







目录
1.引言与背景
近年来,随着深度学习技术的飞速发展,无监督图像到图像转换任务的研究备受关注。这类任务旨在通过学习一种映射关系,使源域图像能够被自动转化为具有目标域特征的图像,而无需对配对的源-目标图像进行标注。在诸多无监督图像转换方法中,Cycle-Consistent Generative Adversarial Networks(简称CycleGAN)以其独特的循环一致性约束和高效的双生成器-判别器结构,展现出卓越的跨域图像转换能力。本文将深入探讨CycleGAN算法的理论基础、工作原理、实现细节、优缺点、应用案例,并与其他相关算法进行对比,最后展望其未来发展趋势。
2.定理
在CycleGAN的背景下,我们可以提及与其密切相关的两个数学概念:Gromov-Hausdorff距离和Wasserstein距离。虽然这两个并非严格意义上的定理,但它们为GANs的设计提供了理论依据。
Gromov-Hausdorff距离是一种衡量两个度量空间之间差异的泛函距离,常用于比较不同形状、大小的几何对象之间的相似性。尽管CycleGAN并未直接利用Gromov-Hausdorff距离,但它所追求的目标——在保持源图像结构信息的前提下进行风格转换,与Gromov-Hausdorff距离强调的空间结构保真度理念相契合。
Wasserstein距离(也称Earth Mover's Distance,EMD)是一种衡量概率分布之间差异的有效度量,尤其适用于处理非连续或非正态分布。Wasserstein GAN(WGAN)首次引入了这种距离来优化生成器和判别器的目标函数,从而解决了传统GAN训练过程中的模式崩溃和梯度消失问题。尽管CycleGAN并未直接采用Wasserstein距离,但其核心思想——通过最小化源域和目标域图像分布之间的距离来进行图像转换,与Wasserstein GAN的理念相通。
3.算法原理
CycleGAN由两对生成器-判别器网络组成:一对用于从源域到目标域的转换(和
),另一对用于从目标域到源域的反向转换(
和
)。其主要创新点在于引入了循环一致性损失(Cycle Consistency Loss),它确保经过两次转换(源→目标→源)后的图像尽可能接近原始源图像,以及经过反向转换(目标→源→目标)后的图像尽可能接近原始目标图像。具体来说,CycleGAN包含以下三个关键损失项:
-
对抗损失(Adversarial Loss):每个生成器都试图欺骗对应的判别器,使其无法区分真实图像和转换后的图像。这是GAN的基本组成部分,旨在推动生成器生成与目标域风格一致的图像。
对于
,对抗损失为:
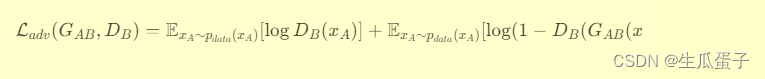
-
循环一致性损失(Cycle Consistency Loss):通过计算源图像经过两次转换后的重构误差,以及目标图像经过反向转换后的重构误差,强制生成器保持图像内容的结构一致性。
循环一致性损失为:
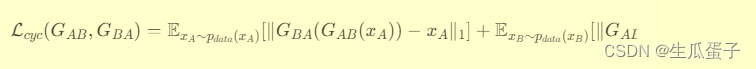
-
总损失(Total Loss):将对抗损失和循环一致性损失结合,得到生成器和判别器的最终优化目标。
生成器总损失为:
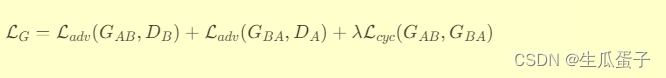
判别器损失仅为对抗损失,分别对应于两个判别器。
4.算法实现
CycleGAN的实现通常基于深度学习框架如TensorFlow或PyTorch。以下是一个简化的PyTorch实现步骤:
-
定义网络结构:构建两对生成器(如基于ResNet或U-Net的编码-解码结构)和判别器(如PatchGAN)。
-
初始化模型和优化器:使用随机权重初始化生成器和判别器,配置Adam或其他优化器。
-
数据准备:加载源域和目标域的无配对图像数据集,并创建数据加载器。
-
训练循环:
- 更新判别器:对于每个判别器,分别计算真实图像和生成图像的损失,反向传播并更新参数。
- 更新生成器:计算循环一致性损失和对抗损失之和,反向传播并更新参数。
-
模型保存与评估:在训练过程中定期保存模型,并通过可视化转换结果评估性能。
在Python中实现CycleGAN通常涉及使用深度学习框架如TensorFlow或PyTorch。以下是一个使用PyTorch框架的简化版CycleGAN实现示例,包括关键模块的代码讲解:
Python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torchvision.utils import save_image
# 1. 定义网络结构
class Generator(nn.Module):
def __init__(self, in_channels, out_channels, n_features, n_blocks):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, n_features, kernel_size=7, stride=1, padding=3),
nn.InstanceNorm2d(n_features),
nn.ReLU(inplace=True)
)
self.residual_blocks = nn.Sequential(*[
ResidualBlock(n_features) for _ in range(n_blocks)
])
self.decoder = nn.Sequential(
nn.ConvTranspose2d(n_features, n_features, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(n_features),
