一、项目热身
(1)生成爬虫,并将 start_urls 改成正确的开始url
(2)配置 setting 文件内容
二、取图片URL的主要逻辑
- xpath定位li的位置 这里的 div 可以省略
- xpath定位到图片的 src 标签
- yield方法传递到 pipelines 中
三、在 pipelines 中下载URL并保存文件
直接下载
- 接收yield回来的图片url地址 # src
- 切割地址获取保存图片的文件名 # split
- 获取文件存储路径 # os.path.join os.path.dirname
- 下载图片 # request.urlretrieve(url, filename=None, ……)
使用内置的方法下载
- 获取url的逻辑代码中导入 from pic.items import PicItem
- 定义好一个Item,然后在这个item中定义两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的文件的url链接,需要给一个列表 scrapy.Field()
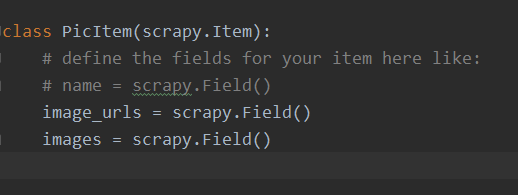
- 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中。如下载路径、下载的url和图片校验码等
- 在配置文件settings.py中配置IMAGES_STOR








 本文主要介绍如何使用Scrapy框架进行图片下载。首先,通过XPath定位获取图片URL,接着在pipelines中处理图片下载。文章讨论了两种下载方法:直接下载和使用Scrapy内置的ImagesPipeline。直接下载涉及接收图片URL、切割文件名和保存路径,而内置方法则利用PicItem定义image_urls和images属性,并配置IMAGES_STORE进行文件存储。
本文主要介绍如何使用Scrapy框架进行图片下载。首先,通过XPath定位获取图片URL,接着在pipelines中处理图片下载。文章讨论了两种下载方法:直接下载和使用Scrapy内置的ImagesPipeline。直接下载涉及接收图片URL、切割文件名和保存路径,而内置方法则利用PicItem定义image_urls和images属性,并配置IMAGES_STORE进行文件存储。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









