类型中的数据过多或多长时由ziplist优化而来,底层数据结构与ziplist完全不同,且数据结构不可逆(也就是某个key的数据从ziplist演变为hashtable后,就算其数据减少到了ziplist可接受范围,也不会再从hashtable还原为ziplist格式)
ziplist
ziplist(压缩列表)是一个经过特殊编码的双向链表,用于存储字符串或整数,可以提高存储效率。
与普通双向链表的对比
- 内存开销不同,普通双向链表的元素一般需要两个指针,这会占用额外的内存,在数据较小的情况下,可能指针对于内存的占用比数据还大,有点得不偿失。而ziplist压缩列表,是一块连续的内存,数据之间紧密相连,不需要指针这种额外的开销。
- 遍历速度不同,普通链表内的元素一般是分开的,通过指针来查找到下一个元素。而ziplist是在一块连续内存上,所以内部元素遍历起来更快,并且由于ziplist独特的数据结构,它存储了末尾元素的偏移位置,所以它可以轻松定位到末尾元素,所以它获取首尾元素时所需的时间复杂度为O(1)。
ziplist的缺点
- 元素变动,虽然ziplist可以有效提高存储效率,可是这种数据项紧密相连的存储结构不擅长做修改操作,一旦元素发生变动,极大概率会引发内存重新分配造成数据拷贝,从而降低性能
- 数据项过多,当它数据项过多时,遍历查找指定元素也会耗时更久,所以这种数据结构也不宜存储过多的元素
因此,虽然redis精心设计了ziplist这种存储效率很高的数据结构,但是只会在适宜的场景下使用,当数据项过多或元素过长时,redis会将ziplist编码格式优化为更加合适的编码格式
ziplist数据结构
ziplist主要由下图几个部分组成,各部分所占字节如图所示:
字节存储的是16进制数据,最大值为0XFF,也就是255,而类似zlen字段占用两个字节,所能表述的最大值也就是FF FF,也就是2^16 - 1,也就是65535,当小于这个值时,zlen表示entry数据项的个数,当这个值为最大值时,zlen已经不能表示entry数据项的大小了,只能通过遍历可知。
entry数据项数据结构
entry数据项主要由下图几个部分构成:

我们来对其进行简单介绍:
1.首先是prevlen,它存储的是前一个数据项entry的长度,占用1或5个字节,可依据此字段进行反向遍历
- 如果长度在0XFE也就是254之内,则prevlen占用1个字节。
- 如果长度大于等于254,则prevlen占用5个字节。此时,第一个字节值设为0XFE(254),意味着使用后面更大的值,而剩余的4个字节用来表示前一个数据项的长度。(注:至于为什么不使用0XFF,也就是255,是因为255作为ziplist的结尾符,如果在遍历读取entry时,由于entry本身长度就不固定,那么此时就可能将其误认为结尾符,从而引发错误)
2.其次是encoding,这个字段相对复杂,它根据entry-data存入的是整数还是字符串会有不同的格式,所占的字节数也不相同,一般通过第一个字节就可确定数据项是整数还是字符串,整数的话,第一个字节的前2bit是11,否则为字符串
如果为字符串时,占用字节不固定
- 字符串长度小于64时,占用1个字节,二进制结构为00pppppp,后6bit表示长度,最高可表示2^6 - 1,也就是63
- 字符串长度小于16384时,占用2个字节,二进制结构为01pppppp qqqqqqqq,后14bit表示长度,最高可表示2^14 - 1,也就是16283
- 字符串长度大于等于16384时,占用5个字节,二进制结构为10000000 qqqqqqqq rrrrrrrr ssssssss tttttttt,第一个字节后6bit不使用,后面4个字节的32bit位用来表示长度,最高可表示2^32 - 1,也就是4294967295
如果为整数时,都只占1字节,前2bit确定是否整数节点,后6bit确定整数节点的类型
- 二进制结构为11000000,值为0XC0,entry-data存储int16_t类型数据(占用2字节)
- 二进制结构为11010000,值为0XD0,entry-data存储int32_t类型数据(占用4字节)
- 二进制结构为11100000,值为0XE0,entry-data存储int64_t类型数据(占用8字节)
- 二进制结构为11110000,值为0XF0,entry-data存储3个字节的整数
- 二进制结构为11111110,值为0XFE,entry-data存储1个字节的整数
- 二进制结构为1111xxxx,这是特殊情况,此时xxxx的值在0001至1101之间(因为0000和1110都已经被上面使用了),所以xxxx换算为十进制也就是1-13,而数值应该从0开始,所以得剪1,代表的就是0-12这几个值。此时xxxx直接用来表示entry-data的数据值,也就是不存在entry-data了
3.最后是entry-data,存储整数或字节数组。
