






使用diffusers与sd-scripts训练LoRA的区别
背景
diffusers和sd-scripts是两个常用的文生图模型工具库,分别使用两个库训练LoRA,对齐数据与LoRA参数(rank, alpha),推理时发现训练出来存在比较大的效果差异。
两个库的差异
- diffusers:更原子化,方便复现aigc各种算法
- sd-scripts:依赖于diffusers的早期版本,针对模型微调做了深度定制,实现了大量实用的工具,例如对caption的处理,训练中对vae或者text encoder输出进行缓存等等。
选择哪一个
对于只需要微调的需求,用sd-scripts会省事不少,按照官方脚本,调整开放出来的参数就够用了。
在我的工作流中微调只占一小部分,集成sd-scripts会引入许多没有使用到的工具,同时我需要对模型、数据等做拆解实验,此时直接从diffusers入手是更合适的选择。
两者训练的核心差异
两者的核心差异在于alpha值的处理,与默认LoRA配置的层数。

1. alpha值的处理
rank和alpha是lora训练中重要的两个参数,其中rank决定了表达能力的上限,而alpha是起到控制学习速率的作用,受此影响,我一直以为alpha只在训练中起作用。
对比两个库训练后保存下来的权重文件,我发现sd-scripts训练后存下来的权重中,除了有每层LoRA的两个低秩矩阵以外,还保存了每层的alpha值,而diffusers保存下来的文件是没有alpha值的。
训练后使用diffusers推理时,通常会使用pipeline.load_lora_weights将LoRA权重加载到基模,再用pipeline.set_adapters(name, weight)指定该LoRA生效的尺度系数。
