






目录
前言
该实验项目为大学课程实验,经个人整理分享。
⭐完整项目链接:github
一、关联分析的基本概念
什么是关联分析?
关联分析用于发现海量数据中项集之间有趣的关联关系或相关关系。假设下图是某超市统计的顾客最常同时购买的商品集合
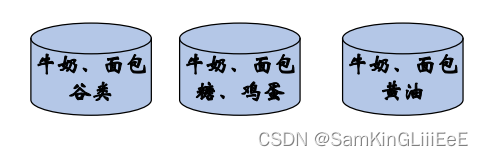
那么其中的关联关系用关联规则表示:[牛奶->面包]
关联规则的评价指标
关联规则两大评价指标:支持度与置信度。
- 支持度:项出现次数占总项集的比例
- 置信度:关联规则的先验概率
假设 [牛奶->面包] 支持度=2%,置信度=60%,用自然语言可表达为:“全部事务的2%同时购买了牛奶和面包,购买牛奶的顾客60%也购买面包”
二、关联挖掘算法
项的存放次序:
关联规则挖掘算法常常假设事务中的项按字典次序存放,项集按字典序从最左项到最右项依次指定,避免枚举重复的事务项集。
假设事务集为{a, b, c, d, e},[ ]表示随后可跟的项
3-项集的第一项(最左项)只能是a, [b, c, d, e]、b, [c, d, e]、c, [d, e]
前二项只能是a, b, [c, d, e]、a, c, [d, e]、a, d, [e]、b, c, [d, e]、b, d, [e]、c, d, [e]
3-项集只能是{a, b, c}、{a, b, d}、{a, b, e}、{a, c, d}、{a, c, e}、{a, d, e}、{b, c, d}、{b, c, e}、{b, d, e}、{c, d, e}
挖掘方法
给定事务的集合T,找出支持度大于等于 min_sup 并且置信度大于等于 min_confidence 的所有关联规则。
挖掘步骤
关联规则挖掘主要包括两个步骤:
- 找出所有频繁项集(支持度测试),这些项集的支持度不小于最小支持度阈值。
- 由频繁项集产生强关联规则(置信度测试),这些规则必须满足最小支持度和最小置信度。
 第一步骤是关键,它的效率影响整个关联规则挖掘算法的效率因此,关联规则挖掘算法的核心是频繁项集产生方法
频繁项集的产生方法
格结构:枚举所有可能项集的结构
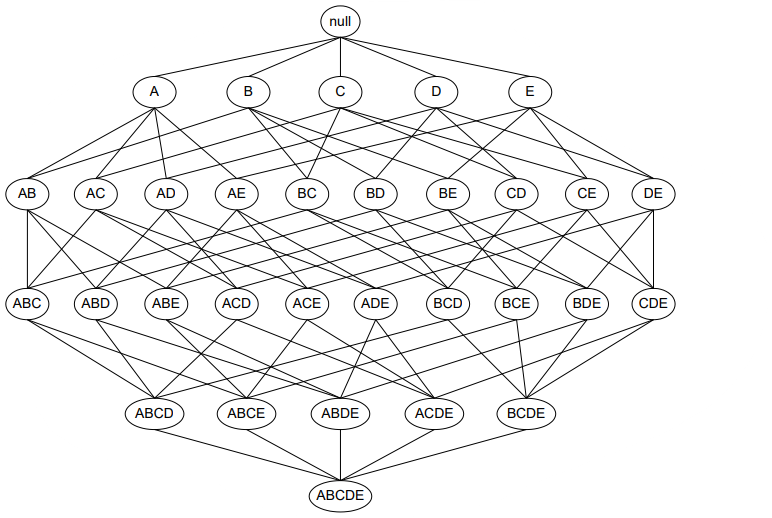
格结构中的每个项集都是一个候选的频繁项集,d个项,有 2^d-1个可能的候选项集。
蛮力方法
- 计算每个规则的支持度和置信度
- 去除不满足min_sup和min_conf阈值的规则
缺点显而易见,资源消耗多,计算代价巨大。有没有什么更好的方法呢?
Apriori算法
Apriori原理:如果一个项集是频繁的,则它的所有非空子集一定也是频繁的
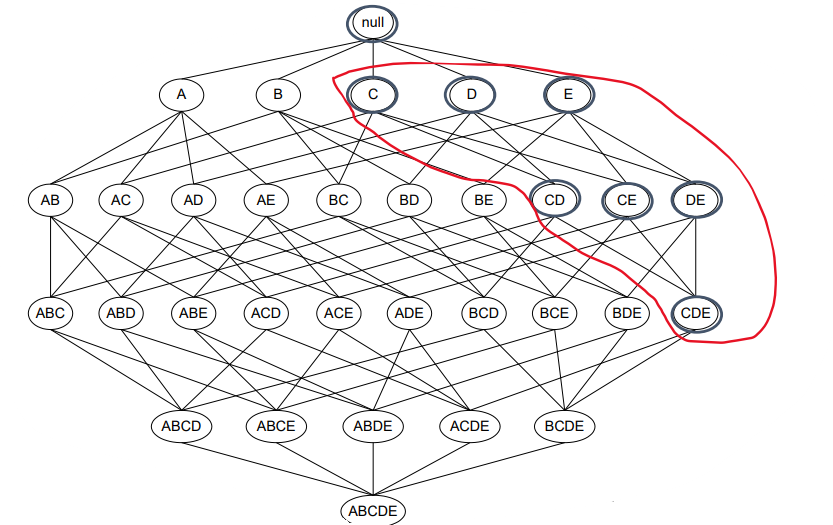
如果某个(k+1)项集是频繁项集,则它的所有k项集一定也是频繁项集
反之,如果某个k项集不是频繁项集,则包含它的所有(k+1)项集也不是频繁项集
所有包含该项集的超集可以被立即剪枝
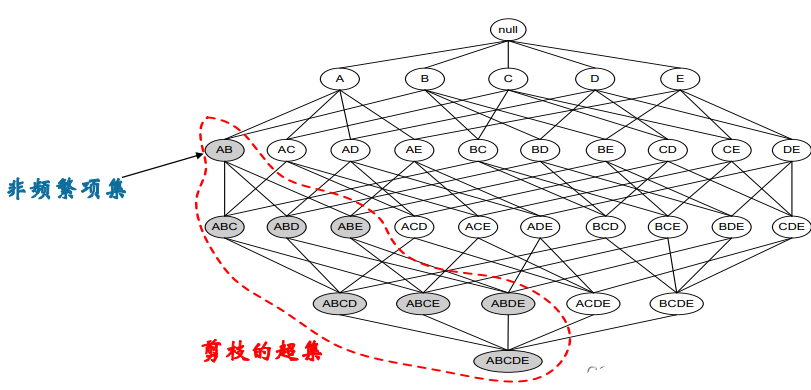
Apriori算法思想
Apriori算法的基本思想是通过对数据库的多次扫描来计算项集的支持度,发现所有的频繁项集从而生成关联规则。基本步骤如下:
- 首先,扫描一次事务集合,找出频繁1项集集合L1
- 基于L1,产生所有可能频繁的2项集,即候选2项集集合C2(连接)
- 基于L1,优化C2(剪枝),基于Apriori性质过滤掉一些候选
- 基于C2,再扫描一次事务集合,找出频繁2项集集合L2。
依次类推,直至不能找到频繁项集为止。最后,在所有频繁项集中产生强关联规则。
Apriori算法实现