- 当存入的是字符串时,会存入每个字符在ASCII表中对应的16进制值,然后形成一个字节数组。
- 当存入的是数字时,如果是上面所讲的特殊情况(即encoding为1111xxxx这种),那么该字段不存在,否则会按所属情况存储不同类型的数据,数据类型不同所占用字节也不同
ziplist数据结构实例分析
例如:逐步分析下图中的ziplist字节数据

- zlbytes,4个字节,由于redis采用是小端模式存储,所以实际应为00 00 00 1a,转化为十进制是26,表示该ziplist总共有26个字节
- zltail,4个字节,00 00 00 0c转化为十进制是12,表示该ziplist中最后一个数据项entry所在的位置是第12个字节
- zlen,2个字节,00 02转化为十进制是2,表示该ziplist中有2个数据项entry,如果此值为ff ff时,则说明两个字节不够记录数据项数量了,需遍历才能得知
- entry1,2个字节,00转化为十进制是0,表示上一个数据项长度为0。f3转化为二进制是11110011,通过上面encoding介绍可知,它属于1111xxxx这个特殊情况,那么0011二进制即为所存数据值,转化为十进制是3,3-1=2,所以可以知道redis中该key的第一个值存的是2
- entry2,13个字节,02转化为十进制是2,表示上一个数据项长度为2。0b转化为二进制是00001011,通过encoding介绍可知,它存入的是字符串且小于64,所以直接通过第一个字节的后6位bit可算出十进制是11,说明entry-data长度是11位。然后根据16进制数据去ASCII表中一个个寻找(例如:16进制为48的在ASCII中表示H),可得知字节数组合起来是Hello World,所以可以知道redis中该key的第二个值存的是Hello World
- 0XFF,读到这里说明该ziplist到这里就结束了
hash-max-ziplist-entries解析
上面提到了该参数设置为512时,实际是1024才会满足条件,现在我们就来通过源码一步步解释为什么是这么个情况。
首先,下面是hash数据类型设置字段及值的方法,我们可以看到如果使用ziplist编码格式的话,会将field和value作为两个数据项(entry-data)放入到ziplist中去,所以hash数据类型的一次赋值操作,会在ziplist中存入两个entry-data。然后调用hashTypeLength方法来判断是否超过配置的最大数据项值
//t_hash.c中第207行
//hash数据类型设置字段值方法
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
//如果使用的是ziplist编码格式
unsigned char *zl, *fptr, *vptr;
//获取redisObject中的数据指针,该指针指向相应ziplist的那块内存地址
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Replace value */
zl = ziplistReplace(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
//将hash数据类型中的field作为数据项存入ziplist内存
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
//将hash数据类型中field对应的value作为数据项存入ziplist内存
//field及value是一前一后紧挨着存放的
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
//判断redisObject的数据项数量是否超过了所配置的最大值
//如果超过了,则转换成hashtable编码格式
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
从hashTypeLength方法中可以看出,如果是ziplist的话,获取数据项长度后会除以2,这个值才是用作判断条件的值
//t_hash.c中第313行
unsigned long hashTypeLength(const robj *o) {
unsigned long length = ULONG_MAX;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
//如果是ziplist
//获取数据项长度后/2
length = ziplistLen(o->ptr) / 2;
} else if (o->encoding == OBJ_ENCODING_HT) {
length = dictSize((const dict*)o->ptr);
} else {
serverPanic("Unknown hash encoding");
