







 本文深入探讨了强化学习中动态规划方法求解马尔科夫决策过程(MDP)的策略迭代与价值迭代的区别,通过GridWorld游戏实例,对比了两种算法的计算复杂度和迭代策略。策略迭代先评估后调整策略,价值迭代则边迭代边调整,通常更高效。
本文深入探讨了强化学习中动态规划方法求解马尔科夫决策过程(MDP)的策略迭代与价值迭代的区别,通过GridWorld游戏实例,对比了两种算法的计算复杂度和迭代策略。策略迭代先评估后调整策略,价值迭代则边迭代边调整,通常更高效。
强化学习笔记(二)动态规划法求解MDP
在MDP的内容中已经证明了一定存在best policy,并且递推公式是最终收敛到best policy的。那么动态规划是一个比较直观求解MDP的方法。我对于Dynamic Programming不是很了解,也没有刷过Leetcode的题目。很多文章在讲解的时候提到了“分治”,“递推/递归”,“子问题”等思想。个人比较粗糙地理解就是类似数值分析中的迭代,若我们有一个k步到k+1步的递推关系式,精确解又确定有,那么从任意一个初值,我们肯定能迭代到精确解。
整讲课程最为凝练的内容应该就是下表:策略评估、策略迭代和价值迭代。为了将概念阐述得更清楚,David Sliver用了很多的公式、例子和图片,反而弄得像我这种不太聪明的听众更加糊涂了[汗]. 我认为很重要的是弄懂GridWorld那个经典的例子,其余的就迎刃而解了。
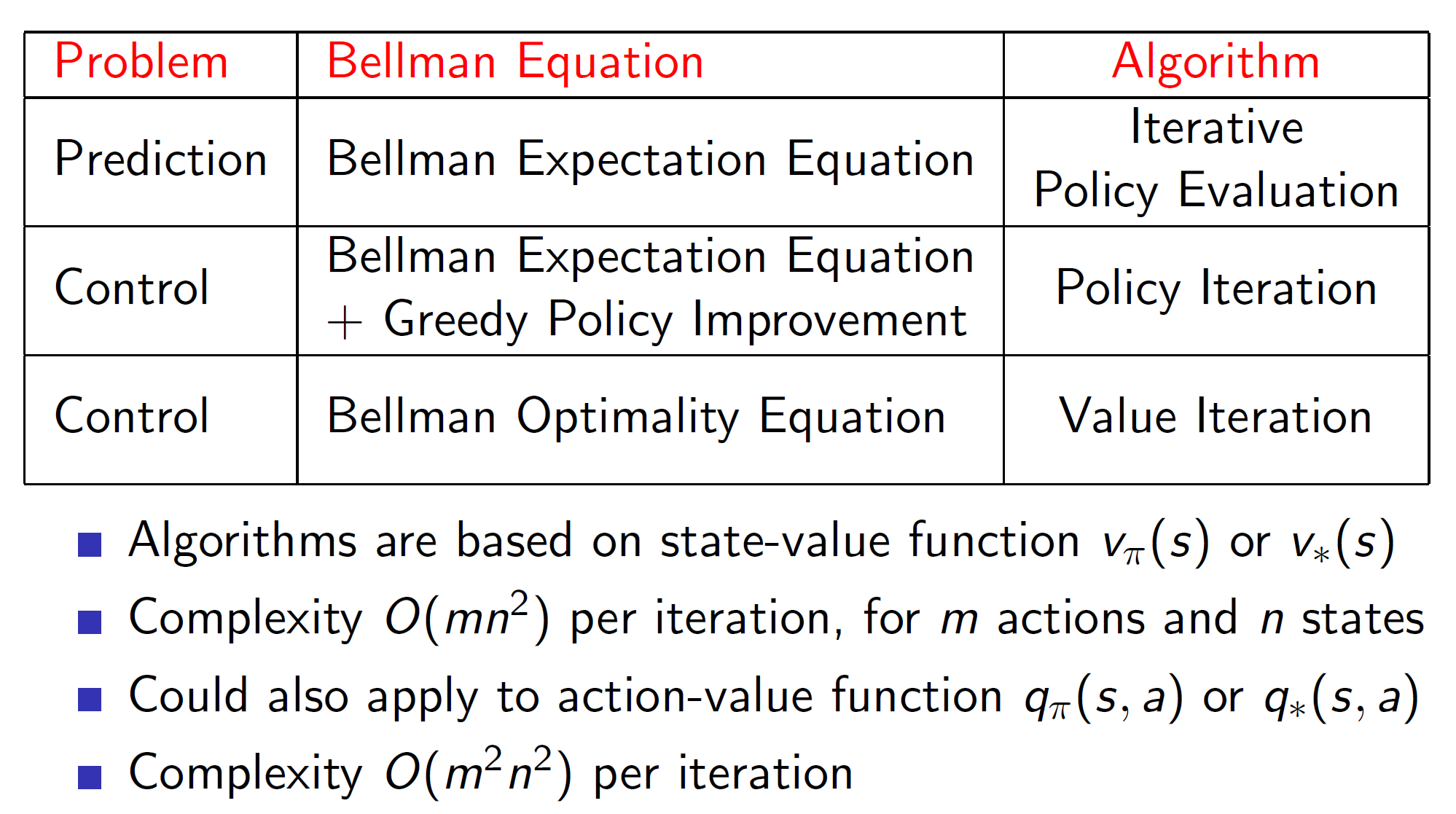
Q1:策略迭代和价值迭代的区别在哪?
- 策略迭代是先进行策略评估,即初始化状态价值函数,结合状态转移概率、奖励值等参数,依据给定的策略,结合贝尔曼方程进行迭代,得到最终价值 V ∗ V* V∗. 在最终价值的基础上使用贪婪法,即可得到最优策略。也就是等价值收敛后再调整策略;而价值迭代是随着状态价值的迭代及时调整策略,这样无需等到价值的收敛。
- 两者在计算复杂度上有一定的差异。如上图,价值迭代在每一轮的迭代上计算复杂度是高于策略迭代的。但是价值迭代的轮数会小于策略迭代,一般来说价值迭代还是更快。
开始我并不明白“依据给定的策略”这句话的含义。给定是如何给定,随机给定策略最终的价值函数也能反映出唯一的最优策略吗?貌似之后的两页PPT证明了,从任意一个确定性策略出发,策略一定会不断被improve最终达到 π ∗ \pi* π∗.


