







一、概述
参考资料:https://tianchi.aliyun.com/notebook/170913
逻辑回归(Logistic regression,简称LR)是一个分类模型。
其主要优点为:
- 实现简单,计算速度快,存储资源低
- 可解释性强
主要缺点为:
- 容易欠拟合
- 分类精度不高
二、核心代码流程
(一)库文件导入与数据获取
## 基础函数库
import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
## 构造一个简单数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])
(二)模型训练
调用 LogisticRegression() 获取模型对象,即lr_clf。
让 lr_clf 调用 fit() 方法去拟合输入输出(模型训练)。
## 获取“逻辑回归模型对象”
lr_clf = LogisticRegression()
## 用“逻辑回归模型对象”去拟合构造的数据集
lr_clf = lr_clf.fit(x_fearures, y_label)
#其拟合方程为 y=w0+w1*x1+w2*x2
(三)模型预测
重新模拟两个输入数据 x_fearures_new1 和 x_fearures_new2,调用训练好的模型对其进行分类判别:
x_fearures_new1 = np.array([[0, -1]])
x_fearures_new2 = np.array([[1, 2]])
## 在训练集和测试集上分别利用训练好的模型进行预测
y_label_new1_predict = lr_clf.predict(x_fearures_new1)
y_label_new2_predict = lr_clf.predict(x_fearures_new2)
print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)
## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所以我们可以利用 predict_proba 函数预测其概率
y_label_new1_predict_proba = lr_clf.predict_proba(x_fearures_new1)
y_label_new2_predict_proba = lr_clf.predict_proba(x_fearures_new2)
print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba)
print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba)
"""
输出结果如下:
The New point 1 predict class:
[0]
The New point 2 predict class:
[1]
The New point 1 predict Probability of each class:
[[0.69567724 0.30432276]]
The New point 2 predict Probability of each class:
[[0.11983936 0.88016064]]
"""
三、辅助代码流程
(一)数据模型可视化(方案一)
在完成模型训练之后,可以使用一些绘图API完成数据模型可视化。
例如一段使用 matplotlib 的代码如下:
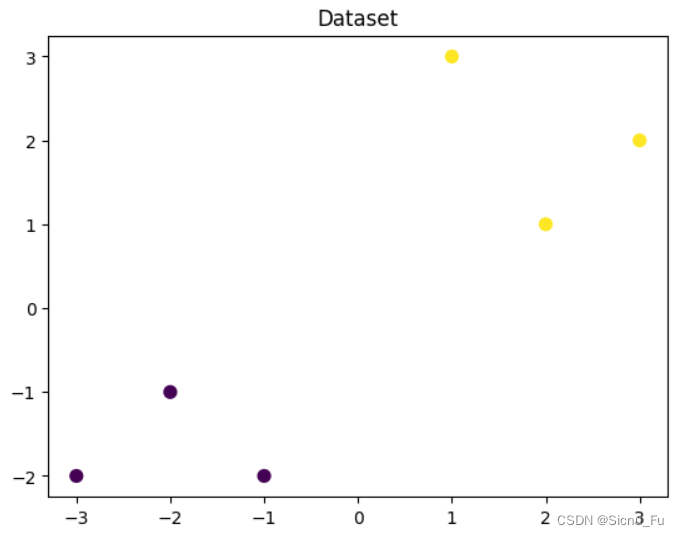
## 可视化构造的数据样本点
plt.figure()
## 在图中横坐标和纵坐标的数值,分别作为输入数据的两个特征。
## 而图中节点的颜色,则代表输入数据的分类。
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
plt.show()
该代码运行结果可以很好进行数据模型的可视化展示:
(二)数据模型可视化(方案二)
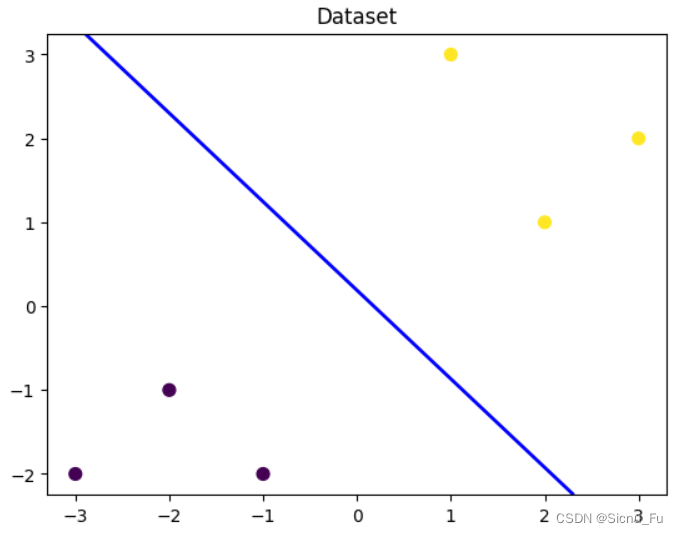
如果想要可视化更精细,还可以画出分割线,其代码如下所示:
# 可视化决策边界
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
nx, ny = 200, 100
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
z_proba = z_proba[:, 1].reshape(x_grid.shape)
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()
代码的运行结果如下:
四、总结
总的来说,逻辑回归不仅数学原理比较简单,其代码实现也比较简单,一共分为三步:
- 调用
lr_clf = LogisticRegression()获取模型对象。 - 调用
lr_clf = lr_clf.fit(x_fearures, y_label)完成拟合 - 调用
y_label_new2_predict = lr_clf.predict(x_fearures_new2)完成分类预测。predict()也可被替换为predict_proba(),得到相关类别的预测概率。
在学习目标上,除了掌握模型本身训练和使用的方式,还需要掌握常见的数据可视化的分析方法,即 matplotlib 的相关使用。















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