}
return length;
}终上,我们可以看出,当我们将参数设置为512时,意味着,我们可以为ziplist设置512个field-value键值对,而键值对是分开作为数据项(entry-data)存储的,所以实际上ziplist可以存入1024个数据项的
hashtable
hash数据类型的数据在满足条件后,底层就会更改为字典+哈希表的数据结构。
字典
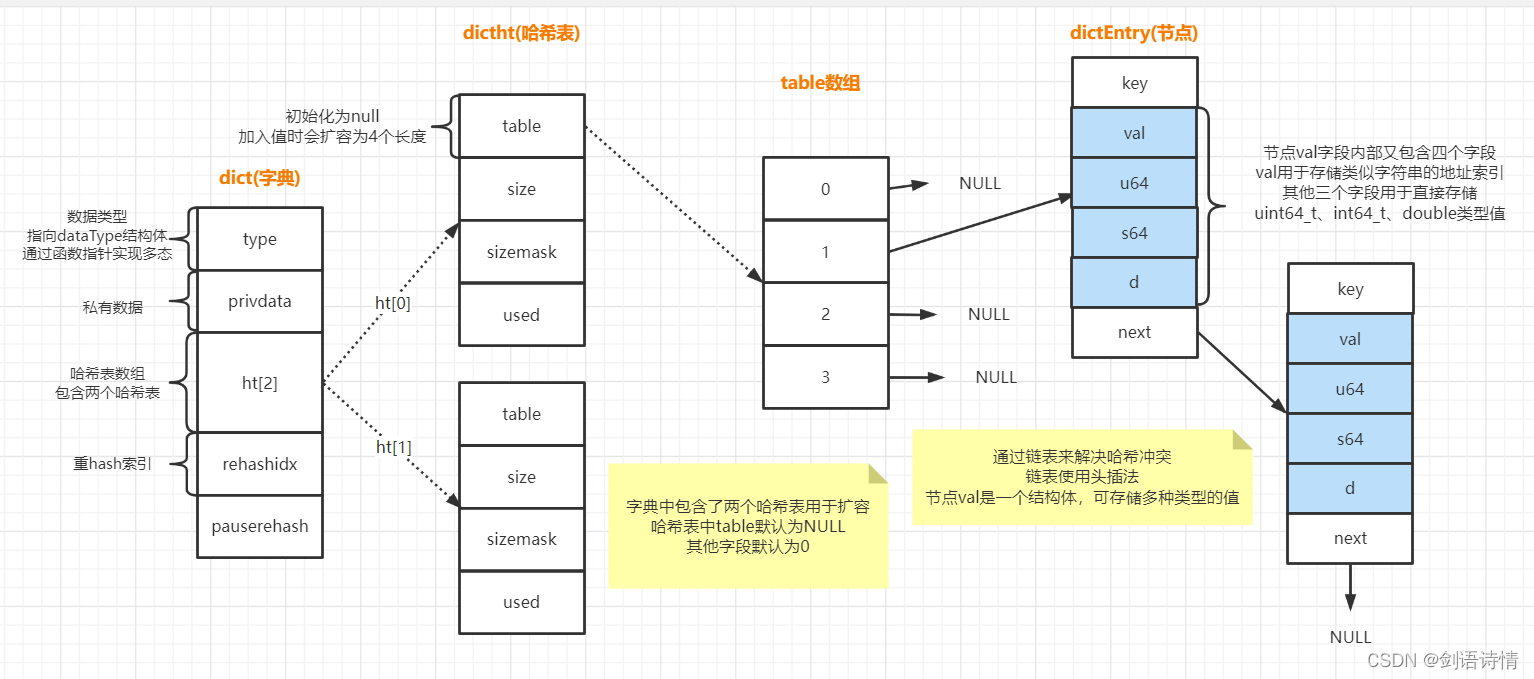
redis中的字典(dict)使用哈希表作为底层实现,一个字典中定义了两个哈希表,主要是为了解决扩容问题
它在源码中定义的结构如下:
//dict.h中第80行
//字典表数据结构
typedef struct dict {
dictType *type; //存储指向dictType结构的指针,具体作用后面再介绍
void *privdata; //存储私有数据的指针,在dictType里面的函数会使用
dictht ht[2]; //定义了两个哈希表
long rehashidx; //重hash索引,值为-1时,表示没有进行rehash,否则用于记录哈希表rehash执行到的那个元素的数组下标
int16_t pauserehash; //>0表示rehash暂停,<0表示编码错误
} dict;dictType
dictType的内部定义结构如下:
//dict.h中第61行
//dictType结构体
//该结构体中定义的都是方法指针,而不是具体的方法
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); //计算hash值
void *(*keyDup)(void *privdata, const void *key); //复制键(key)
void *(*valDup)(void *privdata, const void *obj); //复制值(value)
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比对键
void (*keyDestructor)(void *privdata, void *key); //销毁键
void (*valDestructor)(void *privdata, void *obj); //销毁值
int (*expandAllowed)(size_t moreMem, double usedRatio); //扩容
} dictType;从dictType的结构可以看出,它里面定义了一整套用于操作key、value的函数指针。在不同场景下,会为字典提供不同的实现,以此保证字典功能的多样性。也就是通过函数指针来实现多态。(注:个人觉得以Java来类比的话,dictType其实就像一个抽象类,里面定义了一套待实现的公共方法,然后根据不同场景定义不同的类来继承和实现dictType抽象类的部分方法,以此来达到多态的效果)
以下是源码中部分dictType的具体实现,由于具体实现太多,所以只截取了部分
//server.c中第1362行
//其中有很多dictType的具体实现,根据使用场景不同,只实现了该场景所需的方法
//且根据使用场景,同一个方法的具体实现也可能不同
/* Generic hash table type where keys are Redis Objects, Values
* dummy pointers. */
dictType objectKeyPointerValueDictType = {
dictEncObjHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictEncObjKeyCompare, /* key compare */
dictObjectDestructor, /* key destructor */
NULL, /* val destructor */
NULL /* allow to expand */
};
/* Like objectKeyPointerValueDictType(), but values can be destroyed, if
* not NULL, calling zfree(). */
dictType objectKeyHeapPointerValueDictType = {
dictEncObjHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictEncObjKeyCompare, /* key compare */
dictObjectDestructor, /* key destructor */
dictVanillaFree, /* val destructor */
NULL /* allow to expand */
};
