







题目:基于FMRI脑信号的面部表情解码的研究
摘要:
研究定位:
将图像识别技术与机器学习算法相结合运用到医疗图像的处理中,使用人工智能的方法解析复杂的医学图像,从而找出医学图像中隐藏的奥秘。
技术描述:
- 使用核磁共振仪获取被刺激后的被试者的脑部图像,
- 通过 时间序列 找到所对应的面部表情,
- 对获得的脑部图像进行预处理以及SPM解析,
- 之后获取特征向量 使用降维技术主成分分析 PCA 对特征向量进行降维操作
- 将所获得的特征向量与标签输入分类器极限学习机,使用交叉验证方法来统计所解析的表情的准确率
- 分别将支持向量机、极限学习机两种算法作用于同一数据集上比较分类器的性能
结果:
fMRI不仅能够解读出简单的运动指令,同时也能解读出复杂的高级思维活动,这些认知过程和大脑的某些区域有关。因此fMRI技术更适合来做人类面部表情的解码工作。
知识点:
1.fMRI( functional magnetic resonance imaging 功能性磁共振成像)
通过核磁共振仪对人的大脑进行扫描,fMRI的成像原理是通过机器内部的磁场对人体的神经元的活动造成影响,神经元的活动从而使得血流与血氧也随之改变,fMRI通过测量它的改变所成像的。
fMRI具有非侵入性以及可重复性
广泛应用在定位大脑分区
研究现状:
应用领域:认知科学、神经科学、fMRI数据分析与处理、正常脑功能的fMRI研究和神经系统疾病的fMRI研究。
国内目前多使用1.5T的核磁共振仪进行fMRI成像,fMRI的后处理软件常用的是SPM。
问题:fMRI图像会包含有大量的噪音
目前主要是在人脑分区上。今后研究重点方向:认知的交叉文化的研究、非语言推理的速度和皮层活动的定位及区域大小的关系、利用fMRI技术与其他在脑研究方面的技术相结合。
2.机器学习

3.脑信息解码
脑信息解码技术是使用fMRI和机器学习算法根据所获得的大脑信号 来估计此时被试者在表情图像的刺激下所呈现的面部表情,感知、认知以及心脏内部的状态。
步骤:
为测量的大脑活动数据分配标签,并将感知内容与标签相关联
将机器学习算法应用于脑活动数据,构造解码器
评估解码器是否准确预测了新的脑活动数据
4.交叉验证法
5.支持向量机
6.极限学习机(Extreme Learning Machine)
由输入层、单层的隐含层及输出层三层结构构成,可以随机初始化权值,训练过程中无需调节参数,具有单个隐藏层的神经网络。
基于ELM的各类分类器:极限学习机、在线极限学习机、正则化极限学习机



7.极限学习机的学习算法
- 需要知道隐藏层隐含节点的个数,然后随机产生各个输入节点与隐藏节点的链接权值w和隐藏节点的偏置值b;
- 为隐藏层的隐藏节点找到一个激活函数,该函数无线可微分,由此得出隐藏层的输出矩阵H;
- 根据所得到的隐藏层的输出矩阵H于网络的输出T计算输出层权值B,B=HT。
在极限学习机中的激活函数:非线性的函数(sigmoid函数)、许多不可微的函数、有些不连续的函数。
适合用于:回归、拟合、分类、模式识别等问题,一脸诊断、图像识别等领域。
极限学习机:核极限学习机、正则化极限学习机、在线序列…、误差最小化…、增强…。
8.主成分分析(Principal Component Analysis,PCA)
主成分分析是一种将问题由高维度降到低维度,同时又不影响问题原本含义的一种降维方法。
PCA优化的目的是:在高维的数据中找到一个超平面使正交距离(图中的虚线)之和最小。

-
PCA主成分分析原理
-
k值选取

t值的大小代表着希望保留的将为信息的多少,t越小=>保留的越多。t=0.02,那么保留降维前98%的信息。
9.协方差原理
协方差代表两个样本参数的相关性,Cov(x,y)>0,则表示两者正相关,<0两者为负相关,=0为相互独立。
对于一个多维的向量,向量中各个参数的协方差组成的矩阵被称为协方差矩阵,它是一个对称矩阵,矩阵的边的长度为n(n-1)/2,3维(x,y,z)的协方差矩阵表示:
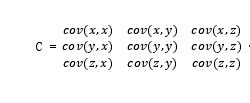
10.SVD分解原理
对一个矩阵A进行SVD奇异值分解,得到矩阵A的特征值与特征向量。
前提条件:A为方阵且可逆。
若 AX=入X,则入为矩阵A的特征值,X为该特征值对应的特征向量。可逆的方阵A与P-1AP相似,因此他们的特征值相同,而矩阵P的每个列向量就是矩阵A的每个特征值所对应的特征向量。
-
PCA算法实现的大致步骤:
输入数据集x={x1,x2,x3…}以及需要降到的低维纬度K维
将所有的数据范本实施均值归一化处理
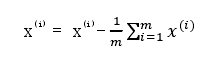
计算协方差矩阵
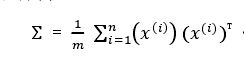
将上一步中得出的协方差矩阵进行SVD分解
将特征值进行从大到小的排序,然后提取出前K个特征向量u1,u2,u3,…,uk
输出降维后的投影特征矩阵Ureduce={u1,u2,…,uk}
输出降维后的数据集
11.线性模型
- 线性模型:自变量为连续的数值,且自由变量的期望值与因变量之间的关系为线性相关。
广义线性模型(generalized linear model,GLM)自变量:连续的数值数据或离散的正整数
脑的结构和功能

