







在上一篇文章中有讲到Linux安装JDK的过程,这篇文章讲述的是Linux安装Hadoop的过程。
一、Hadoop的下载与解压缩
我用的Hadoop是3.3.4版本,亲测有效。
链接:https://pan.baidu.com/s/1bSruEEkUaRZDz43mj0xMwg?pwd=scez
- 提取出来后,可以放在U盘里,从U盘里导入到虚拟机中。(导入的过程中,需要注意一个问题:如果自己的U盘是3.0接口的话,需要把虚拟机的USB兼容性改变成3.0或者3.1的,把“显示所有USB输入设备”勾选上,再重新启动虚拟机即可。)这个问题在上一篇的“Linux安装JDK的过程”中有说到过,如果想了解,可以去看一下。
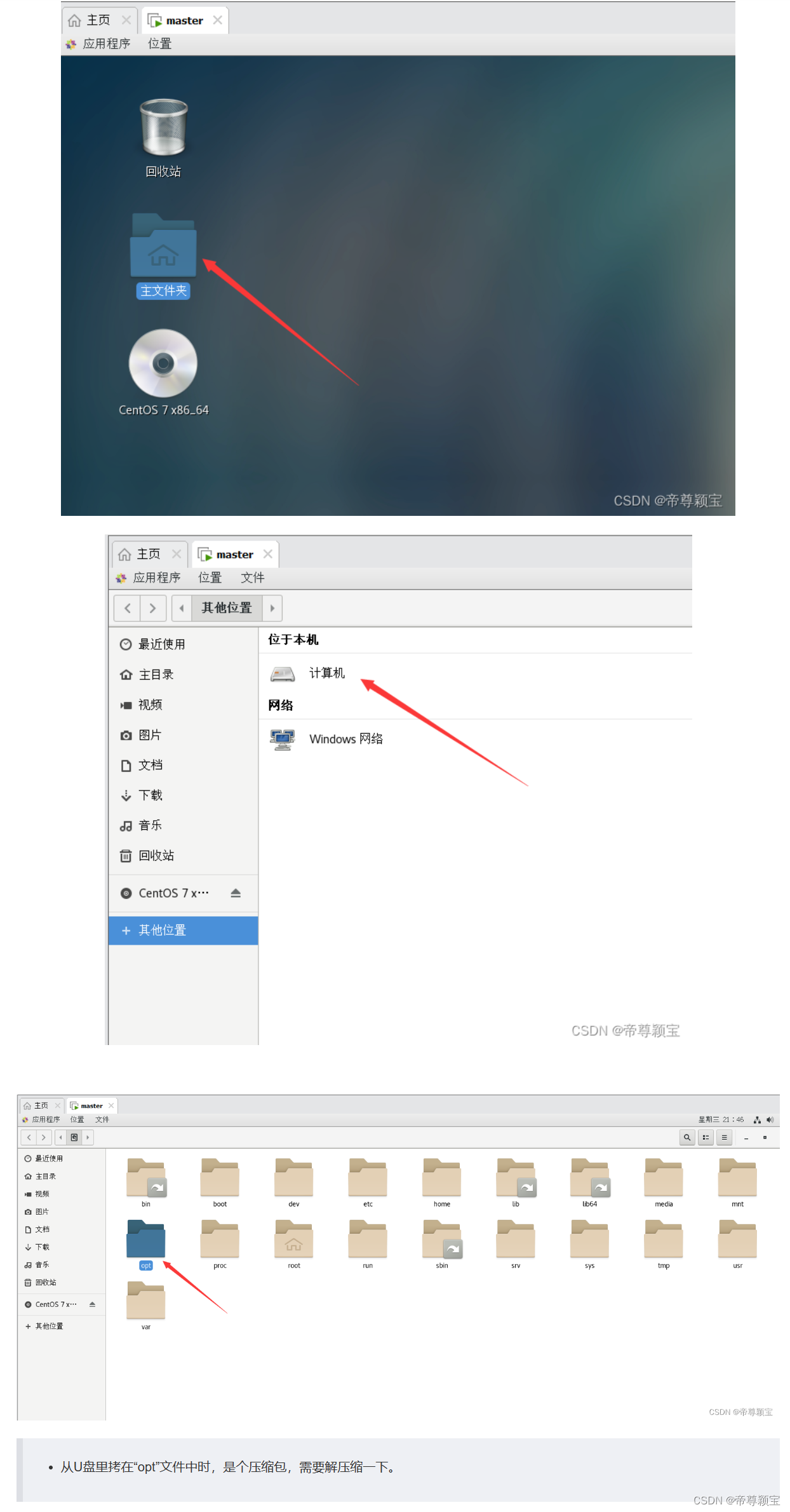
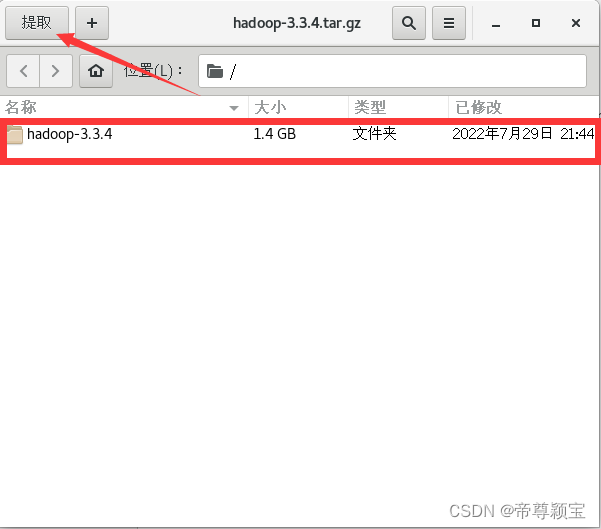