/* Set dictionary type. Keys are SDS strings, values are not used. */
dictType setDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL /* val destructor */
};下面给大家截取一段字典中关于dictType具体使用的代码:
这是dict.c中的一段代码,它用于判断哈希表是否需要扩容:
//第985行
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}在判断是否需要扩容时,调用了dictTypeExpandAllowed方法
static int dictTypeExpandAllowed(dict *d) {
if (d->type->expandAllowed == NULL) return 1;
return d->type->expandAllowed(
_dictNextPower(d->ht[0].used + 1) * sizeof(dictEntry*),
(double)d->ht[0].used / d->ht[0].size);
}而在该方法中就是通过判断字典中dictType是否存在expandAllowed这个方法,如果存在就去调用具体的实现方法来确定dict是否被允许扩容,这就是一个dictType完整的多态应用场景
哈希表
一个哈希表里面可以有多个哈希表节点,跟Java类似,也是通过数组+链表也来解决hash冲突
它在源码中定义的结构如下:
//dict.h中第73行
//哈希表结构
typedef struct dictht {
dictEntry **table; //存储指向节点数组的指针
unsigned long size; //哈希表的长度,初始是4
unsigned long sizemask; //用于计算节点的下标索引值,这个字段值总为size - 1
unsigned long used; //存储hash表中节点的数量
} dictht;节点
redis中的key-value结构是通过节点(dictEntry)对象来实现的,节点中存储了key、value以及hash冲突后的其他链表节点
它的源码定义如下:
//dict.h中第50行
//哈希表节点对象
typedef struct dictEntry {
void *key; //存放指向key的指针
union { //value的数据结构
void *val; //存放指向value数据的指针
uint64_t u64; //uint64_t值
int64_t s64; //int64_t值
double d; //double值
} v;
struct dictEntry *next; //存放下一个节点的指针,形成链表
} dictEntry;从上图可以看出,节点对象对于value值的存储是经过精心设计的,它也有自己的结构。当value值为uint64_t、int64_t或double类型时,会直接存放在这些指定字段上。不需要像其他类型值一样,存放在内存中其他位置,然后通过val字段存放指针来指向实际值。这也有利于减少内存碎片
redis字典的整体数据结构其实就如下图:
rehash
当hash表中存放的键值对增加或减少时,如果触发到了扩容条件,那么就会进行扩容操作,此时就会进行rehash,将第二个哈希表(ht[1])扩容成第一个哈希表(ht[0])的两倍,然后将ht[0]中的节点元素转移到ht[1],当所有元素转移完成后,就代表rehash结束,此时就会将ht[1]赋给ht[0],然后重新初始化一个空ht[1]。
下面以源码来进行实例解析:
dictAddRaw方法,添加元素时,会获取将要放置的table数组下标,然后将元素以头插法放入table中
//dict.c中第319行
//字典添加方法,类似于Java中hashMap的put方法
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
//_dictKeyIndex方法计算出元素的数组索引值
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
//如果此时还在进行rehash(rehashidx不为-1),则将新元素添加至ht[1]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}_dictKeyIndex方法,获取数组下标时,会先调用_dictExpandIfNeeded方法判断该字典是否达到了扩容所需要的条件
//dict.c中第1028行
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
//判断字典是否是否需要扩容
