







- 文章转自微信公众号:机器学习炼丹术
- 论文名称:Give Me Your Trained Model: Domain Adaptive Semantic Segmentation without Source Data
- 作者:炼丹兄(欢迎交流共同进步)
- 联系方式:微信cyx645016617
0 什么是source-free问题
训练得益于大量的数据,A数据集有标注,B数据集无标注。如何利用A数据集在B数据集上取得效果,这是经典的Domain adaptation问题。
然而最近隐私越来越关注,在真实场景中访问源数据可能会也可能侵犯知识产权。所以这里提出了一个更有意思的任务,仅仅获取A数据集的模型,然后根据算法来利用B数据集进行self-training的无监督训练。这种问题叫做:Domain Adaptive Semantic Segmentation without Source data (DAS3 for short)。
1 相关工作
1.1 域迁移语义分割任务
目前存在的域迁移方法可以划分成两组:
- adversarial learning-based:基于对抗学习;
- self-supervised learning based:基于自监督训练的方法。
对于对抗学习,大量的工作针对减少图像级别的分布失调、还有特征级别和输出预测级别的。【利用对抗生成网络,来判断图片是源域还是目标域、图片提取的特征是源域还是目标域、图片的分割mask是源域还是目标域】
对于自监督学习,关键的问题是生成可以信赖的pesudo labels伪标签。经典的方法包含两个步骤:
- 基于source model或者是domain-invariant model生成pesudo label。
- 通过生成的pesudo label来有监督的调整target model。
【这里的domain-invariant model是指,根据对抗学习训练的分割模型,所以两个方法是可以结合的】
1.2 源域缺失的域迁移任务
对于source-free的任务,目前有解决source-free 分类任务的研究。其中一个研究,提出了universal source data-free domain adaptation的方法,当target domain的标签是不可用的情况下。
对于分割任务,模型的自适应是解决源域数据缺失的可行方案之一。其中这个研究“Source-free domain adaptation for semantic segmentation”利用生成模型来人工生成虚假的样本来作为源于数据的估计。然后通过model adaptation来实现知识的迁移。
1.3 半监督学习
半监督学习的关键是学习标注样本和未标注样本之间的特征表达的一致性。为了实现这个目标,consistency regularization的方法近些年有了大量的研究。
2 Method
We aim to address source-data absent domain adaptive semantic segmentation problem with only a pre-trained source model in this paper.
数学符号定义:

这里说了,source model是由最小化crossentropy的损失来得到的一个平平无奇的分割模型 M s M_s Ms。并且这个分割模型包含:
- feature extractor f s f_s fs
- classifier g s g_s gs
为了将 M s M_s Ms迁移到target domain,这篇文章提出的 D A S 3 DAS^3 DAS3的方法包含三个阶段:
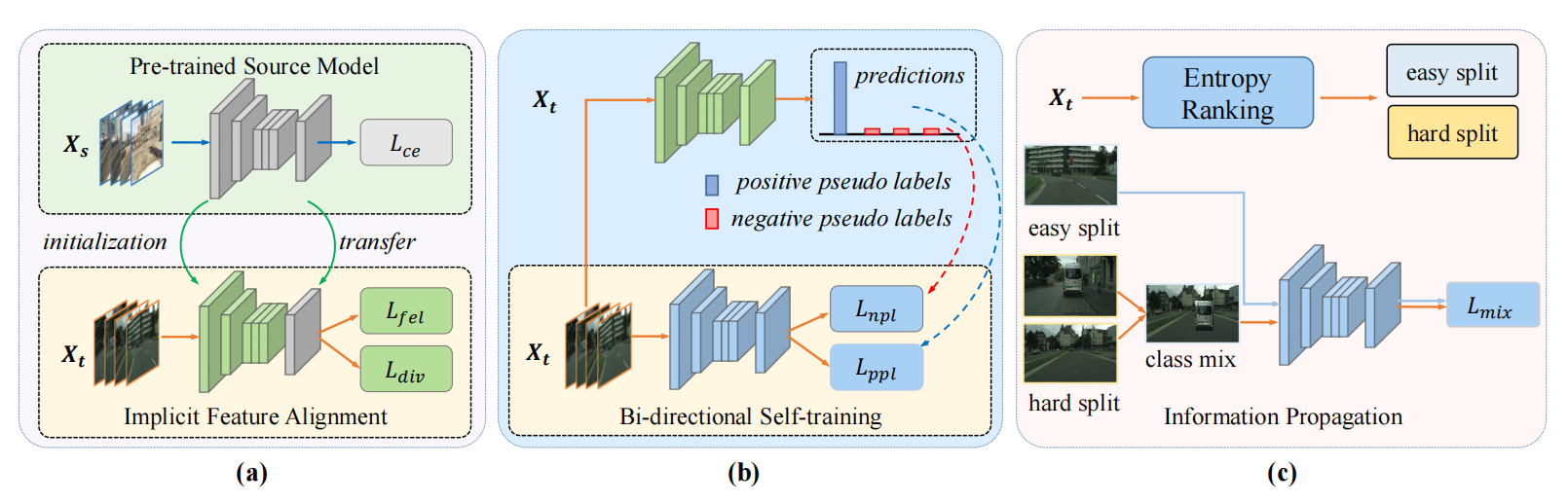
-
第一个阶段:implicit feature alignment隐含特征对齐,目的是:间接的要target features来适应source model。方式是:通过提出的focal entropic loss 和 weighted diversity loss。在这个阶段,模型的参数被初始化位 M s M_s Ms,然后classifier被冻结参数
-
第二阶段是self-training阶段。目的是:增强目标特征的表达。方式是:通过提出的Bi-directional self-training technique。
-
第三阶段是:用半监督的方式来实现信息的迁移,降低intra-domain discrepancy域内差异。
2.1 Implicit Feature Alignment
我们结合最小交叉熵策略来降低分布差异。
比方说:高置信度的预测结果应该比低置信度的预测结果具有更好的转移性(transferability)。这里提出的focal entropic loss是为了降低不确定预测的权重,然后让模型针对确定的预测结果。

