









github:https://github.com/viktorika/mit-os-lab
Introduction
在这次lab中,您将实现spawn,这是一个加载和运行磁盘可执行文件的库调用。 然后,您将充实kernel和库操作系统,以在控制台上运行Shell。
Getting Started
照以往的lab一样,创建分支,然后merge。
本部分lab的主要新组件是文件系统环境,位于新的fs目录中。 扫描此目录中的所有文件,以了解所有新内容。 另外,在user和lib目录中还有一些与文件系统相关的新的源文件。

合并新的lab5代码后,您应该再次运行lab4的pingpong,primes和forktree测试用例。 您将需要在kern / init.c中注释掉ENV_CREATE(fs_fs)行,因为fs / fs.c尝试执行某些I / O,而JOS尚不允许这样做。 同样,在lib / exit.c中暂时注释掉对close_all()的调用; 此函数将调用子例程,这些子例程将在以后的实验中实现,因此,如果被调用,它将会panic。 如果您的lab4代码不包含任何错误,则测试用例应运行良好。 在他们能正常工作前,不要执行下面的步骤。 开始exercise 1时,不要忘记取消注释这些行。
如果它们不能工作,请使用git diff lab4来检查所有更改,并确保您没有为lab4(或更早版本)编写的任何代码都没有在lab 5中丢失。请确保lab 4仍然有效。
File system preliminaries
我们为您提供了一个简单的,基于磁盘的只读文件系统。 您将需要稍微更改现有代码,以便为您的JOS移植文件系统,以便使spawn可以使用路径名访问磁盘上的可执行文件。 尽管您不必了解文件系统的每个细节,例如其磁盘结构, 熟悉设计原理及其各种接口是非常重要的。
文件系统本身以微内核方式在内核外部但在其自己的用户空间environment中实现。 其他环境通过向此特殊文件系统environment发出IPC请求来访问文件系统。
Disk Access
操作系统中的文件系统environment需要能够访问磁盘,但是我们尚未在kernel中实现任何磁盘访问功能。 我们没有采用将kernel磁盘添加IDE磁盘驱动程序以及允许文件系统访问它的必要系统调用的常规“整体”操作系统策略,而是将IDE磁盘驱动程序实现为用户级文件系统environment的一部分。 我们仍然需要稍微修改kernel,以便进行设置,以便文件系统environment具有实现磁盘访问本身所需的特权。
只要我们依靠轮询,基于polling“programmed I / O”(PIO)的磁盘访问并且不使用磁盘中断,就很容易以这种方式在用户空间中实现磁盘访问。 也可以在用户态下实现中断驱动的设备驱动程序(例如,L3和L4内核执行此操作),但是由于kernel必须现场中断设备并将其分派到正确的用户态environment,因此更加困难。 。
x86处理器使用EFLAGS寄存器中的IOPL位来确定是否允许protect mode代码执行特殊的设备I / O指令,例如IN和OUT指令。 由于我们需要访问的所有IDE磁盘寄存器都位于x86的I / O空间中,而不是位于内存映射中,因此,我们唯一需要做的就是为文件系统environment赋予“ I / O特权”。 允许文件系统访问这些寄存器。 实际上,EFLAGS寄存器中的IOPL位为kernel提供了一种简单的“全有或全无”方法,用于控制用户态代码是否可以访问I / O空间。 在我们的情况下,我们希望文件系统environment能够访问I / O空间,但是我们根本不希望其他environment能够访问I / O空间。
Exercise 1. i386_init通过将ENV_TYPE_FS类型传递给您的environment创建函数env_create来标识文件系统environment。 修改env.c中的env_create,以便它赋予文件系统environmentI / O特权,但绝不将该特权赋予其他environment。
确保可以启动文件environment而不会引起一般保护错误。 您应该在make grade中通过“ fs i / o”测试。
这个白给的。
void
env_create(uint8_t *binary, size_t size, enum EnvType type)
{
// LAB 3: Your code here.
struct Env *env;
int result = env_alloc(&env, 0);
if(result < 0)
panic("env_create: env_alloc error");
load_icode(env, binary, size);
env->env_type = type;
// If this is the file server (type == ENV_TYPE_FS) give it I/O privileges.