附:GridWorld游戏的MATLAB代码
自己稍微写了一点,算法效率不高。
% find_surround.m
% 找到方块的四个相邻位置,上下左右
function index_mat = find_surround(num_rows, num_cols, index_i, index_j)
index_mat = zeros(4,2);
if(index_i==1)
index_mat(1,:) = [index_i, index_j];
index_mat(2,:) = [index_i + 1, index_j];
index_mat(3,:) = [index_i, index_j - 1];
index_mat(4,:) = [index_i, index_j + 1];
end
if(index_i==num_rows)
index_mat(1,:) = [index_i - 1, index_j];
index_mat(2,:) = [index_i, index_j];
index_mat(3,:) = [index_i, index_j - 1];
index_mat(4,:) = [index_i, index_j + 1];
end
if(index_j==1)
index_mat(1,:) = [index_i - 1, index_j];
index_mat(2,:) = [index_i + 1, index_j];
index_mat(3,:) = [index_i, index_j];
index_mat(4,:) = [index_i, index_j + 1];
end
if(index_j==num_cols)
index_mat(1,:) = [index_i - 1, index_j];
index_mat(2,:) = [index_i + 1, index_j];
index_mat(3,:) = [index_i, index_j - 1];
index_mat(4,:) = [index_i + 1, index_j];
end
if(index_i==1 && index_j == num_cols)
index_mat(1,:) = [index_i, index_j];
index_mat(2,:) = [index_i + 1, index_j];
index_mat(3,:) = [index_i, index_j - 1];
index_mat(4,:) = [index_i, index_j];
end
if(index_i==num_rows && index_j == 1)
index_mat(1,:) = [index_i - 1, index_j];
index_mat(2,:) = [index_i, index_j];
index_mat(3,:) = [index_i, index_j];
index_mat(4,:) = [index_i, index_j+1];
end
if( index_i >1 && index_i<num_rows && index_j >1 && index_j<num_cols)
index_mat(1,:) = [index_i - 1, index_j];
index_mat(2,:) = [index_i, index_j - 1];
index_mat(3,:) = [index_i, index_j + 1];
index_mat(4,:) = [index_i + 1, index_j];
end
% gridworld.m
clear all,
%% 设置gridworld的尺寸,超参数
num_rows = 4;
num_cols = 4;
reward = -1;
gamma = 1;
p = 1/4;
value_grid = zeros(num_rows, num_cols); % 存储老的状态价值
value_new = zeros(num_rows, num_cols); % 存储迭代后新的状态价值
action_grid = cell(num_rows, num_cols);
q = zeros(1,4); % 动作价值函数
% 按照上下左右的规则,存储动作,1代表执行,0代表不执行
for i = 1:num_rows
for j = 1:num_cols
action_grid(i, j) = cellstr('1111');
end
end
action_grid(1,1) = cellstr('0000');
action_grid(num_rows, num_cols) = cellstr('0000');
%% 策略评估的迭代更新
times = 20;
backup_seq = zeros(num_rows, num_cols, times); % Memory bank
for t = 1:times
for i = 1:num_rows
for j = 1:num_cols
if((i==1 && j==1) || (i==num_rows && j == num_cols))
else
index_mat = find_surround(num_rows, num_cols, i, j); % 根据方块位置找到相邻的四个方块(考虑边界问题)
total = 0;
for ii=1:4
total = total + p* value_grid(index_mat(ii,1), index_mat(ii,2));
end
value_new(i, j) = reward + total; % 贝尔曼方程更新
backup_seq(i,j,t) = value_new(i, j); % 保存到memory bank
end
end
end
value_grid = value_new; %老的价值函数更新
end

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









