






前言:出于对瞄准类游戏的热爱,想做一个比较科技的辅助器,了解到关于python的yolo训练模型,花了两天时间参考无数网页,跌跌撞撞完成了yolo程序的搭建,记录一下过程,以后方便搭建
目录
2.在pycharm配置环境,Setting->Project Interpreter->Add Python Interpreter
准备工具:
1.安装python开发工具,Pycharm,我用的是试用版,官网下载。
2.安装python版本管理工具,用于切换python版本。Anaconda开源的,安装方法在下面的1.1网址内
1. 开始工作:
1.PyTorch环境配置及安装
PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习
安装重点:
python用3.7版本
Pytorch选择上,如果你的电脑有2080ti或以上显卡的选择用CUDA,没有的话像笔者一样用CPU
为Anaconda添加国内镜像源,速度嘎嘎的快
参考这个文章:PyTorch环境配置及安装_pytorch配置_饰一的博客-CSDN博客
2.在pycharm配置环境,Setting->Project Interpreter->Add Python Interpreter
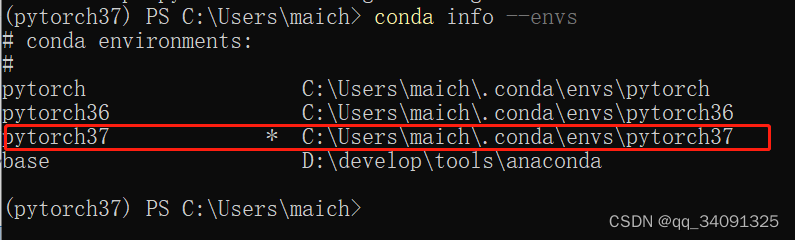
Interpreter选择当前环境的python.py,输入>conda info --envs 带*号的文件夹里面找到python.py
3.下载yolov5项目
登录GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
并下载到本地,
4.项目结构
使用pycharm打开该项目,我们先了解下项目结构,以便于我们修改配置文件
/yolov5
/data 训练数据集文件夹
/hyps 超参配置文件,用于数据增强
/images yolo开发员用于测试数据,用于参考
coco.yaml yolo开发员自己写的训练集配置文件,用于参考
/models 模型文件夹,存放权重文件
yolo~.yaml 权重文件,权重越高,采样概率越大
/utils 工具包
train.py 用于训练数据
detect.py 训练完后,用来测试数据
5.启动detect文件