- α \alpha α是平衡certain/uncertainty的权重的;
- γ \gamma γ是控制:让确定的样本有着更小的交叉熵损失。
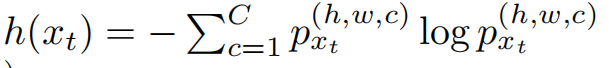
此外为了保证target output的全局多样性,采用了diversity-promoting loss。这个损失可以避免将容易混淆的类预测为相对容易学习的类的问题。
2.2 Bi-direction Self-training
以前的子标签的方法目的是加强标签的可信度,通过开发各种去噪策略。但是他们忽略了置信度较低的大多数像素。这种情况下,模型会优先学习容易学习的、置信度较高的样本,从而忽略置信度低、难度大的样本。我们则是关注后者,我们称其为:negative pesudo labels。虽然置信度低的标签不能作为正确的标签使用,但是他们可以暗示一些特定的类。
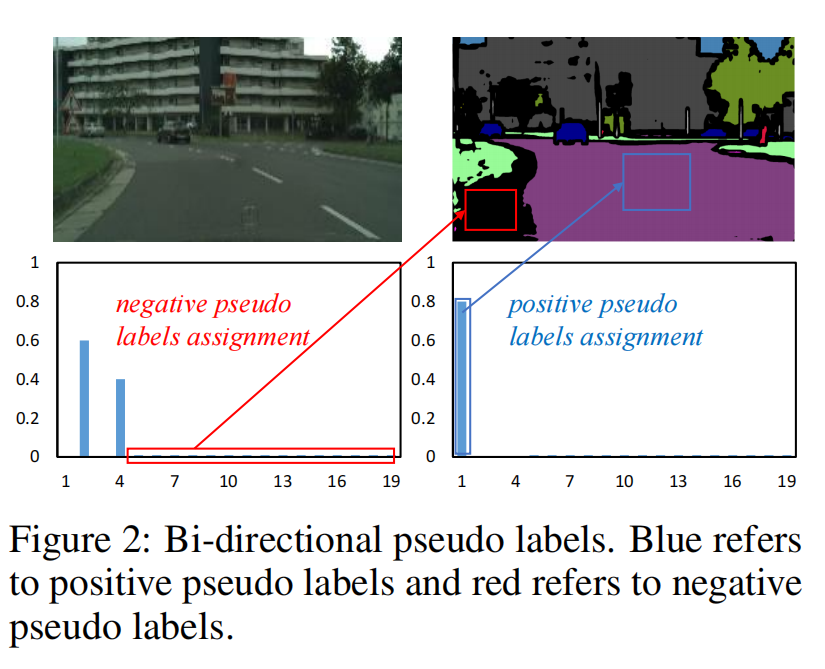
图中黑色区域,我们很难判断他是哪一个类别,但是可以简单的判断出它一定不是哪一个类别。基于这样的思想,我们提出了:bi-directional self-training method。包含两个部分:
- positive pesudo labels
- negative pesudo labels
2.2.1 Positive pesudo label
目的是选择高置信度的标签用来训练。如果使用一个hard-thres,那么对于hard-to-transfer的特征(路灯,信号灯,火车,自行车等)的表现会很差。所以我们设计了pseudo-label,基于guidance of category-level threshold。
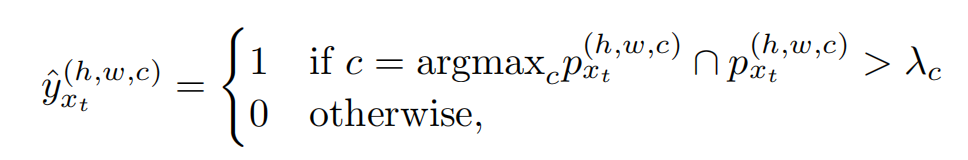
相当于给每一个类别设置一个 λ \lambda λ阈值,阈值的选择是:一个图片的每一个类的Top K预测值。
之后我们用确定的positive pesudo label来有监督的训练target model(交叉熵损失):
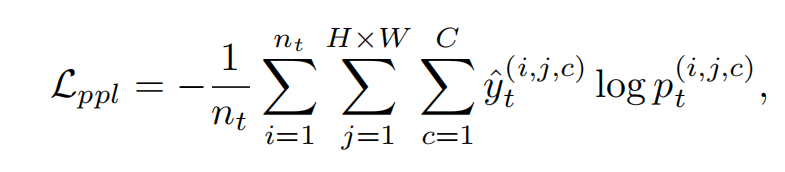
