







目录
一、前言
最近公司的一个项目,需要对一个功能模块进行性能验证,具体什么模块就不说了,验证过程中需要生成大量的随机数,因为程序是跑在一个单片机平台上的,所以没有像PC上的程序那样可以有各种随机数API调用,第一个想法是用个定时器不断的计数,将计数器的值当做随机数,但是需要在一个for循环里不断生成大量随机数,运行速度很快,定时器时间基本没太大变化,产生的数据关联性太强,所以这个想法落空了。第二个想法是通过ADC模块读取某个引脚上面的浮空电压来作为随机数,但是发现已经没有ADC资源可以用了,就算有ADC可以使用,因为ADC都是有精度的比如12位精度等等,生成的随机数范围也比较小。第三个想法是自己构建几个数学公式生成伪随机数,因为是自己随便捣鼓的,最后发现生成的随机数规律性和关联性太强,只能上网搜索看看有什么好的随机数生成方法了,于是在这里进行总结。
二、伪随机数发生器介绍
伪随机数生成法是目前使用最广发展最快的一类方法,它是应用数学公式迭代产生随机数 , 利用这种方法产生的随机数严格说来不是真正的随机数,通常称为伪随机数,若能通过一系列的统计检验,即如果具有真正随机数的一些统计性质 , 那也就可 以把它们当作真正随机数使用了,这种方法既经济又实惠,而且产生随机数的速度极快。
1、随机数的产生目前普遍采用软件的方法,即用某种算法,在计算机上产生随机数,其一般过程如下:
(1)首先确定一个数学模型或某种规则 。
(2)规定几个初始值 。
(3)按一定的步骤产生第一个随机数。
(4)用产生的上一个随机数作为新的初值,按同样的步骤产生下一个随机数,重复之,得一伪随机数序列,
2、一个良好的随机数发生器应当具备以下几个特性:
(1)产生的随机数要具有均匀总体随机样本的统计性质,如分布的均匀性,抽样的随机性,数列间的独立性等。
(2)产生的数列要有足够长的周期,以满足模拟计算的需要。
(3)产生数列的速度要快,占用计算机的内存少,具有完全可重复性。
三、均匀随机数发生器
注意:以下涉及到的随机数公式所有的参数都是无符号的整数。
1、线性同余法(LCG)
线性同余法是目前应用最广泛的方法之一,很多编程语言的随机数生成API也有采用这种方法,它利用数论中的同余运算来产生随机数,所以称为同余发生器,一般递推公式为:
![]()
其中a、c、m都是常数,{}产生的随机数序列,即用上一个随机数
根据公式再算出下一个随机数
,一开始时要给个初值
,也叫随机数种子。因为后面加了个取模m的运算,所以产生的随机数范围是0到m。C语言的rand()函数也采用了这种方法,如下:
static unsigned long int next = 1;
int rand(void) // RAND_MAX assumed to be 32767
{
next = next * 1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}
void srand(unsigned int seed)
{
next = seed;
}
2、反馈位移寄存器法(FSR)
用线性同余法产生的随机数有一些缺点,即产生的随机数作为m(m>1)维均匀随机变量时相关性大,同时产生的均匀随机数数列的周期与计算机字长有关,周期T不可能大于最大变量的整数取值范围。反馈位移寄存器法通过对寄存器进行位移,直接在存储单元中形成随机数,速度很快,很多MCU主控里集成的随机数模块都采用了如下类似的方法,如下递推公式:
![]()
这里的序列{a}是二进制序列,其中p > q,说白了就是我们需要先有一个原始的二进制序列,然后后面每一个新生成的比特位都是由前面某两个(或者更多个)比特位经过异或运算而生成的,
3、组合随机数发生器
将不同的随机数发生器进行级联组合,用一种随机数发生器产生的随机数作为下一个随机数发生器的种子或者用来扰乱另一个随机数发生器,以此来获得比单一随机数发生器更好的效果。例如两个线性同余发生器进行组合,第一个随机数发生器产生随机数作为下一个发生器的c参数来对下一个随机数发生器进行扰动,以获得比单一随机数发生器更长的随机数周期。