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}_dictExpandIfNeeded方法,写明了扩容所需的条件,我们可以从下方方法内的第三行代码看出,扩容需要同时满足三个条件:
1.哈希表中的节点数量>=哈希表的数组长度
2.哈希表未禁止扩容,或者哈希表中的节点数量超过了哈希表数组长度的五倍
(注:dict_can_resize默认为1,代表允许扩容,为0则表示禁止扩容,dcict_force_resize_ratio的值为5,所以可以得出,就算设置了禁止扩容,但当节点数量过多时,也可能会扩容)
3.若字典的dictType实现了expandAllowed方法,则检查是否允许分配内存
当上述三个条件都满足时,就会调用字典的扩容方法
//dict.c中第986行
//字典扩容条件判断方法
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
//如果该字典正在扩容中,则返回OK
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
//因为在初始化时会将哈希表size设为0,然后将table设置为NULL,所以此时,会先将为NULL的哈希表数组 扩容成默认的4个长度数组
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
//如果 哈希表元素个数>=哈希表数组长度 并且 (未禁止hash扩容 || 元素个数>5倍的数组长度) 并且字典中数据类型dictType中实现了扩容方法,那就可以进行扩容
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
//dict.c中第978行
//判断字典的数据类型dictType是否实现了expandAllowed方法,如果实现了则检查是否允许分配
static int dictTypeExpandAllowed(dict *d) {
if (d->type->expandAllowed == NULL) return 1;
return d->type->expandAllowed(
_dictNextPower(d->ht[0].used + 1) * sizeof(dictEntry*),
(double)d->ht[0].used / d->ht[0].size);
}_dictExpand方法,这是写有扩容具体逻辑的方法,其中调用_dictNextPower方法得到扩容后的长度,在判断扩容后长度大于现在哈希表的长度时,就开始为新hash表分配内存设置默认值等等操作,然后再将这个新hash表赋给字典的ht[1],将字典rehash索引改为0,标志着重hash的开始,此字段会记录重hash的节点下标,直至所有节点都rehash完成迁移到新的哈希表中才算完结
//dict.c中第191行
int dictExpand(dict *d, unsigned long size) {
return _dictExpand(d, size, NULL);
}
//dict.c中第145行
//扩容方法
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
//如果已经在扩容,或者传过来的size小于当前的节点个数则返回失败
//size传过来时是节点个数+1,如果它小于节点个数,应该是出现了其他问题,所以返回了失败
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
//创建新的哈希表,计算出它的长度并为其分配内存
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
//校验新哈希表长度要大于ht[0]的长度,不然这个扩容就无意义了
/* Detect overflows */
if (realsize < size || realsize * sizeof(dictEntry*) < realsize)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
if (malloc_failed) {
n.table = ztrycalloc(realsize*sizeof(dictEntry*));
*malloc_failed = n.table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
//将新hash表赋给ht[1],且将字典表的重hash索引设置为0,意味着要从第0个开始进行rehash了
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}从_dictNextPower中,我们可以看出,扩容基本上是以双倍进行扩容
//dict.c中第1009行
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