因为下载的yolo项目,开发员已经训练好的,不需要再次训练,直接detect即可
期间有很多module缺失报错,使用下面的命令安装包
pip install 【包名】 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果包冲突,可以使用pip uninstall 【包名】,pip install --upgrade 【包名】
至此yolov5运行完毕。接下来说说怎么训练自己的训练样本。
2.训练自己的样本
1.收集训练图片样本
以笔者为例,打算测试百里的自瞄,在游戏里把一段百里对线鲁班视频截屏下来,大概20秒,
使用Convert To JPG转成一帧帧的图片,放在该目录下D:\yolo_v5\datasets\images\train
2.收集训练标签样本
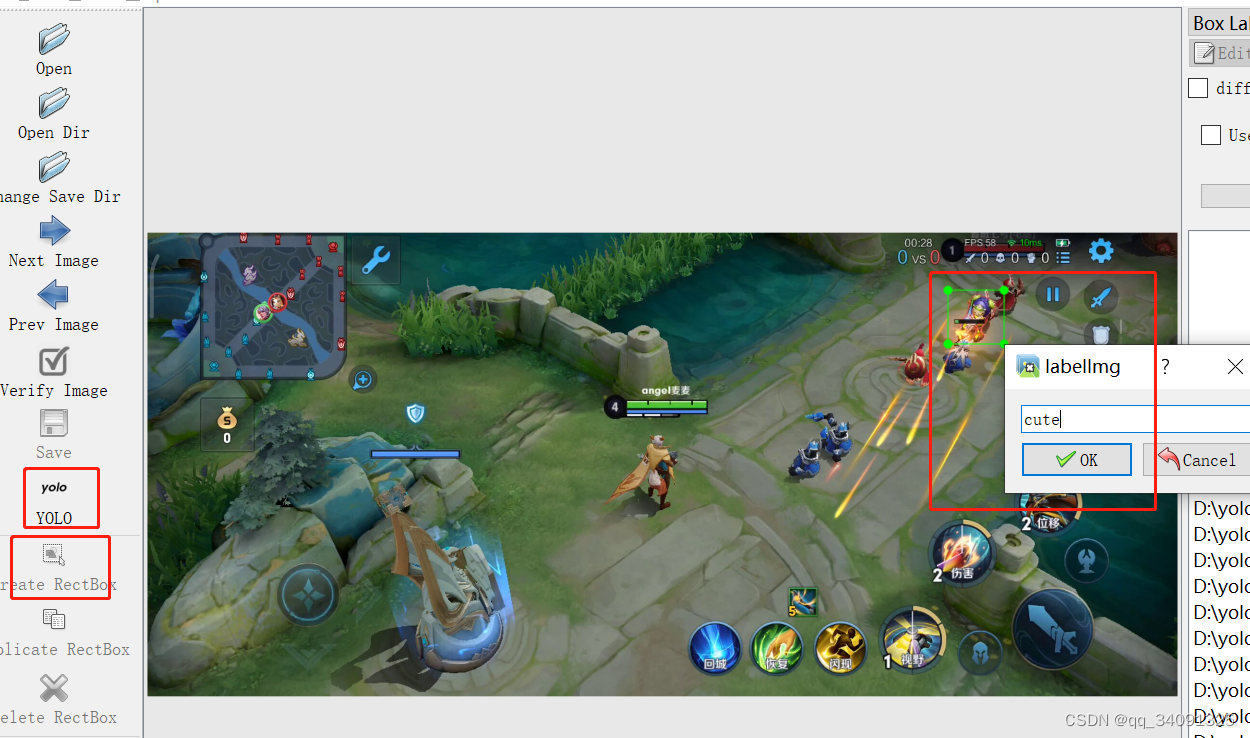
python下载图片提取标签的工具>pip install labelimg,运行>labelim
百度一下,打上标签【cute】,按顺序取120张图片转为标签文件存放在D:\yolo_v5\datasets\labels\train
3.修改训练集配置文件
由于改了训练样本的位置,也需要改一下配置,复制coco.yaml,自定义文件名
内容改为这样:
train: D:\yolo_v5\datasets\images\train # train images (relative to 'path') 128 images
val: D:\yolo_v5\datasets\images\train # val images (relative to 'path') 128 images
nc: 1 # 多少个类数目,我这里只有一个类名
names: ['cute'] # 类名
4.修改train.py训练脚本
parser.add_argument('--data', type=str, default=ROOT / 'data/自定义文件.yaml', help='dataset.yaml path')#配置新的训练集配置文件
parser.add_argument('--epochs', type=int, default=50)#电脑运行太慢了,我只设置了50,也就是重复跑50次训练样本