从load_lora_weights的代码中可以看到加载的过程中除了LoRA的两个参数矩阵以外,Alpha值也会被读取。
另外从set_adapters层层深入,最后看到调用了PEFT库里的函数,而从这个函数可以发现,跟训练过程一样,alpha / rank 会作为一项系数,并且再乘以推理过程中指定的LoRA scale作为最终的LoRA系数。
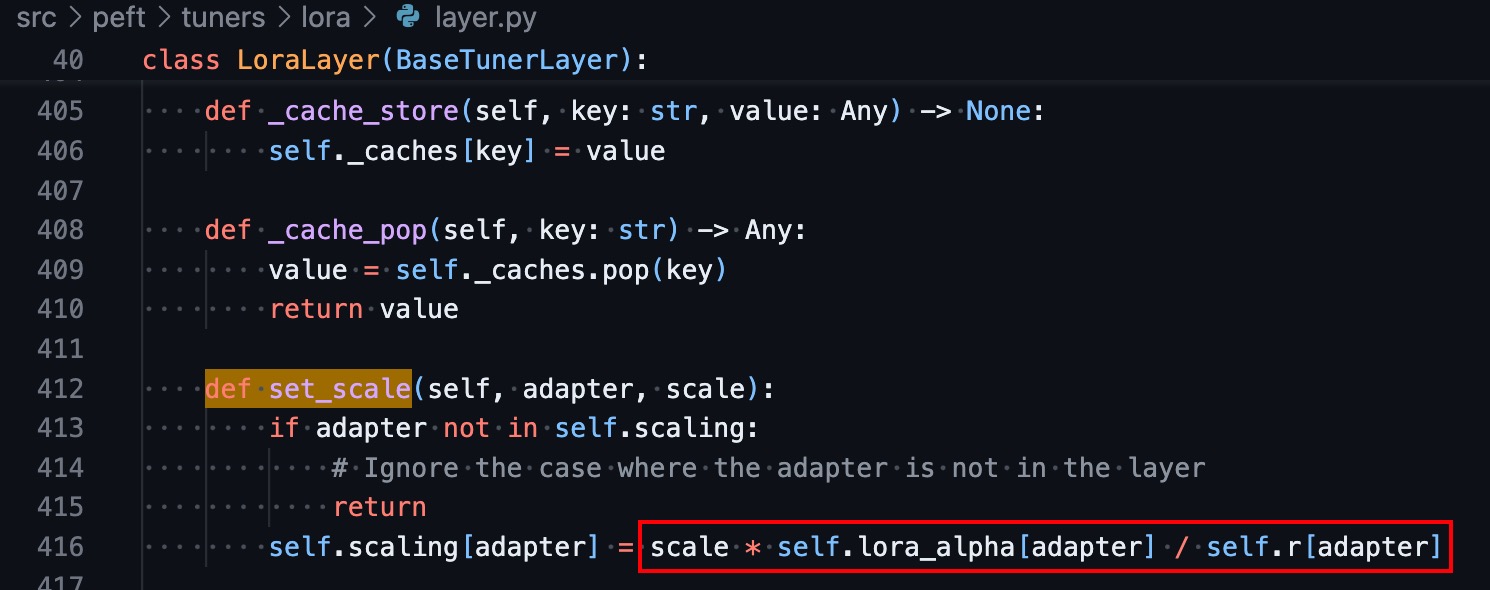
因此,真相便是,sd-scripts训练后的权重文件中保存了alpha值,并且在推理过程中被读取并作用于LoRA缩放,而diffusers训练后的权重文件丢失了alpha值(此时使用默认的alpha值,等于rank),导致二者推理时缩放的系数不一致。
2. LoRA的层数不一致
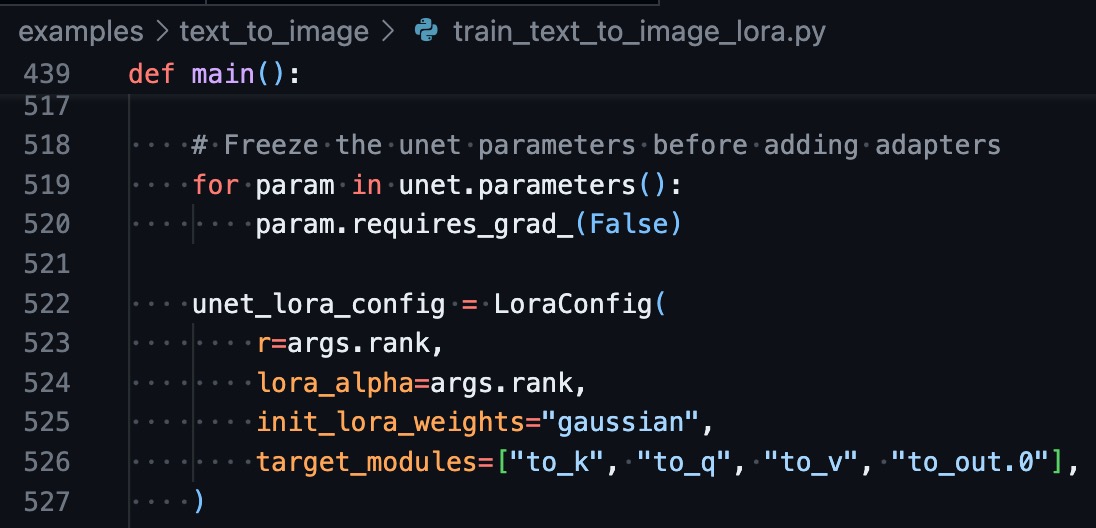
在diffusers官方的LoRA脚本下,只会对q,k,v,o层创建lora:
sd-scripts则默认会针对所有Linear层创建lora权重,当指定Conv层的rank时则Conv层也会创建:
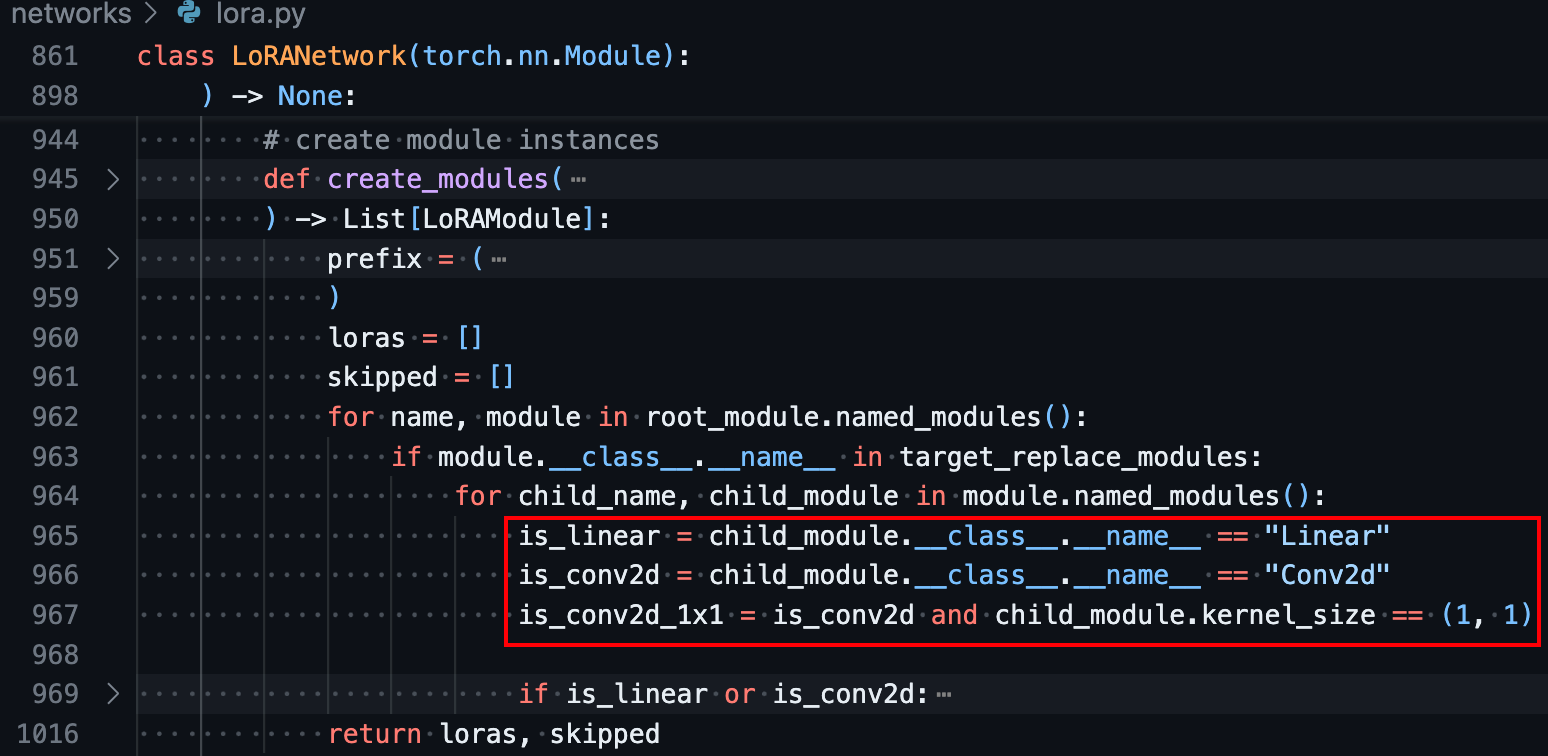
不要小看只是几层的差异,两者的参数量相差不小,训练的效果自然也会有差异。
总结
使用diffusers微调LoRA模型时要注意alpha值以及设置LoRA的模块这两点细节。

















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