2.2.2 Negative pesudo label
如何利用不确定的标签。举一个例子:
[0.48, 0.47, 0.02,0.03],我们无法确定这个类被是第0类还是第1类,但是我们可以确定这个一定不属于第2类和第3类。
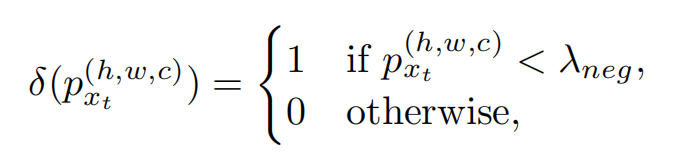
将置信度小于0.05(论文中设置的参数)的类别置1,然后其他的置0;
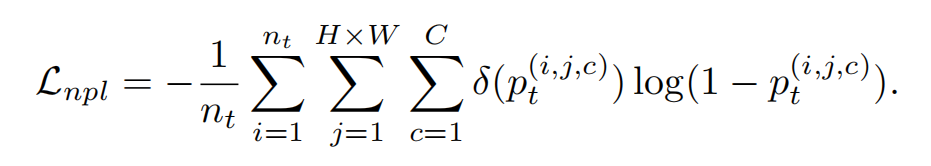
也是最小化交叉熵的方法来计算loss,类似于multi-label的计算。
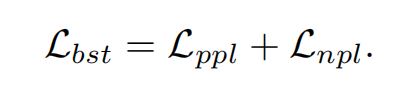
最后二阶段的所有loss函数包含Positive和negative两部分。
2.3 Information Propagation
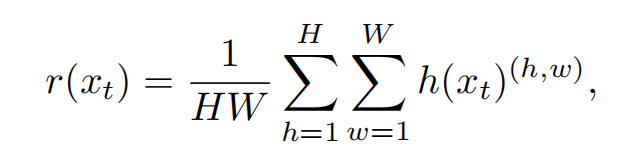
通过计算每一个样本的熵,来进行排序。熵最小的判断为容易样本,熵越大表示样本越难。作者使用的0.3来作为容易样本的比例。现在我们由70%的hard样本和30%的容易样本。
采用这个损失函数来进行三阶段的训练:
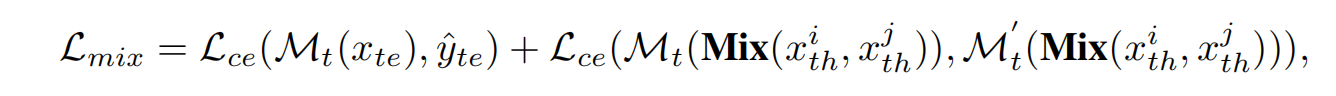
- 其中我们会把第二阶段训练好的模型复制一遍;
- 第一项是用复制的模型的output和第二阶段的模型的output做crossentropy,把第二阶段的模型的输出看作label;
- 第二项则是训练难样本的过程。其中关键是Mix方法的意义。

Mix就是融合两个随机难样本的方法,我们得到了两个随机难样本,然后我们随机的选择一个类别mask。我们抠下第一个难样本的这个mask的区域,然后拼接上第二个难样本的其他区域。这样就缝缝补补的形成了一张新的图片。
3 实验细节
数据集采用的是GTA5和cityscape,SYN这些全景分割数据集。

分割模型使用的是Deeplabv2-resnet101.实验结果也是SOTA:

















 8475
8475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