四、任意概率分布的随机数发生器
在实际应用中,我们需要的可能并不是完全均匀的随机数,我们可能需要的是在某个区域具有正态分布、指数分布等等特性的随机数。上面介绍了均匀分布的随机数的产生,我们可以通过各种变换及映射关系来得到任意概率分布的随机数,主要的方法有反函数法、变换法和舍选法等,个人还是推荐舍选法,更简单,计算量也小。
1、反函数法
通过反函数法产生任意分布伪随机数的方法是最常用的方法之一 , 其数学原理是 :已知[ 0 , 1] 区间上均匀分布的伪随机数 r , 将所需的概率分布的伪随机数函数F(x)进行反变换 ,得到F(x)的反函数 , 令 X =
,则 X 就是服从概率分布函数为F(x)的伪随机数。因此,只要知道所需概率分布函数的反函数,就可以从[ 0, 1] 均匀分布的伪随机数产生服从所需分布的随机数 。
例(1):已知 r ~ U(0 , 1), 求服从指数分布的随机变量 X 。
解 :因为指数分布函数为 :
![]()
可以求得F(x)的反函数为:
![]()
r ~ U(0 , 1),令,则X服从概率分布函数为 F(x)的指数分布 。即X就是所求的随机变量 。
2、变换法
变换法通过一个变换将一个分布的随机数变换成为不同分布产生的随机数 , 例如常用的线性变换能够把一个有限区间[ a , b] 上的分布变换到任意实数区间[ u , v] 上 。对于每一个 X 值 , 都能够根据下式给出Y 值 :
![]()
变换法的典型例子是 Box - Muller变换,它可产生精确的正态分布随机变量。其变换式为 :
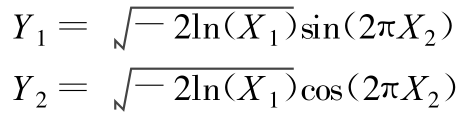
,
是在区间[ 0 ,1] 上均匀分布的随机变量,所得的
、
是相互独立的服从期望值 μ=0,方差
=1 的正态分布的随机变量 。
3、舍选法
用反函数法需要知道所求概率分布函数的反函数,当反函数不存在或难以求出时,反函数法便难以使用。这时可以考虑使用舍选法 。
舍选法是冯·诺曼为克服反函数法和变换法的困难最早提出来的 ,它的基本思想是:按照给定的分布密度函数 f(x),对均匀分布的随机数序列{R}进行舍选。舍选的原则是在 f(x)大的地方,保留较多的随机数;在 f(x)小的地方,保留较少的随机数
,使得
到的子样本中的分布满足分布密度函数的要求 。
设随机变量 X 的概率密度函数为f(x),又存在实数 a<b,使得 P(a <X < b)=1,如图所示:
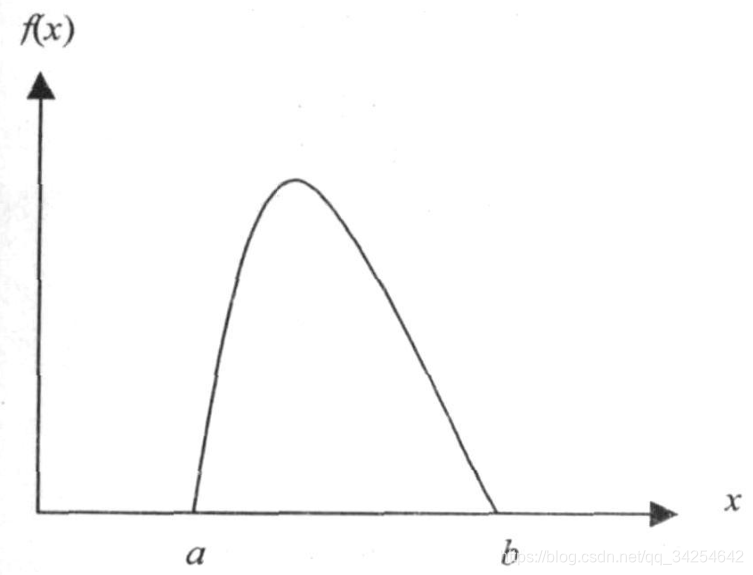
(1)选取常数,使得
,
;
(2)产生在[0, 1]上均匀分布的随机数和
,令y = a + (b - a)
;
(3)比较与
,若
,则输出y,重返步骤(1)。
如此重复循环,产生的随机数序列的分布由概率密度f(x)确定。
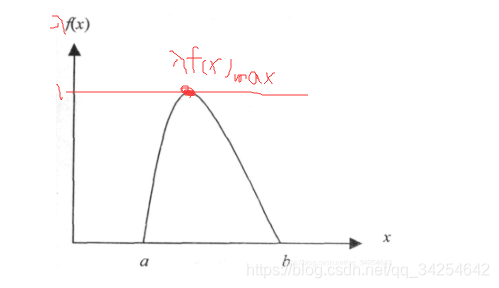
上面都是原本的数学描述,下面通俗的来解释一下,可以理解为如下的图像有一条y =
=1的直线与分布曲线相切与顶点。然后从产生两个均匀随机数
和
,
的大小是0~1之间,把它线性转换一下映射到a~b之间的区间,作为一个变量值传给
这个函数会得到一个值y,这个y值是0~1之间的,y是在
曲线上均匀取值的,
是在0~1均匀取值的,但是y取到的点越靠近
这个点它的值就越大,即y(
)确定的情况下,让
不断的变化,
成立的可能性就越大,取到的这样的
就越多,就达到了函数值大的地方,随机数取的就越多,函数值越小的地方,随机数取得就越少的目的。
以下是产生0到500以内满足f(x) = 分布的随机数的Python代码和图像,X轴为随机数的具体数值,Y轴为该随机数产生的个数,产生均匀随机数的函数直接调用了Python的API:
import matplotlib.pylab as plt
import random
