






探索Dagster:现代数据编排的利器
在如今数据驱动的世界,数据工程和数据处理的复杂度不断增加,不仅需要管理各种数据源和数据流,还需要确保数据处理管道的可靠性、可维护性和可扩展性。Dagster作为一个现代化的数据编排平台,旨在简化这些流程,帮助数据工程师管理和优化数据管道。本文将详细介绍Dagster的概念、核心功能及其在数据工程中的应用。
1. Dagster是什么?
Dagster是一个用于构建数据应用的跨行业框架,它帮助你以更优雅和高效的方式管理数据管道。与传统的调度和执行系统不同,Dagster不仅关注任务的调度和执行,还关注数据的流动和依赖关系,实现了数据和计算的深度集成。
网址:Dagster官网
2. Dagster的核心概念
在Dagster中,有几个核心概念需要了解:
-
Pipeline(管道):
Pipeline是Dagster中最基本的单元,它表示一组有序的任务(称为solid)的集合。这些任务之间通过数据依赖关系连接在一起,形成一个有向无环图(DAG)。 -
Solid(任务单元):
Solid是Pipeline中的一个步骤,进行实际的数据处理工作。每个Solid接受input并生成一个output。它可以是简单的操作(如数据转换),也可以是复杂的任务(如训练机器学习模型)。 -
Dagster Type(类型):
在Dagster中,每个Solid的输入和输出都有明确的类型定义。类型检查可以确保数据的准确性和一致性,减少错误发生。 -
Repository(仓库):
一个Repository是一个包含多个Pipeline和其他资源的集合,方便组织和管理大量的数据管道。 -
Pipeline Definition(管道定义):
Pipeline Definition定义了管道的结构,包括Solid及其相互之间的依赖关系。