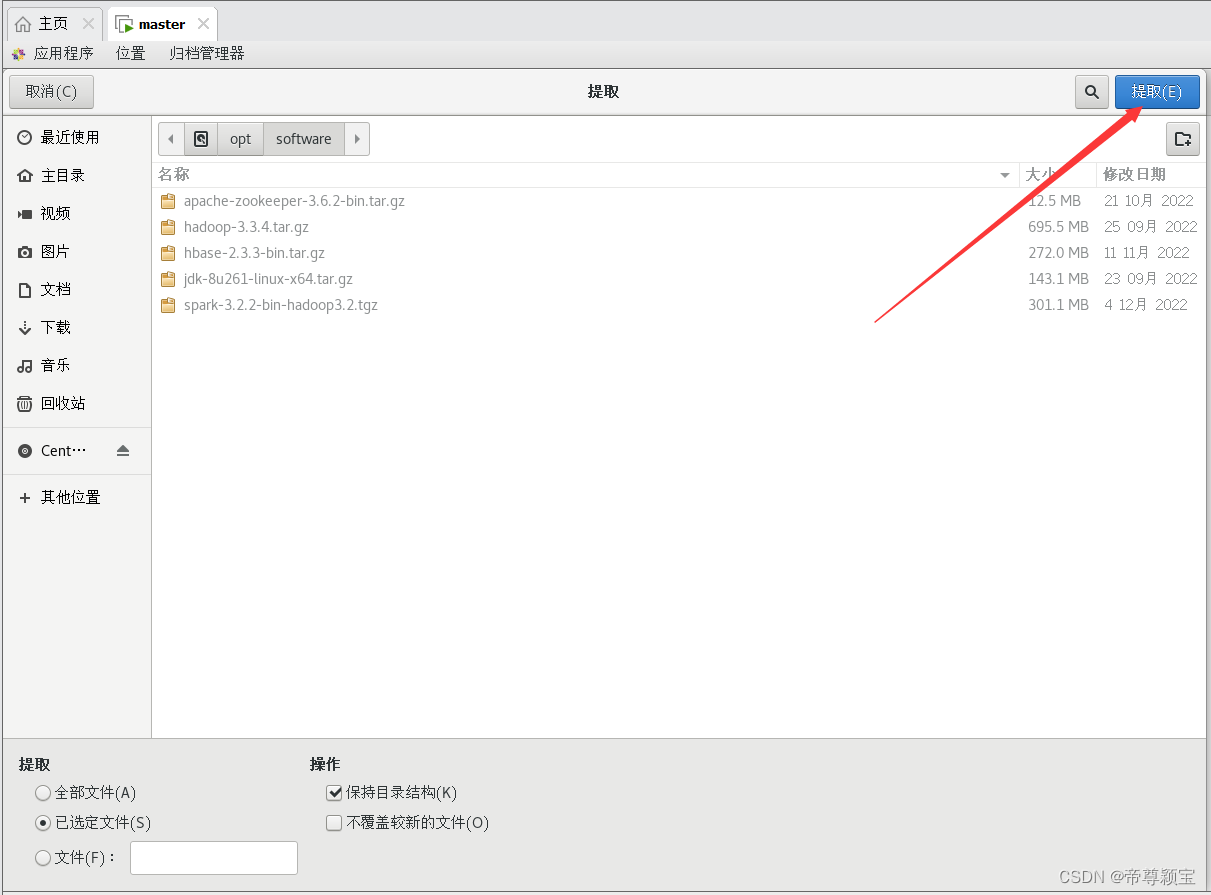
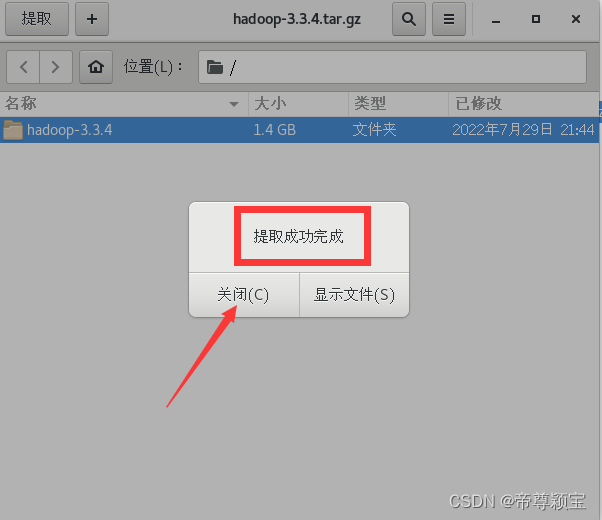
- 解压缩Hadoop文件至“opt”文件夹中:


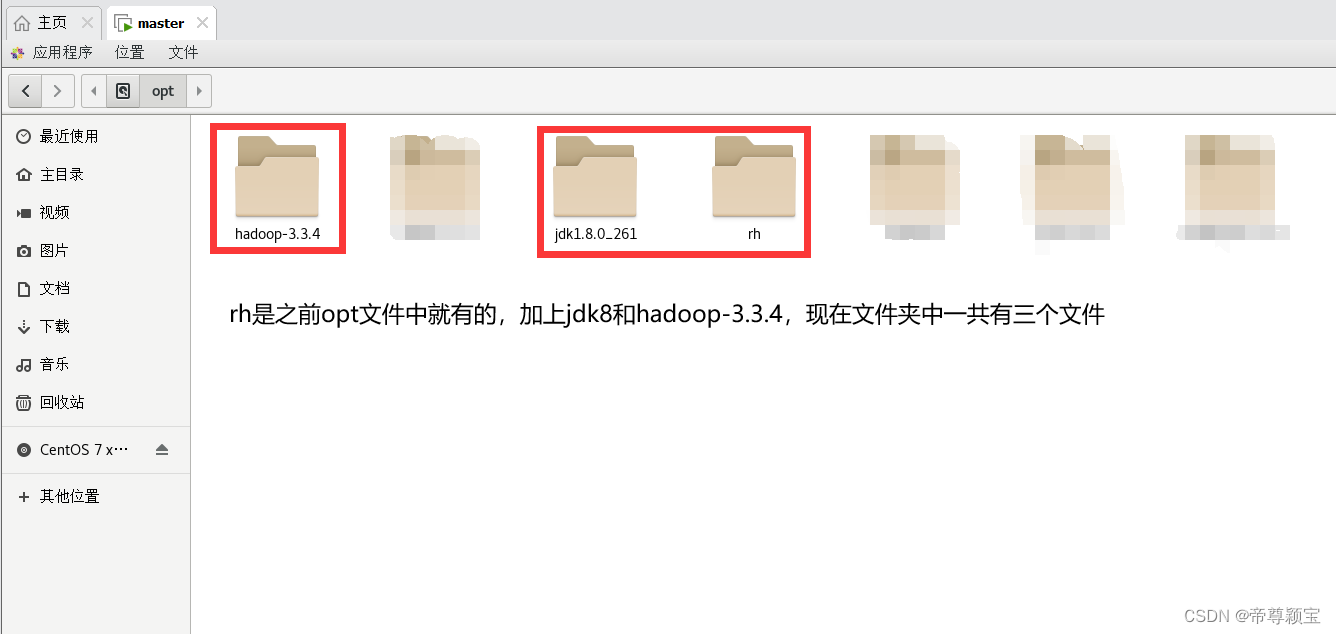
二、修改Hadoop配置文件
- 修改bashrc文件:“etc——bashrc”
#hadoop_config export