if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")
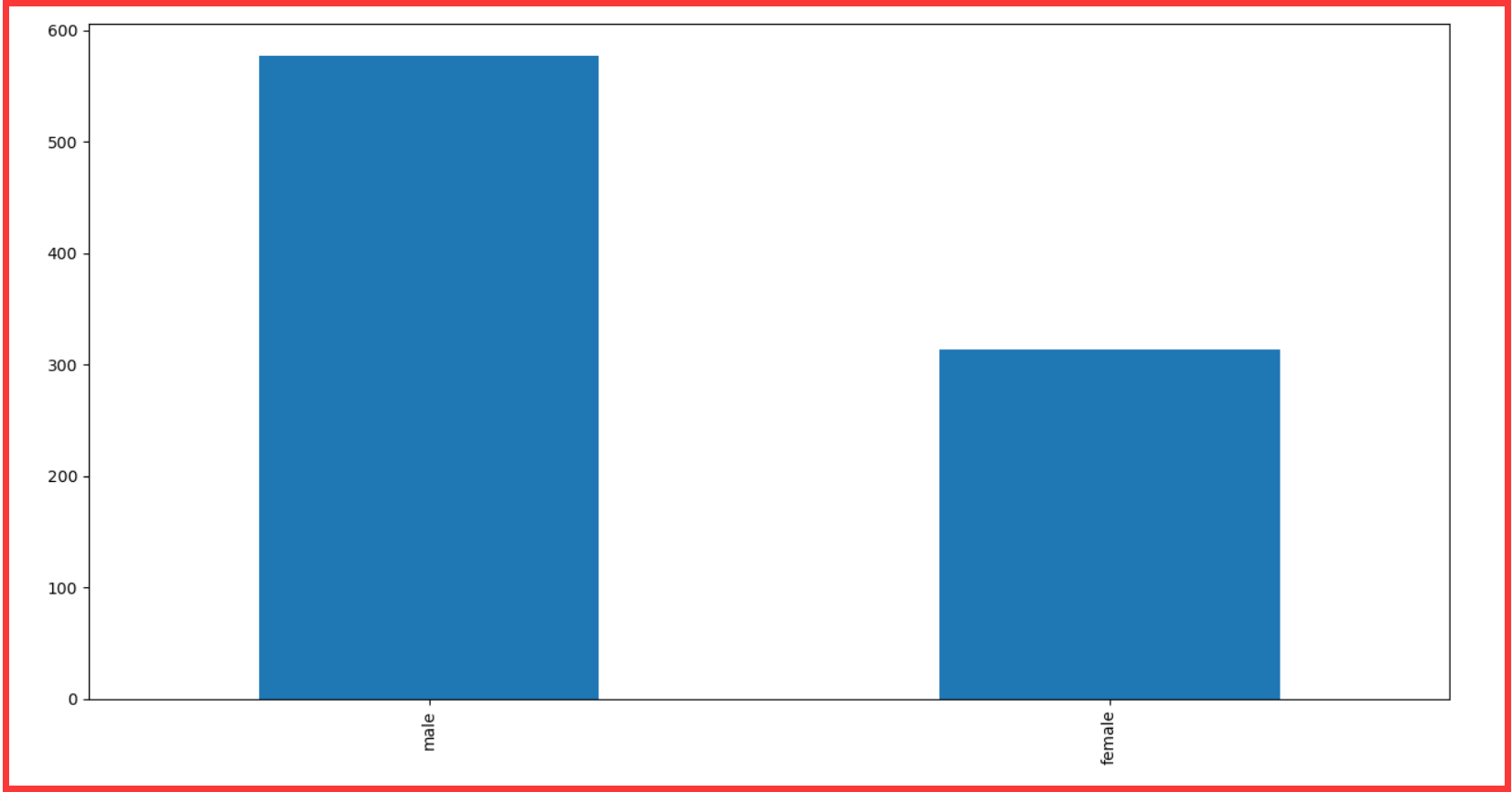
series = data.Sex.value_counts()
series.plot(kind="bar")
plt.show()
图 :
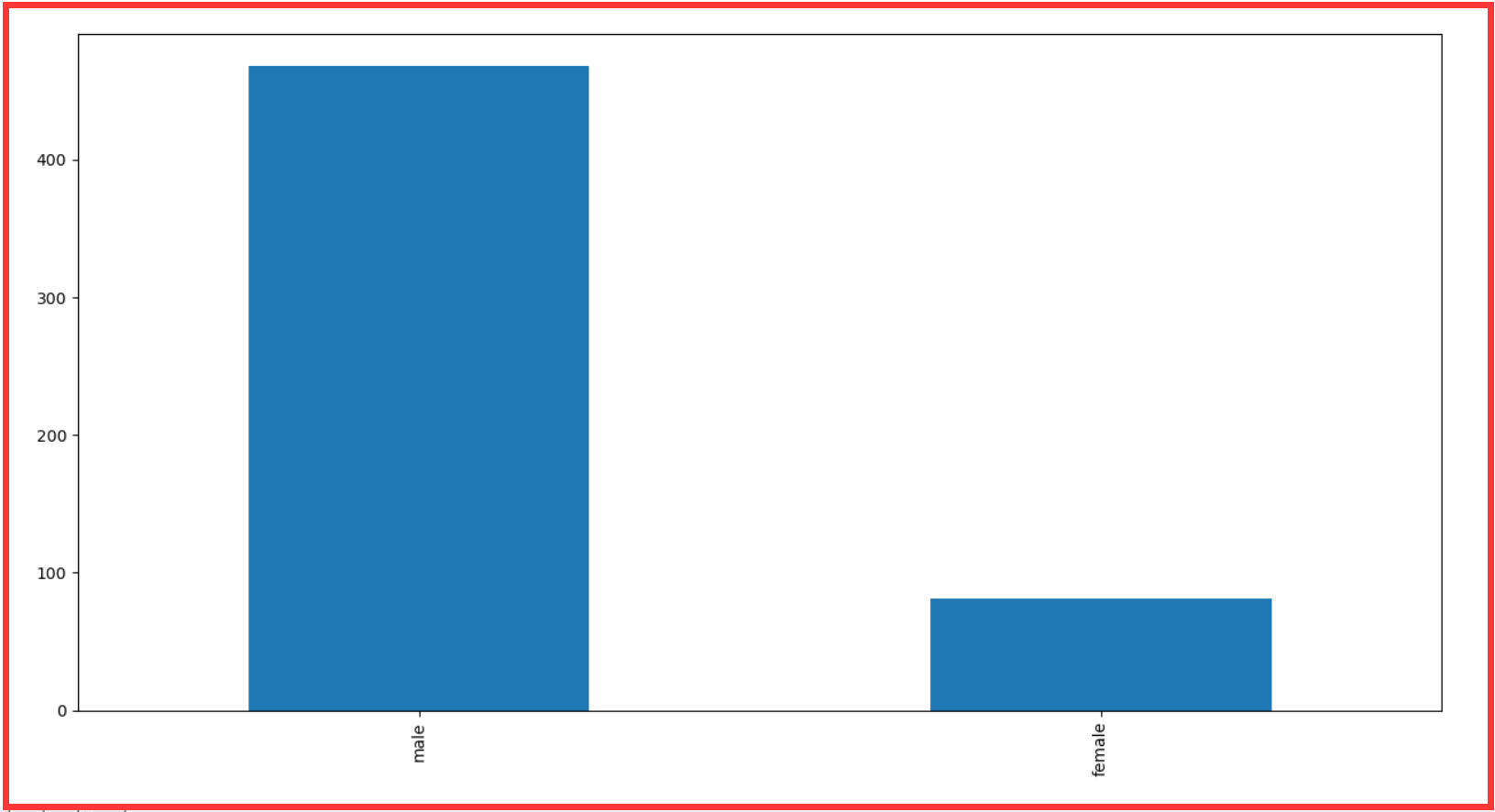
2 ,死亡 : 男女人数 ( 多条件筛选 )
死亡男人 : 468
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
some = data[(data['Survived']==0)&(data["Sex"]=="male")]
numMale = some.shape[0]print(numMale)
死亡女人 : 81
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
some = data[(data['Survived']==0)&(data["Sex"]=="female")]
numMale = some.shape[0]print(numMale)
死亡总人数 : 549
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
ser = data[data["Survived"]==0]
num = ser.shape[0]print(num)
死亡人数 : 比例图
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
ser = data[data["Survived"]==0]
ser.Sex.value_counts().plot(kind='bar')
plt.show()
结果 :
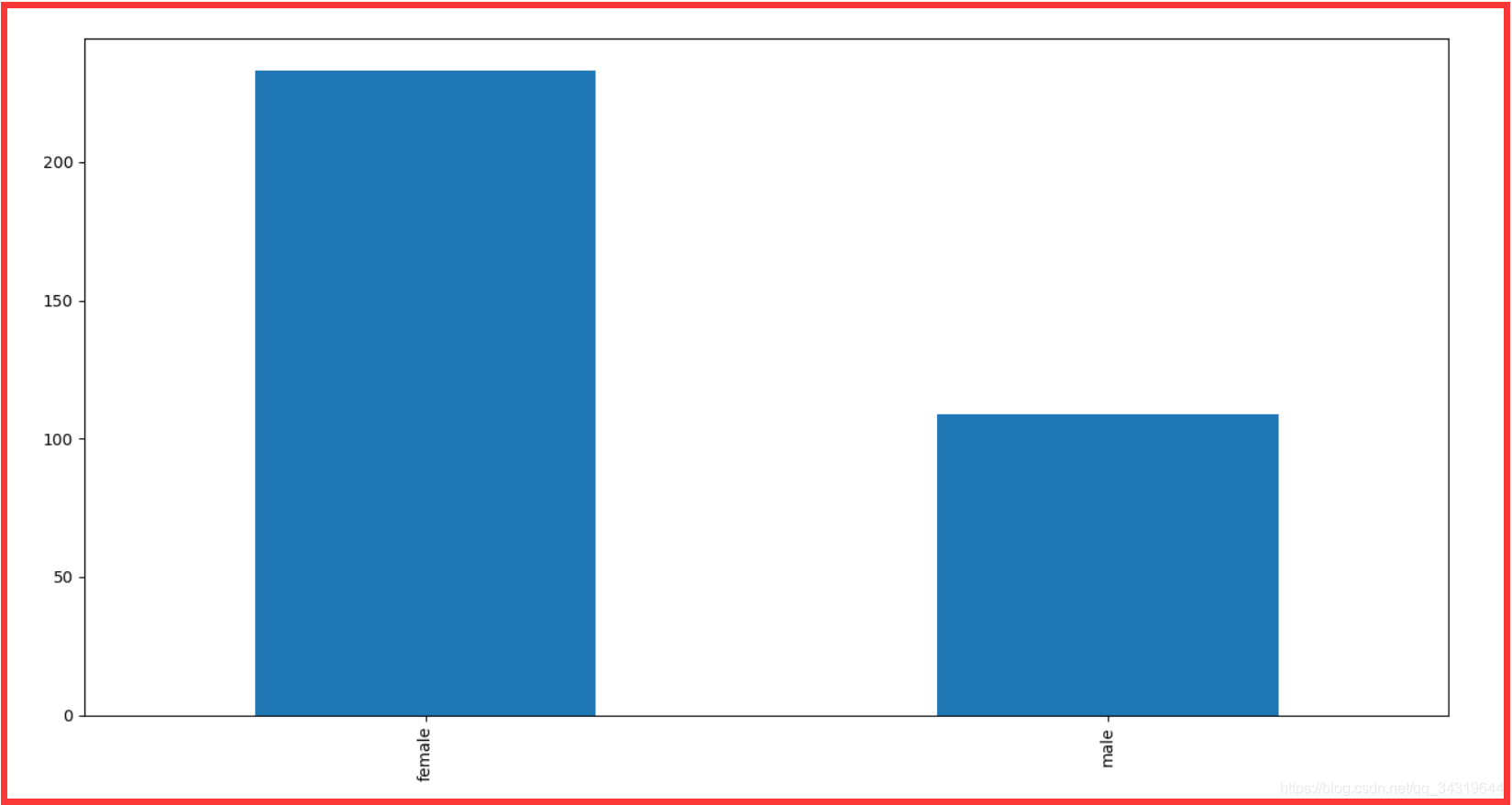
3 ,幸存人数对比 :男女比例
代码 :
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