rndList = {}
for i in range(500000):
rnd1 = random.randint(0, 500)
rnd2 = random.randint(0, 500)
if 500*rnd2 < (rnd1)**2:
if rnd1 not in rndList:
rndList[rnd1] = 1
else:
rndList[rnd1] += 1
plt.bar([x for x in rndList], [rndList[x] for x in rndList])
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('随机数值')
plt.ylabel('产生的次数/次')
plt.show()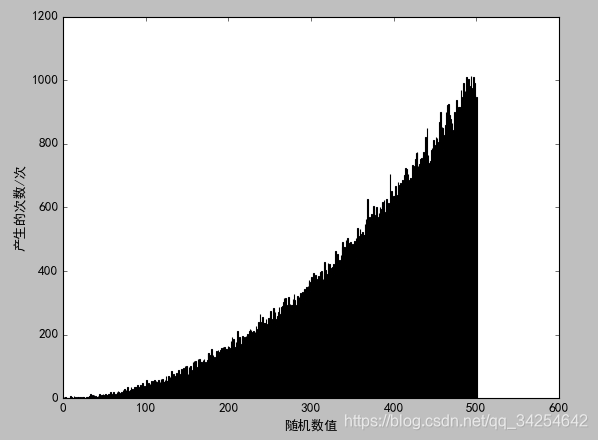
当然可以适当改动一下再看另外一个效果,产生0到500以内满足f(x) = 分布的随机数的Python代码和图像::
import matplotlib.pylab as plt
import random
rndList = {}
for i in range(500000):
rnd1 = random.randint(0, 500)
rnd2 = random.randint(0, 500)
if 500*rnd2 < (rnd1 - 200)**2:
if rnd1 not in rndList:
rndList[rnd1] = 1
else:
rndList[rnd1] += 1
plt.bar([x for x in rndList], [rndList[x] for x in rndList])
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('随机数值')
plt.ylabel('产生的次数/次')
plt.show()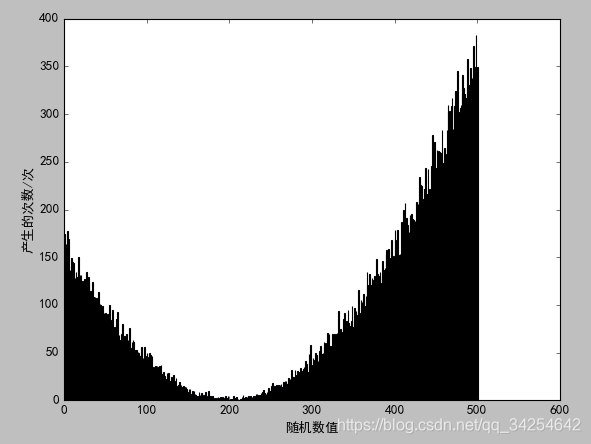
当然,Python是自带有产生各种分布的随机数的API可以调用的,这里用Python为例子只是为了更方便的画统计图,实际的使用场景更多的应该是C语言,这里就不翻译成C了。
五、产生特定要求的随机数
1、产生某个范围内所有的随机数。
在某些时候,我们想产生某个范围内的所有随机数,可以转换一下思路,其实就是先产生这个区域内的数,直接从小到大列出来这些数在一个缓存里面,然后使用随机数发生器产生两个均匀随机数,把它们分别对应的序号的数进行位置互换,区域内经过多次的位置互换后,就达到了该区域所有随机数打乱顺序的目的。当然,如果该区域内不想要某些数,在缓存里面就不要放这些数,然后再打乱缓存里数的顺序。
2、其他的要求
想到了以后继续补写,随机数发生器产生的随机数各方面性质好不好是需要经过一些数学方式的检验的,在网上找到了一些论文和资料,放在最后的链接里。
六、参考资料
《如何产生指定分布的随机数?》https://blog.csdn.net/fengying2016/article/details/80593266
[1]朱晓玲,姜浩.任意概率分布的伪随机数研究和实现[J].计算机技术与发展,2007(12):116-118+168.
[2]林立东. 伪随机数发生器及其应用[D].暨南大学,2002.
[3]杨自强,魏公毅.常见随机数发生器的缺陷及组合随机数发生器的理论与实践[J].数理统计与管理,2001(01):45-51+66.
[4]闵敏.密码学中伪随机数的产生问题[J].常州技术师范学院学报,2001(04):36-39.
链接:https://pan.baidu.com/s/1GX3R_rgPSjAYAcgURwuaVg 提取码:dlx3

















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