nn.ReLU(inplace=True),
nn.Conv2d(n_features, out_channels, kernel_size=7, stride=1, padding=3),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.residual_blocks(x)
x = self.decoder(x)
return x
class Discriminator(nn.Module):
def __init__(self, in_channels, n_features):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels, n_features, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
*[
nn.Conv2d(n_features, n_features * 2, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(n_features * 2),
nn.LeakyReLU(0.2, inplace=True)
] * 2,
nn.Conv2d(n_features * 4, 1, kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 2. 数据准备
def load_data(data_dir, image_size):
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = datasets.ImageFolder(data_dir, transform=transform)
dataloader = DataLoader(dataset, batch_size=1, shuffle=True, num_workers=4)
return dataloader
# 3. 训练循环
def train(dataloader_A, dataloader_B, G_AB, G_BA, D_A, D_B, optimizer_G, optimizer_D, device):
for i, (real_A, real_B) in enumerate(zip(dataloader_A, dataloader_B)):
real_A, real_B = real_A[0].to(device), real_B[0].to(device)
# 更新判别器
optimizer_D.zero_grad()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
loss_D_A = adversarial_loss(D_A(real_A), True) + adversarial_loss(D_A(fake_A.detach()), False)
loss_D_B = adversarial_loss(D_B(real_B), True) + adversarial_loss(D_B(fake_B.detach()), False)
loss_D = (loss_D_A + loss_D_B) / 2
loss_D.backward()
optimizer_D.step()
# 更新生成器
optimizer_G.zero_grad()
cycle_A = G_BA(fake_B)
cycle_B = G_AB(fake_A)
id_A = G_BA(real_A)
id_B = G_AB(real_B)
loss_G = adversarial_loss(D_A(fake_A), True) + adversarial_loss(D_B(fake_B), True)
loss_cycle = cycle_consistency_loss(cycle_A, real_A) + cycle_consistency_loss(cycle_B, real_B)
loss_identity = identity_loss(id_A, real_A) + identity_loss(id_B, real_B)
loss_G = loss_G + lambda_cycle * loss_cycle + lambda_identity * loss_identity
loss_G.backward()
optimizer_G.step()
if (i + 1) % 100 == 0:
print(f"Iteration [{i+1}/{len(dataloader_A)}], Loss_D: {loss_D.item()}, Loss_G: {loss_G.item()}")
# 4. 损失函数
adversarial_loss = nn.BCEWithLogitsLoss()
cycle_consistency_loss = nn.L1Loss()
identity_loss = nn.L1Loss()
lambda_cycle = 10.0
lambda_identity = 5.0
# 5. 初始化模型和优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
G_AB = Generator(3, 3, 64, 9).to(device)
G_BA = Generator(3, 3, 64, 9).to(device)
D_A = Discriminator(3, 64).to(device)
D_B = Discriminator(3, 64).to(device)