该Apriori算法封装在一个matlab函数中,函数输入有两个,分别为布尔矩阵data、商品名列表item。布尔矩阵data中行表示事务,列表示项。当某一事务包含某一项时,对应列即为1,反之为0。即data(i, j)=1时,表示第i个事务中包含第j项。输出为频繁项集以及强关联规则。
Apriori.m
function Apriori(data, item)
min_sup=input("请输入最小支持度\n"); % 最小支持度(未除以n)
min_con=input("请输入最小置信度\n"); % 最小置信度(已除以n)
[n,m]=size(data);
for i=1:n
x{i}=find(data(i,:)==1); % 求每行购买商品的编号
end
k=0;
while 1
k=k+1;
L{k}={};
if k==1
C{k}=(1:m)';
else
[nL,mL]=size(L{k-1});
cnt=0;
for i=1:nL
for j=i+1:nL
tmp=union(L{k-1}(i,:),L{k-1}(j,:)); % 两集合并集
if length(tmp)==k
cnt=cnt+1;
C{k}(cnt,1:k)=tmp;
end
end
end
C{k}=unique(C{k},'rows'); % 去掉重复的行
end
[nC,mC]=size(C{k}); % 候选集大小
for i=1:nC
cnt=0;
for j=1:n
if all(ismember(C{k}(i,:),x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt=cnt+1;
end
end
C_sup{k}(i,1)=cnt; % 每行存候选集对应的支持度
end
L{k}=C{k}(C_sup{k}>=(9835*min_sup),:);
if isempty(L{k}) % 这次没有找出频繁项集
break;
end
if size(L{k},1)==1 % 频繁项集行数为1,下一次无法生成候选集,直接结束
k=k+1;
C{k}={};
L{k}={};
break
end
end
fprintf("\n");
for i=1:k
fprintf("第%d轮的候选集为:",i); C{i}
fprintf("第%d轮的频繁集为:",i); L{i}
end
fprintf("第%d轮结束,最大频繁项集为:",k);
L{k-1}
[nL,mL]=size(L{k-1});
rule_count=0;
for p=1:nL % 第p个频繁集
L_last=L{k-1}(p,:); % 之后将L_last分成左右两个部分,表示规则的前件和后件
cnt_ab=0;
for i=1:n
if all(ismember(L_last,x{i}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_ab=cnt_ab+1;
end
end
len=floor(length(L_last)/2);
for i=1:len
s=nchoosek(L_last,i); % 选i个数的所有组合
[ns,ms]=size(s);
for j=1:ns
a=s(j,:);
b=setdiff(L_last,a);
[na,ma]=size(a);
[nb,mb]=size(b);
cnt_a=0;
for i=1:na
for j=1:n
if all(ismember(a,x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_a=cnt_a+1;