// LAB 5: Your code here.
if(type == ENV_TYPE_FS)
env->env_tf.tf_eflags |= FL_IOPL_MASK;
}
Question1.当您随后从一种environment切换到另一种environment时,是否还需要执行其他操作以确保正确保存和恢复此I / O特权设置? 为什么?
answer:这肯定是不用的,每次切换进程都会保存上下文,切回来的时候恢复上下文。
The Block Cache
在我们的文件系统中,我们将借助处理器的虚拟内存系统实现一个简单的“buffer cache”(实际上只是一个block cache)。 block cache的代码在fs / bc.c中。(这里其实就暗示了文件系统读写的单位是一个block而不是扇区)。
我们的文件系统将只能处理3GB或更小的磁盘。 我们保留文件系统environment地址空间的固定大3GB区域,从0x10000000(DISKMAP)到0xD0000000(DISKMAP + DISKMAX),作为磁盘的“内存映射”版本。 例如,磁盘块0映射到虚拟地址0x10000000,磁盘块1映射到虚拟地址0x10001000,依此类推。 fs / bc.c中的diskaddr函数实现了从磁盘块号到虚拟地址的转换(以及一些完整性检查)。
由于我们的文件系统environment具有自己的虚拟地址空间,而与系统中其他environment的虚拟地址空间无关,并且文件系统environment唯一需要做的就是实现文件访问,因此我们以这种方式保留大多数文件系统environment的地址空间。 由于现代磁盘大于3GB,因此在32位计算机上执行真实文件系统会很尴尬。 在具有64位地址空间的机器上,这种buffer cache管理方法仍然是合理的。
当然,将整个磁盘读入内存是不合理的,因此,我们将实现一种形式的需求分页,其中,我们仅在磁盘映射区域中分配页面,并响应于页面而从磁盘中读取相应的块。假装整个磁盘都在内存里。
Exercise 2. 在fs / bc.c中实现bc_pgfault函数。 bc_pgfault是一个页面错误处理程序,就像您在上一个lab中为copy-on-write fork的写的页面处理程序一样,不同之处在于bc_pgfault的工作是响应页面错误从磁盘加载页面。 编写此代码时,请记住,addr可能未与block对齐,并且ide_read在扇区而不是block中操作。
使用make grade测试,此时你应该通过check_super例子。
fs / fs.c中的fs_init函数是如何使用块缓存的主要示例。 初始化块高速缓存后,它仅将指针存储到超级全局变量中的磁盘映射区域中。 在这之后,我们可以简单地从超级结构中读取它们,就像它们在内存中一样,并且页面错误处理程序将根据需要从磁盘读取它们。
代码如下,先对齐,分配页面然后读进来。这是个页面错误处理函数,所以不用担心他之前有被读过一次。
// loading it from disk.
static void
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary.
//
// LAB 5: you code here:
addr = ROUNDDOWN(addr, PGSIZE);
if(sys_page_alloc(0, addr, PTE_P|PTE_U|PTE_W) < 0)
panic("bc_pgfault: sys_page_alloc error\n");
if(ide_read(blockno * BLKSECTS, addr, BLKSECTS) < 0)
panic("bc_pgfault: ide_read error\n");
}
The file system interface
现在我们已经在文件系统environment本身中具有必要的功能,我们必须使它可以被希望使用文件系统的其他environment访问。 由于其他environment不能直接在文件系统environment中调用函数,因此我们将通过在JOS的IPC机制之上构建的远程过程调用或RPC(抽象)公开对文件系统environment的访问。 图上来说,这是对文件系统server的调用。

虚线下方的所有内容只是从常规environment向文件系统environment获取读取请求的机制。 从一开始,read(我们提供的)就可以在任何文件描述符上工作,并简单地分派到适当的设备读取功能,在这种情况下为devfile_read(我们可以有更多设备类型,例如管道)。 devfile_read实现专门针对磁盘文件的读取。 lib / file.c中的此函数和其他devfile_ *函数实现了FS操作的客户端,并且所有工作都以大致相同的方式进行,将参数捆绑在请求结构中,调用fsipc发送IPC请求,然后解包并返回 结果。 fsipc函数仅处理将请求发送到server并接收答复的常见细节。
文件系统server代码可以在fs / serv.c中找到。 它循环服务功能,无休止地通过IPC接收请求,将该请求分派到适当的处理程序功能,然后通过IPC发送回结果。 在读取示例中,serve将分派到serve_read,后者将处理特定于读取请求的IPC详细信息,例如解压缩请求结构并最终调用file_read来实际执行文件读取。
回想一下,JOS的IPC机制使环境可以发送单个32位数字,并可以选择共享页面。 要将请求从client发送到server,我们使用32位数字作为请求类型(对文件系统服务器RPC进行编号,就像对系统调用进行编号一样),并将请求的参数存储在联合Fsipc上。 通过IPC共享的页面。 在client,我们总是在fsipcbuf上共享页面; 在server端,我们将传入的请求页面映射到fsreq(0x0ffff000)。
