







数仓架构概览
- 离线数仓
- 实时数仓
- 数仓架构演进
- 1 传统数仓架构
- 2 Lambda架构
- 3 Kappa架构
- 4 混合架构
- 实时数仓架构
- 1 建设思路
- 2 建设方案
- 2.2 基于数据湖构建实时数仓
- 2.3 基于Doris构建实时数仓
- 2.4 流式湖仓 Flink + Paimon
离线数仓
离线数仓是一种用于存储和处理大规模历史数据的架构。它的目标主要是支持复杂分析和数据挖掘任务,通常以批处理的方式进行数据处理。离线数仓的主要特点包括以下几点:
- 1)数据积累和历史分析
离线数仓主要用于存储历史数据,这些数据可以是从多个源头采集而来,经过ETL(清洗、转换和加载)后存储在数仓中,这些数据被用于支持复杂的数据分析、业务报表和决策支持,数据延迟基本都是T+1形式。 - 2 周期性批处理
离线数仓中的数据主要是按照批处理的方式,通过一定时间周期(如每日、每周)去加载和处理。 - 3)复杂查询和分析
离线数仓可以连接不同的数据集,也可以跨多个维度执行聚合,排序等操作。通过复杂的查询和分析,可以展示出历史数据的变化趋势和价值数据的提取等。
实时数仓
实时数仓是一种用于存储和处理实时数据流的架构。它的主要目标是支持快速的实时数据分析、监控和反馈。实时数仓的特点包括:
- 1) 实时数据流处理
实时数仓通过数据流式处理技术,可以实时地处理来自各种源头的数据流,允许数据在进入系统后立即被处理和分析。这些数据可以是日志数据、业务交易数据和传感数据等。 - 2)低延迟处理
实时数仓更加注重数据处理的低延迟性,在确保数据进入系统后,希望以很快的速度对数据进行分析处理。 - 3)快速查询和分析
通过这种低延迟的方式对数据进行快速处理和分析,使得用户能够及时地探索数据,发现实时趋势和异常。
离线数仓和实时数仓在功能定位和使用场景上有较大区别,选择使用哪种架构取决于业务需求、数据的时效性要求和技术架构的能力等。
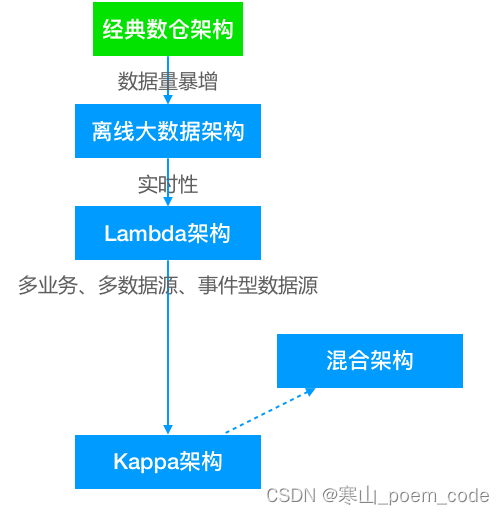
数仓架构演进
1 传统数仓架构

结构或半结构化数据通过离线ETL定期加载到离线数仓,之后通过计算引擎取得结果,供前端使用。采用大数据技术来承载存储与计算任务。
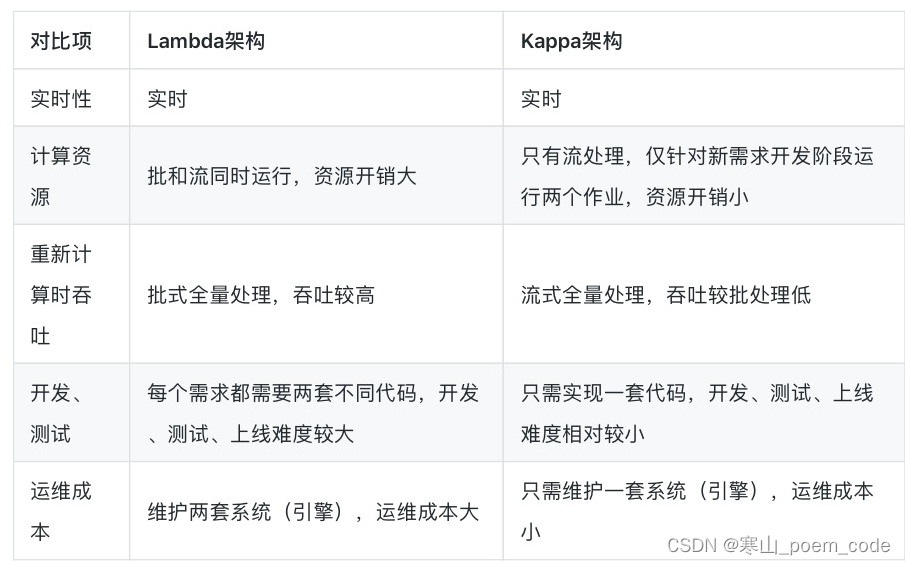
2 Lambda架构