//dict.h中第105行
//变量,哈希表的初始长度,每次扩容以它的两倍进行扩容
#define DICT_HT_INITIAL_SIZE 4渐进式rehash
redis中的扩容并不是一次性完成的,因为redis作为缓存数据库,如果数据量大的情况下,在添加元素时触发了扩容,此时若是等待其扩容且rehash迁移所有节点,那么会消耗不少时间,且这段时间里redis会暂停对外服务,所以为了避免这种情况,redis使用了渐进式rehash
渐进式rehash就是将一次完成的操作,分开多次进行
例如上面介绍的dictAddRaw方法,在添加节点元素时,会先判断字典是否在进行rehash,如果在进行,那么就会调用一下单步rehash方法(即每次rehash一个节点的方法)将一个节点元素从旧哈希表(ht[0])迁移至新哈希表(ht[1]),且新增的节点也会放置在ht[1]中,ht[0]的节点只出不进,那么在多次新增元素后,ht[0]的元素会越来越少,直至没有,此时就说明rehash已经结束,这是再将ht[1]赋给ht[0],然后初始化一个哈希表作为ht[1]以便下次rehash
这种循序渐进,一步步进行的rehash就叫做渐进式rehash
//dict.c中第287行
//只调用一次rehash的方法
//此方法在新增、删除元素时调用,每次操作就rehash一个旧的节点元素
//这样就能一步步将旧的节点元素转移到新hash表中
static void _dictRehashStep(dict *d) {
if (d->pauserehash == 0) dictRehash(d,1);
}
//dict.c中第211行
//rehash方法,包含具体的rehash逻辑
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
//进行n次rehash,n由外部调用者决定,例如添加时,就会传1,那么就会进行一次rehash
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
//取出当前要rehash的旧表节点元素
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
//如果节点存在,则进行rehash
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
//计算出新哈希表的数组索引
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
//将旧表的节点元素迁移至新表
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
//如果旧表中没有节点元素了,则释放旧表内存
zfree(d->ht[0].table);
//此时rehash已经结束,那么将新表赋给ht[0],然后初始化一个表赋给ht[1]以便于下次rehash
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
//将字典设置为不在rehash中
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}当然,按上述方案来一步步rehash,整体效果不错的,但由于只会在新增删除时才会rehash一个节点,所以要rehash完全部节点是个很漫长的过程。因此,redis还提供了一个按时间来rehash的方法:
//dict.c中第266行
//按时间来进行字典的rehash操作
//ms参数为毫秒数,例如传入5000,那么就会一直rehash直到超过5秒才停止
int dictRehashMilliseconds(dict *d, int ms) {
if (d->pauserehash > 0) return 0;
//先获取一个开始时间
long long start = timeInMilliseconds();
int rehashes = 0;
//每次进行100个rehash
while(dictRehash(d,100)) {
rehashes += 100;
//如果耗时超过了传入的时间,那么就退出rehash,否则将再进行100次rehash
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}该方法是按时间来rehash的,根据传入的时间(按毫秒算,例如:5000就是5秒)来进行每100次的rehash,每执行100次rehash就会判断耗时是否已经超过传入值,超过则停止rehash,否则进入下一轮的100次rehash

















 4254
4254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