server还通过IPC发送回响应。 我们使用32位数字作为函数的返回码。 对于大多数RPC,这就是它们返回的全部内容。 FSREQ_READ和FSREQ_STAT也返回数据,它们只需将其写入client发送其请求的页面即可。 无需在响应IPC中发送此页面,因为client首先与文件系统server共享了该页面。 同样,在响应中,FSREQ_OPEN与client共享一个新的“ Fd页面”。 我们将很快返回文件描述符页面。
--------------------------------------------------------------------------------------------------------------------------------
TODO challenge
--------------------------------------------------------------------------------------------------------------------------------
Spawning Processes
我们为您提供了spawn的代码,该代码创建了一个新environment,将文件系统中的程序映像加载到其中,然后启动运行该程序的子environment。 然后,父进程继续独立于子进程继续运行。 在UNIX中,spawn函数的作用类似于分叉,后跟子进程中的立exec。
我们实现的spawn替代UNIX风格的exec,因为在用户空间中以“ exokernel fashion”更容易实现spawn,而无需内核的特殊帮助。 考虑一下要在用户空间中实现exec所必须执行的操作,并确保您了解为什么这样做更难。
Exercise 3.. spawn依赖于新的syscall sys_env_set_trapframe来初始化新创建的environment的状态。 实现sys_env_set_trapframe。 通过运行kern / init.c中的user / spawnhello程序来测试您的代码,该程序将尝试从文件系统中spawn / hello。
使用make grade测试代码。
就加一个系统调用,同样要记得在dispatch里加上新的接口。
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
// LAB 5: Your code here.
// Remember to check whether the user has supplied us with a good
// address!
struct Env *env;
int result = envid2env(envid, &env, 1);
if(result < 0)
return result;
env->env_tf = *tf;
return 0;
}
--------------------------------------------------------------------------------------------------------------------------------
TODO challenge
--------------------------------------------------------------------------------------------------------------------------------
Sharing library state across fork and spawn
UNIX文件描述符是一个通用概念,它还包含管道,控制台I / O等。在JOS中,这些设备类型中的每一个都有对应的struct Dev,以及指向实现读/写/等功能的指针来针对该设备类型。 lib / fd.c在此之上实现了通用的类UNIX的文件描述符接口。 每个struct Fd都指示其设备类型,并且lib / fd.c中的大多数函数只是将操作分派给相应的struct Dev中的函数。
lib / fd.c还从FSTABLE开始在每个应用程序environment的地址空间中维护文件描述符表区域。 该区域为应用程序可以一次打开的最多MAXFD(当前为32个)文件描述符中的每个文件保留一个页面的地址空间(4KB)。 在任何给定时间,当且仅当使用相应的文件描述符时,才会映射特定的文件描述符表页面。 每个文件描述符在从FILEDATA开始的区域中还具有一个可选的“数据页”,设备可以选择使用它们。
我们希望在fork和spawn之间共享文件描述符状态,但是文件描述符状态保留在用户空间内存中。 现在,在fork时,内存将被标记为copy-on-write,因此状态将被复制而不是共享。 (这意味着environment将无法在未打开的文件中进行搜索,并且管道将无法在fork上工作。)在spawn时,内存将被共享,根本不会被复制。 (有效地,spawn的environment不会打开任何文件描述符。)
我们将更改fork以了解某些内存区域已由“操作系统库”使用,并且应始终共享。 与其在某处硬编码区域列表,不如在页表条项设置一个otherwise-unused的位(就像我们对fork中的PTE_COW位所做的那样)。
我们在inc / lib.h中定义了一个新的PTE_SHARE位。 该位是Intel和AMD手册中标记为“可用于软件使用”的三个PTE位之一。 我们将建立一个约定,如果页表项设置了该位,则应该在fork和spawn中将PTE直接从父级复制到子级。 请注意,这不同于将其标记为“copy-on-write”:如第一段所述,我们要确保共享页面更新。
Exercise 4. 在lib / fork.c中更改duppage以遵循新约定。 如果页表项设置了PTE_SHARE位,则直接复制映射。 (您应该使用PTE_SYSCALL而不是0xfff来mask页表条目中的相关位。0xfff也会拾取访问的位和脏位。)
同样,在lib / spawn.c中实现copy_shared_pages。 它应该遍历当前进程中的所有页表项(就像fork一样),将所有已设置PTE_SHARE位的页映射复制到子进程中。
