







作者:王小草
笔记时间:2019年1月21日
1 价值函数的计算困难
1.1 最优值函数的递归定义
先来回忆一下最优状态值函数和最优状态-行为值函数。
-
最优状态价值函数:考虑这个状态下,可能发生的所有后续动作,并且挑最好的动作来执行的情况下,这个状态的价值。
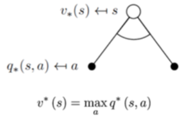
-
最优状态-动作值函数:在这个状态下执行了一个特定的动作,并且该动作的后续状态总能选取最好的动作来执行,所得到的长期价值
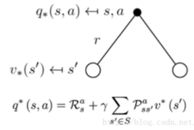
以上两个价值函数,对应马尔科夫过程中的两个概率转移矩阵:状态-动作转移和动作-状态转移。
状态-动作转移是指在一个状态下有多个动作,也就是策略,每个动作有一个概率,所有动作相加概率为1,这个过程对应状态价值函数,其中最优的动作带来的价值就是最优状态价值。
动作-状态概率矩阵是指在做了某个动作a之后,下一个状态是不确定的,有多重可能,会有状态s转到状态s’的概率(比如给花浇水这个动作,有0.9的可能它会到茁壮成长的状态,0.1的可能还是会到死掉的状态),这个过程对应的是状态-动作值函数。
1.2 价值函数的计算困难
用bellman方程来直接求价值函数是比较困难的。
bellman方程:
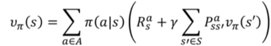
忽略策略的随机性,即π=1,bellman方程可简化为:
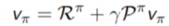
对V求解:
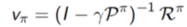
以上求解,复杂度为O(n^3),真实场景中,P和R规模都太大,很难直接求解.
1.3 迭代计算价值函数
直接使用bellman方程求解价值函数显得不现实了,于是需要使用其他更优的方法去求解:
-
动态规划:已知环境P和R,对每步进行迭代(实际应用中很少使用动态规划来解决大规模强化学习问题)
-
Monte Carlo法:没有经验学习,但必须有终止任务,任务结束后对所有回报进行平均。
-
时序差分法:没有环境模型,根据经验学习。每步进行迭代,不需要等任务完成。
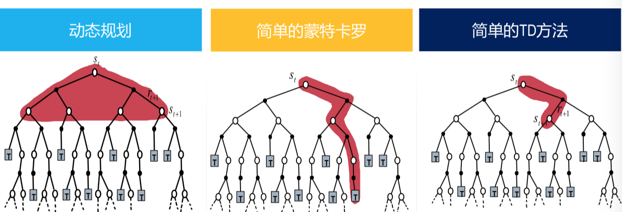
本文先对动态规划法进行价值函数的计算进行详细讲述。在第三篇,和第四篇,会分别对蒙特卡洛和时序差分法做详细介绍。
2 动态规划法
-
思想
把复杂的问题分阶段进行简化,迭代进行中,每次迭
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