3 Kappa架构
Kappa架构是大数据领域以流处理为主的主流实时数据分析架构之一,主要包含三部分:批处理层、流处理层和服务层,其核心思想是将数据分为冷热数据两类,冷数据走批处理层,热数据层走流处理层,但只使用一个数据处理管道来处理所有数据流。

优势:
- 适用于大规模、复杂的数据处理任务,具有高扩展性、高容错性和高性能等优点。
- 优化了Lambda架构,不需要将流批处理逻辑分离;
缺点:
- 数仓中只存储了处理计算后的结果,数据溯源难度大;
- 对集群计算资源要求高;

4 混合架构
上述架构各有其适应场景,有时需要综合使用上述架构组合满足实际需求。当然这也必将带来架构的复杂度。用户应根据自身需求,有所取舍。在一般大多数场景下,是可以使用单一架构解决问题。现在很多产品在流批一体、海量、实时性方面也有非常好的表现,可以考虑这种“全能手”解决问题。
实时数仓架构
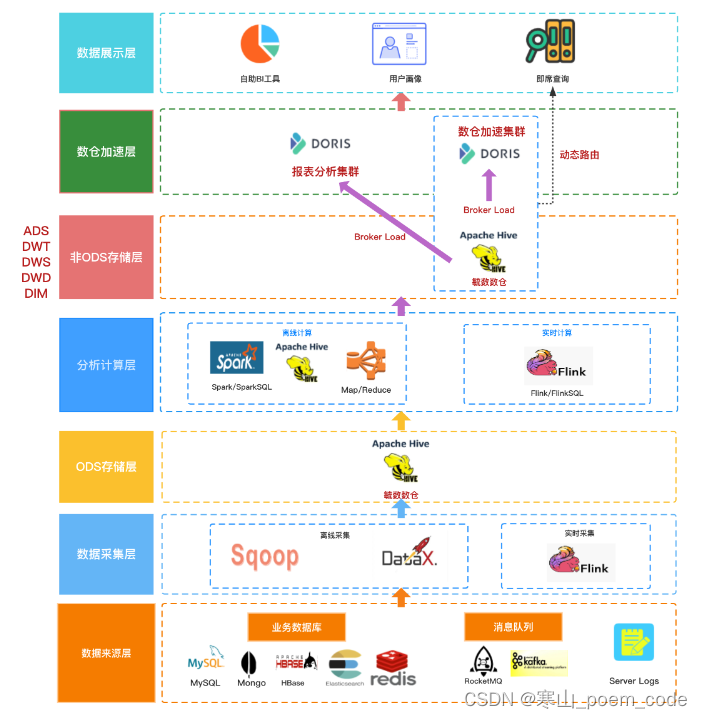
1 建设思路
**计算框架选型:**storm/flink等实时计算框架,强烈推荐flink,其『批量合一』的特性及活跃的开源社区,有逐渐替代spark的趋势。
**数据存储选型:**首要考虑查询效率,其次是插入、更新等问题,可选择apache druid,不过在数据更新上存在缺陷,选型时注意该问题频繁更新的数据建议不要采用该方案。当然存储这块需要具体问题具体分析,不同场景下hbase、starRocks和doris、paimon等都是可选项。
**实时数仓分层:**为更好的统一管理数据,实时数仓可采用离线数仓的数据模型进行分层处理,可以分为实时明细层写入doris等查询效率高的存储方便下游使用;轻度汇总层对数据进行汇总分析后供下游使用。
**数据流转方案:**实时数仓的数据来源可以为kafka消息队列,这样可以做到队列中的数据即可以写入数据湖用于批量分析,也可以实时处理,下游可以写入数据集市供业务使。
2 建设方案
##2.1 基于Kafka构建实时数仓
利用Kafka构建实时数仓也是目前业界比较流行的实时数仓架构之一。主要特点是在Kafka中进行数仓分层设计,所有数据都在Kafka的不同topic之间流转。