使用make run-testpteshare检查您的代码是否正常运行。 您应该看到显示“ fork handles PTE_SHARE right”和“ spawn handles PTE_SHARE right”的行。
使用make run-testfdsharing检查文件描述符是否正确共享。 您应该看到显示“read in child succeeded”和“read in parent succeeded”的行。
按描述写应该就是下面这样。
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
void *addr = (void *)(pn * PGSIZE);
if(uvpt[pn] & PTE_SHARE){
if(sys_page_map(0, addr, envid, addr, uvpt[pn] & PTE_SYSCALL))
panic("duppage: sys_page_map pte_syscall error");
}
else if(uvpt[pn] & (PTE_W | PTE_COW)){
//如果是可写或者是copy-on-write
//先对子进程映射
if(sys_page_map(0, addr, envid, addr, PTE_COW|PTE_U|PTE_P))
panic("duppage: sys_page_map child error");
//重新映射父进程
if(sys_page_map(0, addr, 0, addr, PTE_COW|PTE_U|PTE_P))
panic("duppage: sys_page_map remap parent error");
}
else{
//如果是其他情况则直接拷贝父进程
if(sys_page_map(0, addr, envid, addr, PTE_U|PTE_P))
panic("duppage: other sys_page_map error");
}
return 0;
}
copy_share_pages完全参照上面写就好。
// Copy the mappings for shared pages into the child address space.
static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
unsigned addr;
for(addr = UTEXT; addr < USTACKTOP; addr += PGSIZE){
int page_num = PGNUM(addr);
if((uvpd[PDX(addr)] & PTE_P) && ((uvpt[page_num] & (PTE_P | PTE_U | PTE_SHARE)) == (PTE_P | PTE_U | PTE_SHARE)))
if(sys_page_map(0, (void *)addr, child, (void *)addr, uvpt[page_num] & PTE_SYSCALL))
panic("copy_shared_pages: sys_page_map error\n");
}
return 0;
}
The keyboard interface
为了使shell正常工作,我们需要一种键入方式。 QEMU一直在显示我们写入CGA显示器和串行端口的输出,但是到目前为止,我们仅在kernel监视器中才接受输入。 在QEMU中,在图形窗口中键入的输入显示为从键盘到JOS的输入,而在控制台中键入的输入显示为串行端口上的字符。 从lab1开始,kern / console.c已经包含了kernel监视器使用的键盘和串行驱动程序,但是现在您需要将它们附加到系统的其余部分。
Exercise 5. 在您的kern / trap.c中,调用kbd_intr处理trap IRQ_OFFSET + IRQ_KBD,并调用serial_intr处理trap IRQ_OFFSET + IRQ_SERIAL。
我们在lib / console.c中为您实现了控制台输入/输出文件类型。
通过运行make run-testkbd并键入几行来测试代码。 系统会在完成线路后echo您的线路。 如果两者都可用,请尝试在控制台和图形窗口中都输入。
case IRQ_OFFSET + IRQ_KBD:{
// Handle keyboard and serial interrupts.
// LAB 5: Your code here.
serial_intr();
break;
}
The Shell
运行make run-icode或make run-icode-nox。 这将运行您的kernel并启动user/ icode。 icode execs init,它将控制台设置为文件描述符0和1(标准输入和标准输出)。 然后它将生成sh,shell。 您应该能够运行以下命令:

请注意,用户库例程cprintf无需使用文件描述符代码即可直接打印到控制台。 这对调试很有用,但对管道连接到其他程序却不利。 要将输出打印到特定的文件描述符(例如1,标准输出),请使用fprintf(1,“ ...”,...)。 printf(“ ...”,...)是打印到FD 1的快捷方式。有关示例,请参见user / lsfd.c。
运行make run-testshell来测试您的shell。 testshell只是将上述命令(也可以在fs / testshell.sh中找到)输入到Shell中,然后检查输出是否与fs / testshell.key相匹配。
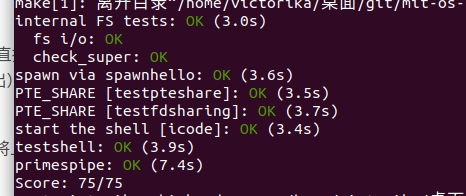
此时,您的代码应通过所有测试。 与往常一样,您可以使用make grade对提交的内容进行评分,并通过make handin提交。















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