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')#电脑运行太慢了,设置为一次性随机训练8张图片
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size h,w')#电脑运行太慢了,将图像缩小成 640×640 大小进行训练,可以设置格式例[720,540]
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')#默认是cuda,没有显卡,所以设置为cpu
5.运行train.py
训练时间取决于电脑配置,还有训练次数epoch和batch数量

训练完成后在/runs文件夹下生成/exp【周期】文件夹,并在该文件夹下生成results.csv文件
打开该文件,可以看到训练结果
-
GIoU:推测为GIoU损失函数均值,越小方框越准;
-
Objectness:推测为目标检测loss均值,越小目标检测越准;
-
Classification:推测为分类loss均值,越小分类越准;
-
Precision:精度(找对的正类/所有找到的正类)
6.修改detect.py检测脚本
parser.add_argument('--source', type=str, default='D:/yolo_v5/datasets/cute.mp4', help='file/dir/URL/glob, 0 for webcam')#用于测试的视频路径
parser.add_argument('--data', type=str, default=ROOT / 'data/cute.yaml', help='(optional) dataset.yaml path')#训练集位置
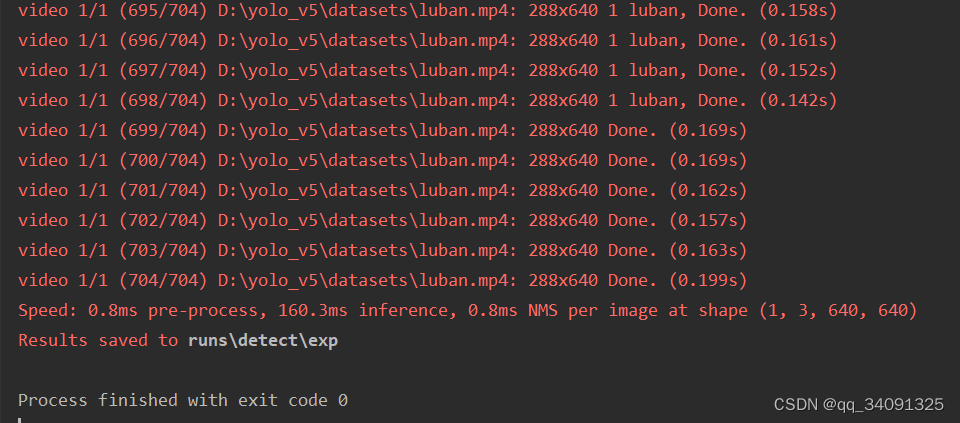
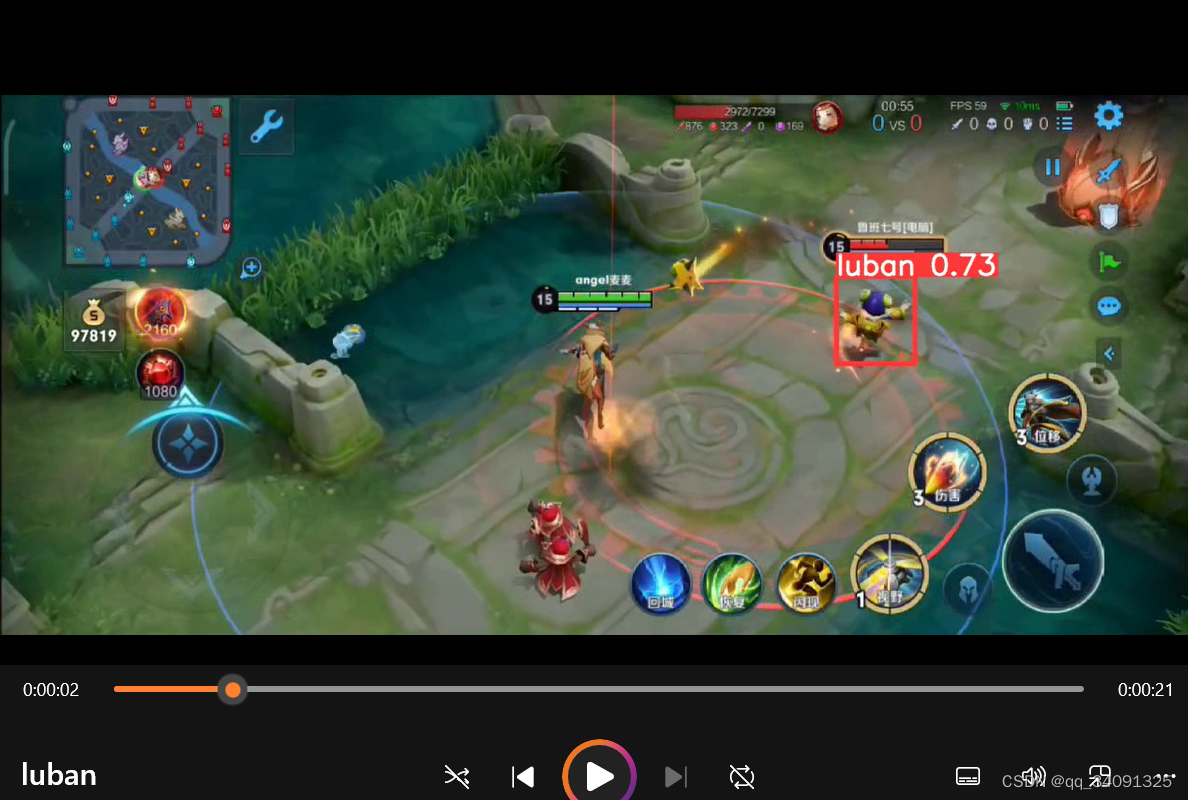
8.运行detect.py
6.关键代码
上面的只是视频识别,接下来要实机展示
先上业务逻辑型代码。
还没做到这一步















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









