







目录
损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
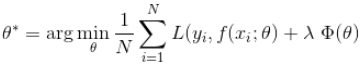
其中,前面的均值函数表示的是经验风险损失函数,L表示的是损失函数,后面的是正则化项。
损失函数
Pixel-wise损失函数
Pixel-wise损失函数用于计算预测图像和目标图像的像素间损失。主要有 L1损失函数、L2损失函数和交叉熵损失函数。由于这些损失函数分别对每个像素向量的类预测进行评估,然后对所有像素进行平均,因此它们断言图像中的每个像素都具有相同的学习能力。这在图像的语义分割中特别有用,因为模型需要学习像素级的密集预测。
L1损失函数和L2损失函数
在深度学习中,L1损失函数和L2损失函数一般用于回归。
L1损失函数,即为最小绝对值偏差(MAE)。表达式如下:
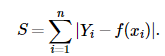
L1损失函数由于导数不连续,可能存在多个解,当数据集有一个微笑的变化,解可能会有一个很大的跳动,L1的解不稳定。
L2损失函数,即为最小平方误差(MSE)。表达式如下:
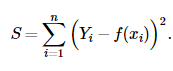
L2损失函数对异常点比较敏感,因为L2将误差平方化,使得异常点的误差过大,模型需要大幅度的调整,这样会牺牲很多正常的样本。
训练过程中,容易出现过拟合现象。
| L1损失函数 | L2损失函数 |
|---|---|
| 鲁棒 | 不是非常鲁棒 |
| 不稳定解 | 稳定解 |
| 可能多个解 | 总是一个解 |
交叉熵损失函数
在深度学习中,交叉熵函数一般用于分类。(相对MSE而言,曲线整体呈单调性,是个凸函数,loss越大,梯度越大。便于梯度下降反向传播,利于优化。所以一般针对分类问题采用交叉熵作为loss函数。)
交叉熵损失函数刻画的是两个概率分布之间的距离。如下式,交叉熵刻画的的是通过概率分布q来表达概率分布p的困难程度,其中p为真实分布,q为预测,交叉熵越小,两个概率分布越接近。
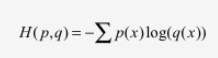
在神经网络中怎样把前向传播得到的结果也变成概率分布呢?Softmax回归就是一个非常有用的方法。
假设原始的神经网络的输出为

那么经过Softmax回归处理之后的输出为:
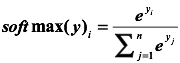
这样就把神经网络的输出也变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离了。
在深度学习中,二分类通常通过sigmoid函数作为预测的输出,得到预测的分布,那对于多分类得到预测的分布则采用softmax。
Sigmoid =多标签分类问题=多个正确答案=非独占输出
Softmax =多类别分类问题=只有一个正确答案=互斥输出
Perceptual损失函数
Johnson et al (2016),Perceptual损失函数用于比较看起来相似的两个不同的图像,就像相同的照片,但移动了一个像素或相同的图像使用了不同的分辨率。在这种情况下,虽然图像非常相似,pixel-wise损失函数将输出一个大的误差值。而Perceptual损失函数比较图像之间的高级感知和语义差异。
考虑一个图像分类网络如VGG,已经在ImageNet的数以百万计的图像数据集上训练过,第一层的网络往往提取底层的特征(如线,边缘或颜色渐变)而最后的卷积层应对更复杂的概念(如特定的形状和模式)。根据Johnson等人的观点,这些在前几层捕获的低层次特征对于比较非常相似的图像非常有用。
例如,假设你构建了一个网络来从输入图像重构一个超分辨图像。在训练期间,你的目标图像将是输入图像的超分辨率版本。你的目标是比较网络的输出图像和目标图像。为此,我们将这些图像通过一个预先训练好的VGG网络传递,并提取VGG中前几个块的输出值,从而提取图像的底层特征信息。这些低级的特征张量可以通过简单的像素级损失来进行比较。

Perceptual损失的数学表达式
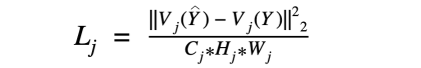
其中,
V
j
(
Y
)
V_{j}(Y)
Vj(Y)表示VGG网络第j层在处理图像Y时的激活情况。我们使用L2损失的平方,根据图像的形状归一化,比较了ground truth图像Y和预测图像Y^的激活情况。
content-style损失函数
已经发现,CNNs在较高的层次上捕获内容的信息,而较低的层次更关注单个像素值。
因此,我们使用一个或多个CNN顶层,计算原始内容图像©和预测输出§ 的激活图。
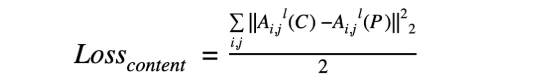
同样,通过计算预测图像§和风格图像(S)的下一级特征图的L2距离,可以计算出风格损失,