optimizer_G = optim.Adam(list(G_AB.parameters()) + list(G_BA.parameters()), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(list(D_A.parameters()) + list(D_B.parameters()), lr=0.0002, betas=(0.5, 0.999))
# 6. 加载数据
image_size = 256
data_loader_A = load_data('path/to/dataset_A', image_size)
data_loader_B = load_data('path/to/dataset_B', image_size)
# 7. 训练模型
train(data_loader_A, data_loader_B, G_AB, G_BA, D_A, D_B, optimizer_G, optimizer_D, device)
# 8. 保存/可视化生成结果
# 在训练过程中或结束后,可以保存和可视化生成器的输出,例如:
fake_A = G_BA(real_B)
save_image(fake_A, f'output/{epoch}_fake_A.png', normalize=True)代码讲解:
-
定义网络结构:定义了生成器(
Generator)和判别器(Discriminator)类。生成器通常采用编码器-解码器结构,并包含残差块(ResidualBlock,此处省略)以增加网络深度。判别器则采用卷积神经网络(CNN),逐步下采样输入直至输出一个二分类概率值。 -
数据准备:使用
torchvision库加载数据集,进行必要的预处理(如缩放、裁剪、归一化),并创建数据加载器以批处理方式提供数据。 -
训练循环:每次迭代中,先更新判别器(使其能正确区分真实图像和生成图像),再更新生成器(使其生成的图像既能骗过判别器,又能满足循环一致性损失和身份保持损失)。损失函数的计算与反向传播在此处完成。
-
损失函数:定义了对抗损失(
adversarial_loss)、循环一致性损失(cycle_consistency_loss)和身份保持损失(identity_loss),并设置了相应的损失权重(lambda_cycle和lambda_identity)。 -
初始化模型和优化器:创建生成器和判别器实例,将其移动到可用的计算设备(如GPU),并初始化Adam优化器。
-
加载数据:根据数据集路径和设定的图像大小加载数据,并返回数据加载器。
-
训练模型:调用
train函数进行实际训练过程。 -
保存/可视化生成结果:在训练过程中或结束后,可以保存和可视化生成器的输出,以便观察模型的训练进展和生成图像质量。
以上代码是一个简化的示例,实际应用中可能还需要添加更多细节,如模型保存与加载、学习率调整、早停条件等。此外,具体的网络架构、损失函数权重和训练超参数可能需要针对特定任务进行调整。
5.优缺点分析
优点:
- 无需配对数据:CycleGAN能够在没有源-目标图像配对的情况下进行跨域转换,极大地降低了数据收集和预处理的难度。
- 保持结构一致性:循环一致性损失确保了图像内容的结构在转换过程中得以保留,生成的图像具有较高的视觉真实性。
- 广泛应用:由于其对数据配对的低依赖性和良好的转换效果,CycleGAN广泛应用于艺术风格迁移、图像修复、季节转换、跨物种面部转换等多种场景。
缺点:
- 潜在模式遗忘:在某些复杂转换任务中,CycleGAN可能忽视源域的一些特定模式,导致转换后丢失部分细节。
- 训练稳定性:尽管比原始GAN有所改善,CycleGAN的训练过程仍可能出现震荡,需要适当调整超参数和训练策略。
- 计算资源需求:双生成器-判别器结构和循环一致性损失增加了模型复杂性和计算负担。
6.案例应用
CycleGAN在众多领域展现了强大的应用价值,以下列举几个典型示例:
-
艺术风格迁移:将普通照片转换为梵高、莫奈等著名画家的艺术风格,实现“普通人眼中的世界”与“艺术家眼中的世界”的融合。
-
季节转换:将夏季风景图转换为冬季景象,反之亦然,实现跨季节图像的自然过渡。
-
动物面部转换:如马脸转人脸、狗脸转猫脸等,揭示不同物种间面部特征的共性与差异,具有一定的科研价值和娱乐性。
-
图像修复与增强:对老旧照片、低分辨率图像进行修复与色彩增强,提升图像质量,应用于历史档案数字化等领域。
7.对比与其他算法
相较于其他无监督图像转换算法,CycleGAN具有以下特点:
-
与Pix2Pix相比:Pix2Pix基于有监督学习,需要配对的源-目标图像进行训练,虽然在给定配对数据时效果更佳,但应用场景受限。而CycleGAN无需配对数据,适用范围更广。
-
与UNIT、MUNIT等相比:这些模型同样无需配对数据,但通过共享潜在空间来实现转换,侧重于学习源域和目标域的共同表征。CycleGAN则通过循环一致性直接约束转换过程,对结构保留更为直接。
8.结论与展望
CycleGAN作为一种无监督图像到图像转换的强大工具,凭借其创新的循环一致性约束机制,在无需配对数据的情况下实现了高质量的跨域图像转换。尽管存在训练稳定性和模式遗忘等问题,但通过不断优化模型结构、损失函数设计及训练策略,CycleGAN及其衍生模型在艺术创作、视觉特效、图像修复等领域展现出广阔的应用前景。未来研究可进一步探索如何提高转换的精细化程度、减少计算成本,以及将CycleGAN应用于更多元化的视觉任务,如视频转换、三维物体建模等,持续推动无监督跨域图像生成技术的发展。

















 8397
8397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