ser = data[data["Survived"]==1]
ser.Sex.value_counts().plot(kind='bar')
plt.show()
结果 :
4 ,年龄分析 :
求平均年龄 : 29
if __name__ =='__main__':
data = pd.read_csv("titanic_train.csv")
avage = data["Age"].mean()print(avage)
mean 的含义 : 不要 null ,计算的时候,只保留有值的数据一起计算,没有值的数据,不参与总数量计算,也不参与总年龄计算
5 ,pivot_table : 分组函数
代码 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Pclass",values="Fare",aggfunc=np.mean)print(res)
结果 :
Fare
Pclass
184.154687220.662183313.675550
6 ,船舱等级 : 每个等级的均价,获救人数
代码 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Pclass",values="Fare",aggfunc=np.mean)print(res)
结果 :
Fare
Pclass
184.154687220.662183313.675550
每个等级生还的人数 ( 0-死,1-生 ),1 等仓生还率最高
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Pclass",values="Survived",aggfunc=np.mean)print(res)
结果 :
Pclass
10.62963020.47282630.242363
每个船舱等级 : 平均年龄 ( 1 等仓年龄最大 )
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Pclass",values="Age",aggfunc=np.mean)print(res)
结果 :
138.233441229.877630325.140620
7 ,登船地点 : 数据分析
每个地点的总收入,总获救人数 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Embarked",values=["Fare","Survived"],aggfunc=np.sum)print(res)
结果 :
Fare Survived
Embarked
C 10072.296293
Q 1022.254330
S 17439.3988217
每个地点的人的生还率 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 分组函数 ( pivot_table ) 分组条件,计算字段,计算规则
res = data.pivot_table(index="Embarked",values=["Fare","Survived"],aggfunc=np.mean)print(res)
结果 :
Fare Survived
Embarked
C 59.9541440.553571
Q 13.2760300.389610
S 27.0798120.336957
8 ,去除空值 :
数据共几行 : 891
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")
n1 = data.shape[0]print(n1)
结果 : 891
每一行有多少个数值,不算空值 : 都不同
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")
n1 = data.count()print(n1)
结果 :
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
如果有空值 : 删列
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 去除空值
res = data.dropna(axis=1)print(data.shape)print(res.shape)
结果 :
(891,12)(891,9)
如果有空值 : 删行
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 去除空值
res = data.dropna(axis=0)print(data.shape)print(res.shape)
结果 :
(891,12)(183,12)
指定列,删除行 : 如果这个字段是 Nan ,就删除这一行 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 去除空值,检查年龄和性别,如果有空,就删除数据
res = data.dropna(axis=0,subset=["Age","Sex"])print(data.shape)print(res.shape)
结果 :
(891,12)(714,12)
9 ,取元素 : 行号 + 列号
通过行列号取值 :
if __name__ =='__main__':# 读数据
data = pd.read_csv("titanic_train.csv")# 取值 :print(data.head(5))
yuan = data.loc[0,'Pclass']print(yuan)
结果 :
Backend TkAgg is interactive backend. Turning interactive mode on.
PassengerId Survived Pclass ... Fare Cabin Embarked
0103...7.2500 NaN S
1211...71.2833 C85 C
2313...7.9250 NaN S
3411...53.1000 C123 S
4503...8.0500 NaN S
[5 rows x 12 columns]3
























 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