3. 为什么选择Dagster?
选择Dagster可以带来一系列的优势:
-
数据处理的可观察性:
Dagster通过可视化工具和日志系统,提供了一流的数据处理可观察性,帮助你实时监控和诊断管道中的数据流和任务状态。 -
类型安全:
明确的数据类型定义和检查,保证了任务之间的数据传递的准确性。 -
灵活性和可扩展性:
Dagster支持分布式执行和并行处理,能够扩展以处理大规模数据管道。 -
上下文感知:
Dagster允许每个任务在执行时访问运行时上下文,从而可以根据运行时信息动态调整行为。
4. Dagster的使用示例
下面是一个简单的Dagster管道示例,演示了如何定义一个Pipeline及其任务(Solid),并执行相应的数据处理。
from dagster import execute_pipeline, pipeline, solid
@solid
def get_data(context):
data = [1, 2, 3, 4, 5]
return data
@solid
def process_data(context, data):
processed = [i * 2 for i in data]
return processed
@solid
def store_data(context, data):
context.log.info(f"Storing data: {data}")
@pipeline
def my_pipeline():
data = get_data()
processed_data = process_data(data)
store_data(processed_data)
if __name__ == '__main__':
result = execute_pipeline(my_pipeline)
for event in result.event_list:
if event.event_type_value == 'LOG_MESSAGE':
print(event.message)
在上述示例中:
get_data任务负责获取数据。process_data任务对数据进行处理。store_data任务将处理后的数据存储起来。my_pipeline通过依赖关系将这些任务串联成一个完整的管道。
5. 高级功能
除了基本的任务定义和执行,Dagster还提供了一系列高级功能:
-
Schedule(调度):
编写调度规则,定时自动运行Pipeline。 -
Partition(分区):
将数据按时间或其他维度分区,优化数据处理效率。 -
Sensor(传感器):
通过事件触发Pipeline执行,适应动态数据环境。 -
Backfill(补充填充):
针对历史数据重新运行Pipeline,确保历史数据的一致性。
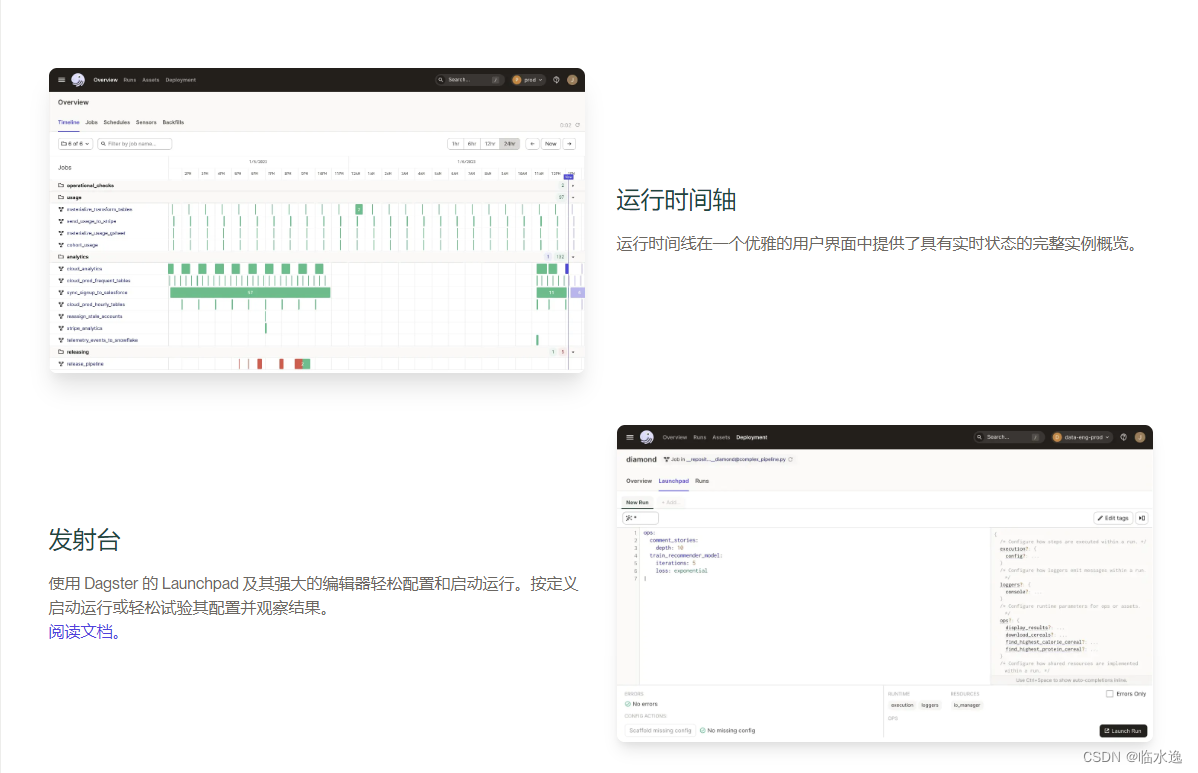
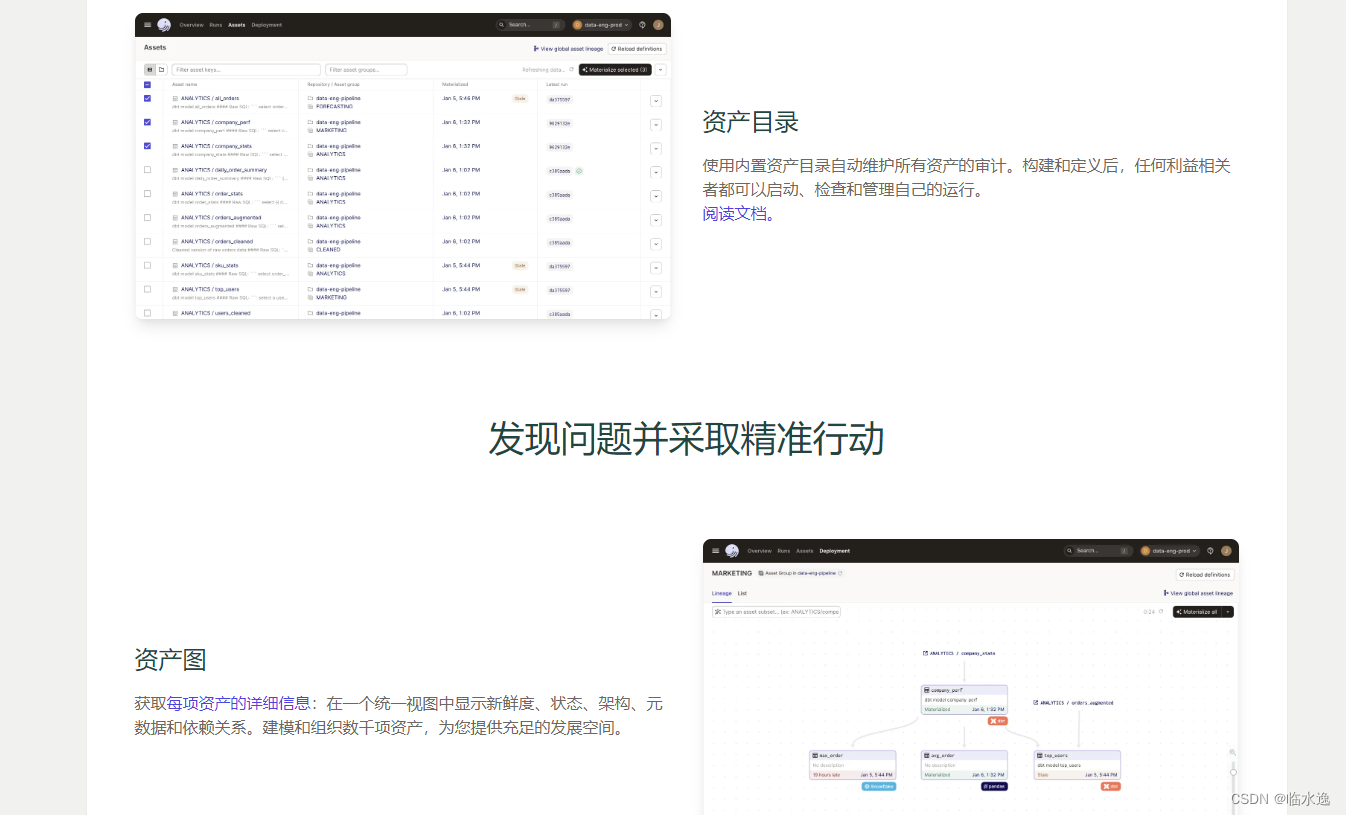
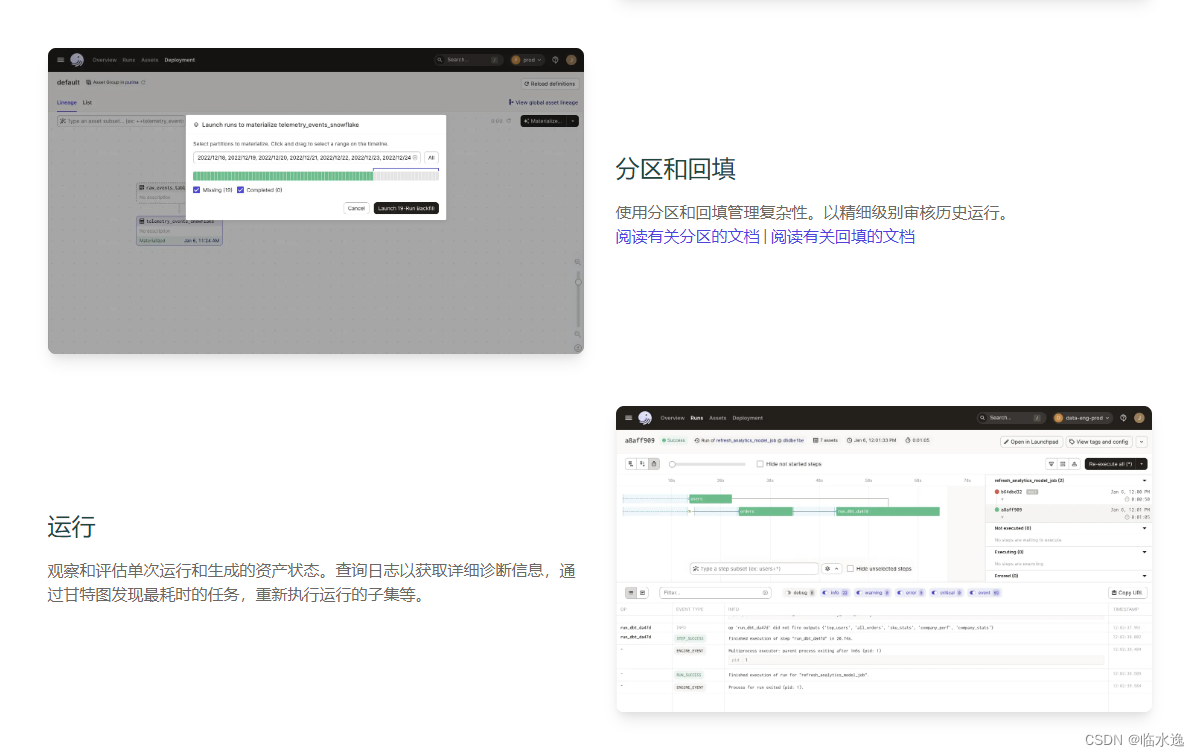
6. 结论
Dagster通过其强大的数据编排功能和灵活的设计理念,帮助数据工程师更高效地管理和优化数据管道。无论是小型项目还是大规模数据处理任务,Dagster都能够提供强大的支持,使数据处理更加透明、高效和可靠。
如果你正在寻找一种现代化的数据编排工具,Dagster将是一个值得尝试的选择。通过本文的介绍,希望你能对Dagster有一个基本的了解,并在实际项目中探索其更多的可能性。















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