end
end
end
pab=cnt_ab/cnt_a;
if pab>=min_con % 关联规则a->b的置信度大于等于最小置信度,是强关联规则
rule_count=rule_count+1;
rule(rule_count,1:ma)=a;
rule(rule_count,ma+1:ma+mb)=b;
rule(rule_count,ma+mb+1)=ma; % 倒数第二列记录分割位置(分成规则的前件、后件)
rule(rule_count,ma+mb+2)=pab; % 倒数第一列记录置信度
end
cnt_b=0;
for i=1:na
for j=1:n
if all(ismember(b,x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_b=cnt_b+1;
end
end
end
pba=cnt_ab/cnt_b;
if pba>=min_con % 关联规则b->a的置信度大于等于最小置信度,是强关联规则
rule_count=rule_count+1;
rule(rule_count,1:mb)=b;
rule(rule_count,mb+1:mb+ma)=a;
rule(rule_count,mb+ma+1)=mb; % 倒数第二列记录分割位置(分成规则的前件、后件)
rule(rule_count,mb+ma+2)=pba; % 倒数第一列记录置信度
end
end
end
end
fprintf("当最小支持度为%d,最小置信度为%.2f时,生成的强关联规则:\n",min_sup,min_con);
fprintf("强关联规则\t\t置信度\n");
[nr,mr]=size(rule);
for i=1:nr
pos=rule(i,mr-1); % 断开位置,1:pos为规则前件,pos+1:mr-2为规则后件
for j=1:pos
if j==pos
fprintf("%s",item{rule(i,j)});
else
fprintf("%s∧",item{rule(i,j)});
end
end
fprintf(" => ");
for j=pos+1:mr-2
if j==mr-2
fprintf("%s",item{rule(i,j)});
else
fprintf("%s",item{rule(i,j)});
end
end
fprintf("\t\t%f\n",rule(i,mr));
end
end
main.m
close all;
clear all;
clc;
filename = 'Groceries1.csv';
fileID = fopen(filename);
X = textscan(fileID,'%s','Delimiter',',');
item=unique(X{1,1});
fclose(fileID);
X = importdata(filename);
data=[];custom={};
for i =(1:length(X))
custom(1,i)=textscan(X{i,1},'%s','Delimiter',',');
end
for i =(1:length(custom))
for j=(1:length(custom{1,i}))
for k=(1:length(item))
if strcmp(custom{1,i}{j,1},item{k,1})
data(i,k)=1;
end
end
end
end
Apriori(data,item);
实验验证
输入:

运行结果:

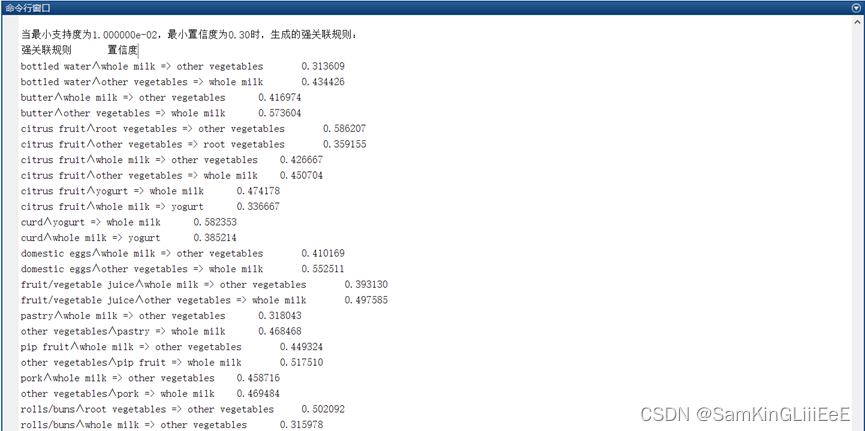
最小支持度与置信度对输出和算法所用时间的影响
根据Apriori算法原理,最小支持度为项出现次数占总项集的比例,最小置信度则为关联规则所需满足的最小的“概率”。因此,可以推断,随着最小支持度与置信度的增大,对于项集的要求也就更为苛刻,满足该要求的频繁项集也越少。
将对最小支持度与置信度分别增大为0.02、0.5后再次运行:

运行结果:

分别改变最小支持度与置信度,观察其影响
- 支持度不变,置信度增大
 第四轮后的最大频繁项集
第四轮后的最大频繁项集

生成的强关联规则如下:
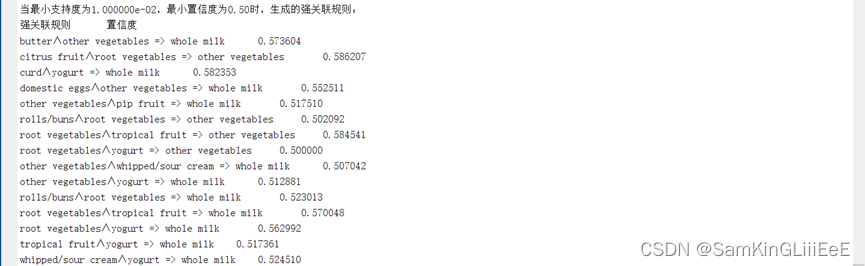
- 置信度不变,支持度增大

生成的最大频繁项集

生成的强关联规则

可以发现最小支持度的增大对最大频繁项集与强关联规则都产生了巨大的影响,两者都明显减少。
实验总结
通过以上实验我们可以得知置信度的增大只对生产的强关联规则有影响,不影响最大频繁项集。而支持度的增大则会对两者都产生影响。这一现象是由于Apriori算法运行的原理:以最小支持度来筛选频繁项集,再根据最小置信度从频繁项集中选择出强关联规则。因此,当变动仅限于最小置信度时,并不会影响频繁项集的选择;而变动为最小支持度时,即使最小置信度不变,但由于支持度增大导致频繁项集的减少,部分能满足置信度的强关联规则由于它所属的频繁项集未能满足支持度要求而被淘汰,所能产生的强关联规则也随之变少。
















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