最终得到的损失函数定义为:
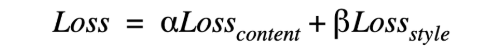
GAN损失
Min-Max损失函数
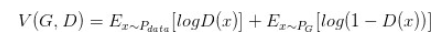
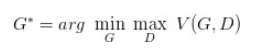
循环一致性损失
循环一致性损失出自CycleGAN, 主要由
L
G
A
N
L_{GAN}
LGAN和
L
c
y
c
L_{cyc}
Lcyc两部分构成。
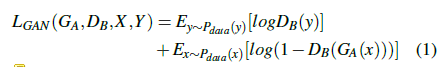
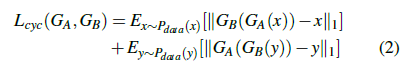
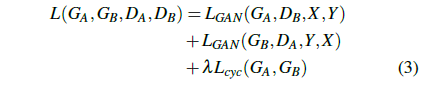
正则化
训练过程中,容易出现过拟合现象。一般采用以下三种方法:
- 数据增强
- 减少变量个数,去掉不重要的变量(dropout)
- 正则化项:保留所有变量,但减小特征变量的数量级。这种处理方法更合适,因为实际所有变量对结果都有一定贡献,只是有些变量对结果的影响很小。
正规化背后的思路:这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。
这个链接对于正则化的介绍非常详细,值得参考。
正则项一般分为L1正则化和L2正则化两种,或者 L1范数 和 L2范数。
L1正则化
使用L1正则化的模型建叫做Lasso Regularization(Lasso回归),直接在原来的损失函数基础上加上权重参数的绝对值。
假设损失函数为
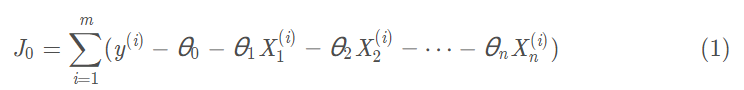 则Lasso Regularization为
则Lasso Regularization为
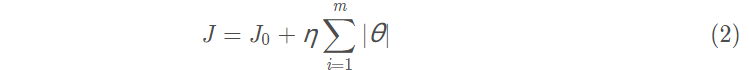
令
L
1
L_{1}
L1等于第二项,则
J
=
J
0
+
L
1
J=J_{0}+L_{1}
J=J0+L1,此时任务变成在
L
1
L_{1}
L1约束下求出J取得最小值的解。

最终的损失函数就是求等高圆圈+黑色黑色矩形的和的最小值。由图可知等高圆圈+黑色黑色矩形首次相交时,J取得最小值。
L2正则化
使用L2正则化的模型叫做Ridge Regularization(岭回归),直接在原来的损失函数基础上加上权重参数的平方和:
令损失函数为
J
0
J_{0}
J0,则Ridge Regularization为:
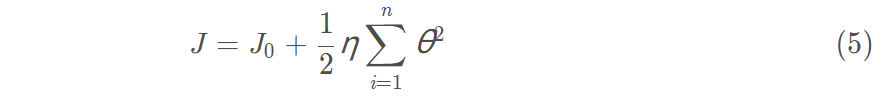
使最终的损失函数最小,要考虑
J
0
J_{0}
J0和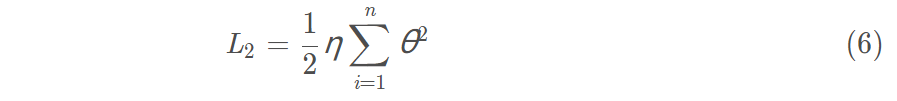
两个因素,最终的损失函数就是求等高 圆圈+黑色圆圈的和的最小值。由图可知两个圆相交时,J取得最小值。

平衡多个loss
Bayesian框架
从预测不确定性的角度引入Bayesian框架,根据各个loss分量当前的大小自动设定其权重。可参考 Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics(CVPR2018)
两个loss为例,
σ
1
\sigma_{1}
σ1和
σ
2
\sigma_{2}
σ2由网络输出,由于整体loss要求最小,所以式子前两项希望
σ
\sigma
σ越大越好,第三项希望
σ
\sigma
σ越小越好。当两个loss中某个比较大时,其对应的
σ
\sigma
σ也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。
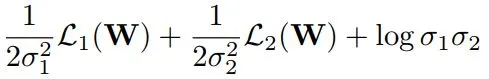
focal loss
关于focal loss可参考该篇博客
一开始训练的时候不要用focal loss,要确保网络的权重更新到一定时候再加入 focal loss。
分多个阶段训练。stage 0 : task 0, stage 1: task 0 and 1. 以此类推。在stage 1以后都用的是focal loss。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