优势:
- 时效性高,能够快速分析出数据的变化趋势,满足实时要求;
- 符合数仓基本建设规范,分层明确,数据结构清晰
劣势:
- Kafka自身定位是一个缓冲管道,基于Kafka构建实时数仓不太符合规范;
- Kafka日志数据都具有一定时效性,数据可能会丢失;
- 当数据量过大时,数据溯源难度成几何增长;
- 需要较多的计算资源;
2.2 基于数据湖构建实时数仓
数据湖是一种存储架构,它使用分布式文件系统(如Hadoop HDFS)或对象存储(如Amazon S3)来存储各种类型和格式的原始数据,无论是结构化、半结构化还是非结构化数据。它支持存储大量的原始数据,无需事先定义数据模型或架构,这使得数据湖成为一个集中存储所有类型数据的地方。利用数据湖构建实时数仓和利用Kafka构建基本逻辑是一致的,只不过是数据存储介质发生了一些区别。
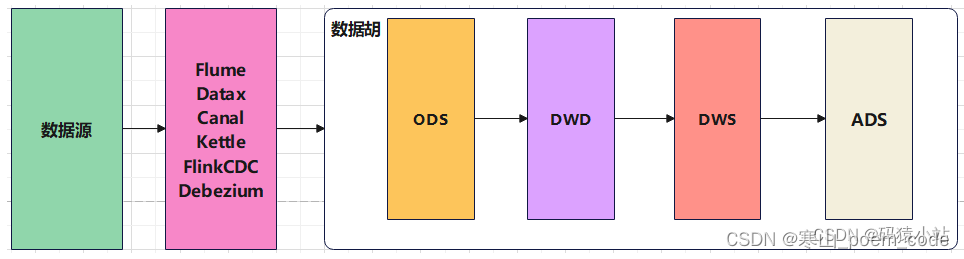
优势:
- 灵活性高,可以根据自己需求选定存储介质和计算引擎;
- 符合数仓基本建设规范,分层明确,数据结构清晰;
- 真正实现了流批一体计算;
- 数据湖产品多(iceberg,hudi,kudu),可以有多种选择方案;
劣势:
- 在处理大规模数据时需要大量的存储和计算资源;
- 构建和管理数据湖需要一系列不同的技术和工具,需要具备相应的技术能力和知识;
2.3 基于Doris构建实时数仓
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。

Apache Doris 2.0.0 版本正式发布:盲测性能 10 倍提升,更统一多样的极速分析体验
2.4 流式湖仓 Flink + Paimon
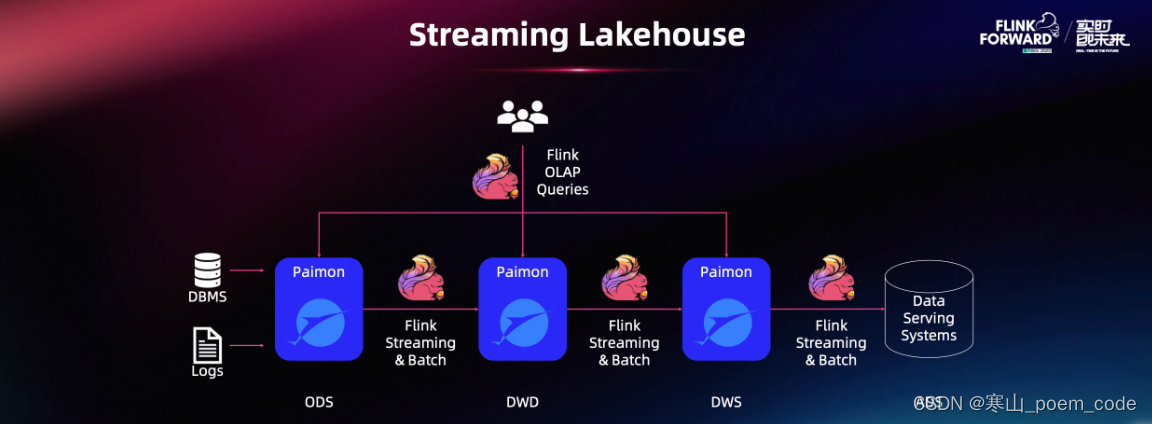

流计算迎来代际变革:流式湖仓 Flink + Paimon 加速落地、Flink CDC 重磅升级
部分图片来自网络,@码猿小站,侵删。















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









