






Windows系统安装虚拟机
这里安装虚拟机使用VMvare虚拟机,下载地址https://www.cr173.com/soft/32940.htm,下载好以后安装过程比较简单,按照提示进行就可以。安装好以后第一次运行需要输入产品密钥,可以百度获取。
VMvare安装Linux系统
这里Linux系统我们CentOS 6.5.下载地址:
百度网盘下载:http://pan.baidu.com/s/1dD2DSLb
BT种子下载:链接:https://pan.baidu.com/s/1et-ndPJ0UrMYl4P509tUAA提取码:trs2
下载好以后,使用VMvare安装CentOS 6.5 参考以下两篇文章:
参考文章1
参考文章2
在安装过程中,使用了Xshell工具来远程配置虚拟机,Xshell工具下载地址:Xshell6下载
Hadoop集群部署安装
Linux服务器配置
可以通过远程终端Xshell工具连接上虚拟机远程控制
1.准备操作系统环境
配置主机名:修改以下配置文件
vi /etc/sysconfig/network
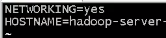
这里HOSTNAME的值就是主机名,我这里修改为hadoop_server
配置主机名和IP地址的映射,执行以下命令;
vi /etc/hosts
进入文件,添加IP地址和主机名

关闭服务器图形界面启动:
vi /etc/inittab
然后将最下面一行启动级别改为3,

关闭防火墙:
service iptables stop
禁止防火墙重启:
chkconfig iptables off
准备Java环境
1.安装jdk
准备一个jdk安装包,使用Xshell工具上传到Linux服务器。
上传方法:
a.连接Linux主机。
b.输入 rz 命令,查看是否已经安装lrzse,如果没有,则使用
yum -y install lrzsz 命令进行安装。
c.安装成功以后,输入rpm命令确认是否正确安装。

d.使用rz -y 命令进行文件上传,此时会弹出上传文件的选择框。
e.传输完成以后,查看ls命令就可以看到文件上传到了当前目录下。
2.jdk安装包上传好以后,新建一个解压文件夹apps:
mkdir /usr/local/apps
把压缩包解压到apps文件夹:
tar -zxvf jdk-xxx-xxx.tar.gz -C /usr/local/apps/
3.配置环境变量
解压好以后,开始配置环境变量:
vi /etc/profile
进入文件以后,在末尾添加:
export JAVA_HOME=/usr/local/apps/jdkxxxx //jdk安装目录
export PATH=$PATH:$JAVA_HOME/bin
添加好以后保存,执行以下命令使其生效:
source /etc/profile
检验环境变量是否配置成功:
echo $JAVA_HOME
查看输出值是否正确。
安装hadoop
1.上传hadoop安装包,并解压:
tar -zxvf hadoop-xxx-xxx.tar.gz -C /usr/local/apps/
2.修改配置文件:
进入到hadoop文件下 /etc/hadoop/目录下:
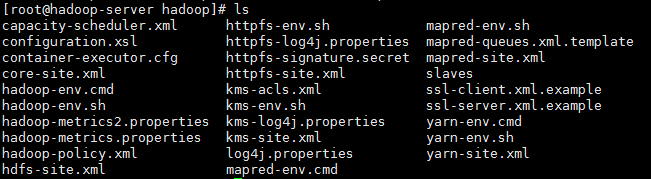
开始修改配置文件:
a.
vi hadoop-env.sh
修改JAVA_HOME路径:

b.
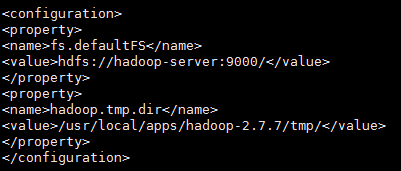
vi core-site.xml
增加以下变量;
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-server:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/apps/hadoop-2.7.7/tmp/</value>
</property>
如图:
c.
vi hdfs.site.xml
增加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
d.修改mapred-site.xml.template文件名,去掉.template
mv mapred-site.xml.template mapred-site.xml
然后进去该文件,添加以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
e.
vi yarn-site.xml
添加以下内容:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-server</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
最后配置从节点:
vi salves
将文件中的localhost修改为主机名。
启动hadoop
1.格式化namenode
进入到hadoop文件夹中的bin目录下,执行以下操作:
./hadoop namenode -format
2.手动启动hadoop
进入到hadoop文件夹中的sbin目录下,执行以下命令:
./hadoop-daemon.sh start namenode
启动以后,使用 jps 命令查看服务是否已经启动。
再启动DataNode服务进程:
./hadoop-daemon.sh start datanode
再启动 secondarynamenode 服务进程
./hadoop-daemon.sh start secondarynamenode
可以使用 netstat -nltp 命令查看监听的端口
以上启动了hdfs的服务进程,接下来启动yarn的服务进程;
./yarn-daemon.sh start resourcemanager
./yarn-daemon.sh start nodemanager
3.使用脚本启动hadoop
进入到hadoop文件夹中的sbin目录下,执行以下命令:
启动hdfs服务:
./start-dfs.sh
启动yarn服务:
./start-yarn.sh
直接全部启动:
./start-all.sh
4.设置免密登录
在上步脚本启动服务进程的时候,发现需要不停的输入密码,会很麻烦,需要设置一下免密登录。
在登录方生成秘钥对:
ssh-keygen
接下来几步默认回车
生成秘钥对以后,把公钥拷贝到目标主机:
ssh-copy-id hadoop-server
然后使用 ssh hadoop-server 登录目标主机就不再输密码。
5.停止服务
./stop-dfs.sh
全部停止:
./stop-all.sh















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









