







站主近期建立了一个自己的网站来发博文,文章已经搬运到了下面的地址:
1 定义
百度百科的定义:
它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平方减去某一类中地表真实像元总数与该类中被误分成该类像元总数之积对所有类别求和的结果所得到的。
这对于新手而言可能比较难理解。什么混淆矩阵?什么像元总数?
我们直接从算式入手:
k
=
p
0
−
p
e
1
−
p
e
k = \frac{p_0-p_e}{1-p_e}
k=1−pep0−pe
p
0
p_0
p0是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度
假设每一类的真实样本个数分别为
a
1
,
a
2
,
.
.
.
,
a
c
a_1,a_2,...,a_c
a1,a2,...,ac
而预测出来的每一类的样本个数分别为
b
1
,
b
2
,
.
.
.
,
b
c
b_1,b_2,...,b_c
b1,b2,...,bc
总样本个数为n
则有:
p
e
=
a
1
×
b
1
+
a
2
×
b
2
+
.
.
.
+
a
c
×
b
c
/
n
×
n
p_e=a_1×b_1+a_2×b_2+...+a_c×b_c / n×n
pe=a1×b1+a2×b2+...+ac×bc/n×n
1.1 简单例子
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
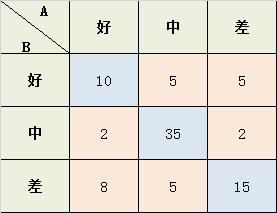
从上面的公式中,可以知道我们其实只需要计算
p
0
,
p
e
p_0 ,p_e
p0,pe即可:
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1b1 + a2b2 + a3b3) / (8787) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
例子引用来自博客,可以说提到kappa网上到处都是两个老师的例子,哈哈
2 指标解释
kappa计算结果为[-1,1],但通常kappa是落在 [0,1] 间
第一种分析准则–可分为五组来表示不同级别的一致性:
0.0~0.20极低的一致性(slight)
0.21~0.40一般的一致性(fair)
0.41~0.60 中等的一致性(moderate)
0.61~0.80 高度的一致性(substantial)
0.81~1几乎完全一致(almost perfect)
3 python实现(可直接用于深度网络中)
def eval_qwk_lgb_regr(y_true, y_pred):
# Fast cappa eval function for lgb.
dist = Counter(reduce_train['accuracy_group'])
for k in dist:
dist[k] /= len(reduce_train)
reduce_train['accuracy_group'].hist()
# reduce_train['accuracy_group']将会分成四组
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return 'cappa', cohen_kappa_score(y_true, y_pred, weights='quadratic'), True
以上代码是本人在kaggle比赛中使用的,因为kappa系数的算法非常好写,但是又要根据实际问题进行微小的调整,所以就不修改了。如果能提供帮助自然好,如果没有头绪的话,就去第一二章节好好看看,理解一下kappa系数的算法。
4 总结
其实kappa系数就是一种检验一致性的方法,可以用在深度网络中的metric函数中,也可以用在统计学上的一致性检验上。

















 6809
6809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