Bromann分区系统,按照某种规律将人的大脑部分割成了多个小区域,而人为地对各个区域编号。每半个大脑分为52各区域,左半脑与右半脑相对应,不同的号码在不同物种之间表示不尽相同的分区。

功能性磁共振成像原理(fMRI)
概念总结过
- fMRI物理基础
- fMRI图像的建立
- SPM数据处理
SPM数据处理分析过程:数据预处理过程、统计分析过程。
-
数据预处理过程
Slice Timing(时间层矫正)
Realignment(头动校正)
Normalize(标准化)
Smooth(平滑)时间层矫正是用来校正大脑图像中切片与切片之间在采集时所造成的时间的差异。在整个大脑多层采集的过程中,由于不能一次扫描整个大脑的图像,所以需要分层扫描,煤层的采集时间会有轻微差异,所以需要校正保证每个切片的采集时间相同,对事件相关设计的实验非常重要。
头动校正:把整个试验队列过程的所有被试者的头部画像全和此实验中最先获得的头部画像按照某种特定的方法进行统一。目的是来纠正头部晃动。头动范围:平动<=2.0,旋转<=2.0度。在范围内就通过某方法去改正它,使它接近准确值;若不在,删除。
空间标准化:不同的被试验人员有着不同的脑部尺寸与形状。为了能统一处理,在实验之前需要对被试者的脑部图像标准化。将存在差异的被试者的脑部图像放到一个公用的空间中,然后用相同的规范形容具体的部位。
例如有多个头部形状各异的实验参加人员,如果接下来希望对他们做一个选取大脑某区域的试验,那么首先必须制定一个标准的空间脑模版,以便实现精准定位。平滑:由于磁共振扫描仪中含有大量噪音,会对采集的脑部图像产生一定影响。在SPM中,使用高斯函数对所获得的大脑图像进行去卷积,即平滑。来得到与原数据差异较小的图像。
-
使用SPM统计分析过程——统计模型的建立和估计过程
数据预处理后应运用相应措施提取大脑图像中的激活体素。
把与处理后的数据分为两个区域,即为感兴趣的区域和其他区域。
在数据分析步骤时,直接从感兴趣的区域来提取特征向量。使用广义线性模型(GLM)进行建模,首先要确定连接函数。
GLM的假设:每个像素点上的实验结果(Y)是某些参数的线性组合,参数未知,与具体的脑区(像素)无关,但与实验的任务和实验时间有关,这些参数组成的矩阵叫做设计矩阵。
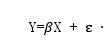
E代表误差
在通过GLM变换之后,求解参数发生改变,由原来对变量Y的统计分析变为对参数B的求解,通过对B进行拟合统计,进而可以得到脑功能激活图,步骤:
- 确认设计矩阵X的准确性
- 使用最小二乘法对参数B进行拟合,病史误差和达到最小
- 对参数B进行t检验或F检验
- 根据t检验或F检验的统计结果来推断参数B
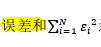
实验
实验目的:分析当被试者看到“喜悦”与“愤怒”的面部表情时,大脑内被激活的提速的状态。
首先,随机给被试者呈现不同表情图像刺激被试者,同时使被试者做出相应的面部表情;
接下来,用核磁共振仪扫描被试大脑,从而对大脑的活动进行成像;
然后,对得到的大脑图像使用SPM进行分析,获取有用的信息;
最后,讲实验所得标签输入分类器,对实验结果进行统计,得出准确率。
实验数据
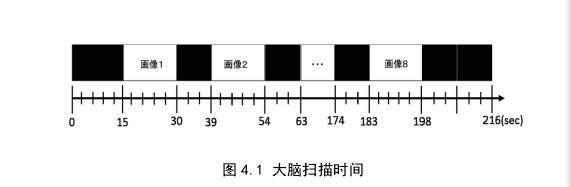
8名被试者,5男3女,均为 21、22 岁且身体健康,以避免性别、年龄对该实验结果所带来的影响。
实验中使用的刺激画像有愤怒和喜悦两种表现形式,为了更突出面部画像,将刺激画像的服装与背景均填充为灰色。
每个被试者做216秒的脑活动成像,8次大脑扫描,每次获得72个大脑活动切片,为了降低BOLD信号,在刺激画像之间呈现3次黑色背景扫描来稳定大脑,刺激画像随机呈现64张面部画像,32张喜悦32张愤怒。
数据预处理及其分析
使用 SPM 来对 f MRI 图像进行预处理、个人解析与集体解析。
从 f MRI 设备中取出原始图像是 DICOM 格式的图片
需要使用MRIConvert 软件将图像转换为所要分析格式的图像
通过 SPM 软件对被试者的 f MRI 图像进行了解析,从而获取了特征向量
根据实验中时间序列的记录,我们可以将特征向量与面部表情一一对应。从而形成了一个包含有特征向量与特征标签的数据,将该数据输入分类器中,我们就可以得到该实验的识别准确率,
分类器的选取
分别将支持向量机(SVM)和极限学习机(ELM)对所获得的数据进行分类,


控制变量法
数据维度的选取

实验结果分析
使用交叉验证法中的k折交叉验证来评估极限学习机的性能


总结
1.将机器学习算法极限学习机运用到fMRI数据的分类处理上,只用通过有效的特征才能获得高的准确率
2.刺激图像可以不局限于喜悦愤怒两种图像、不局限于静态图像、适当改变实验环境、适当改变ELM中隐藏层的层数、使用核极限学习机等神经网络作为分类器
读《基于FMRI脑信号的面部表情解码的研究》















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