HADOOP_HOME=/opt/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin
修改完成后,记得保存关闭,在终端敲入生效命令:source /etc/bashrc。
注:下面修改的6个文件的文件路径是:opt/hadoop-3.3.4/etc/hadoop。
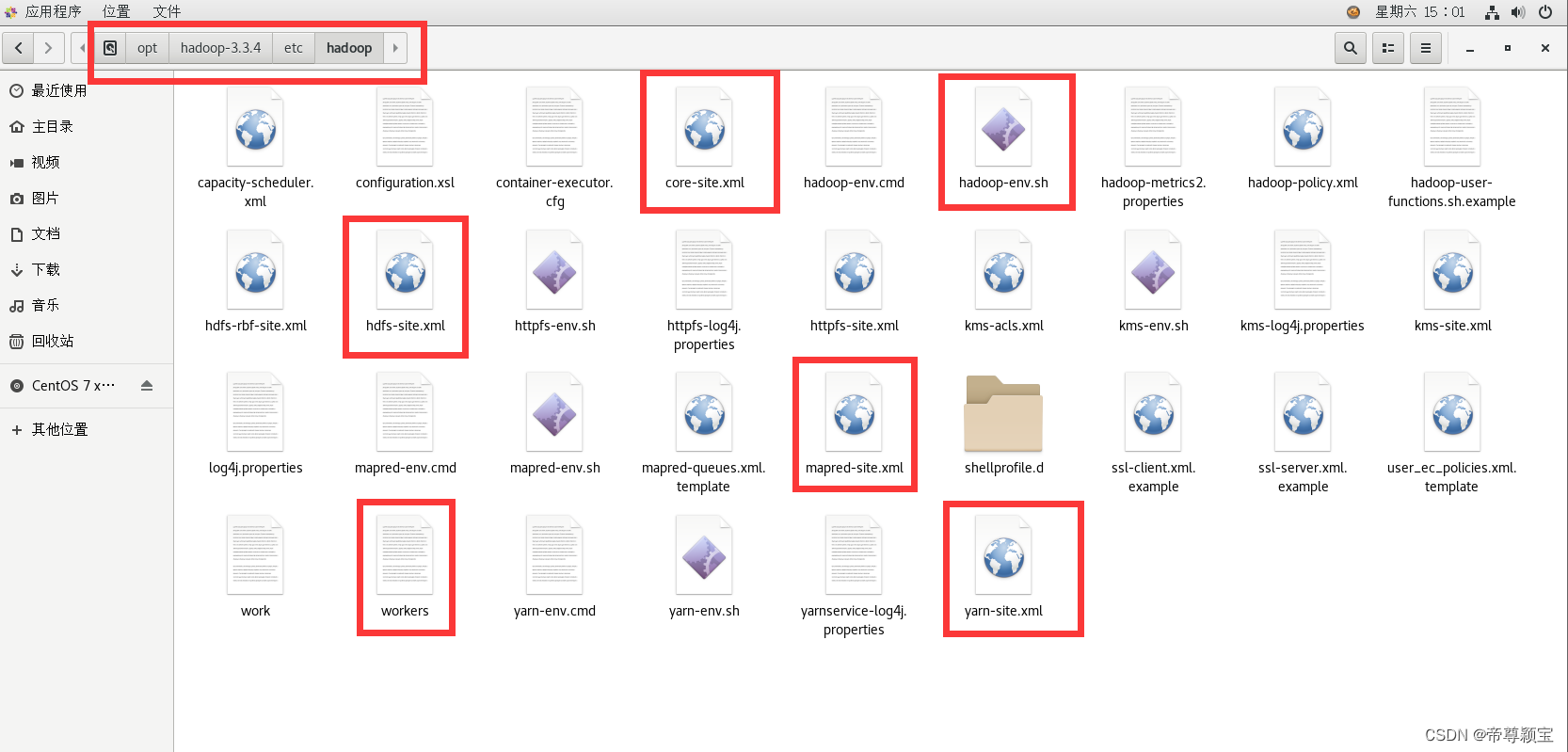
- 修改hadoop-env.sh文件:
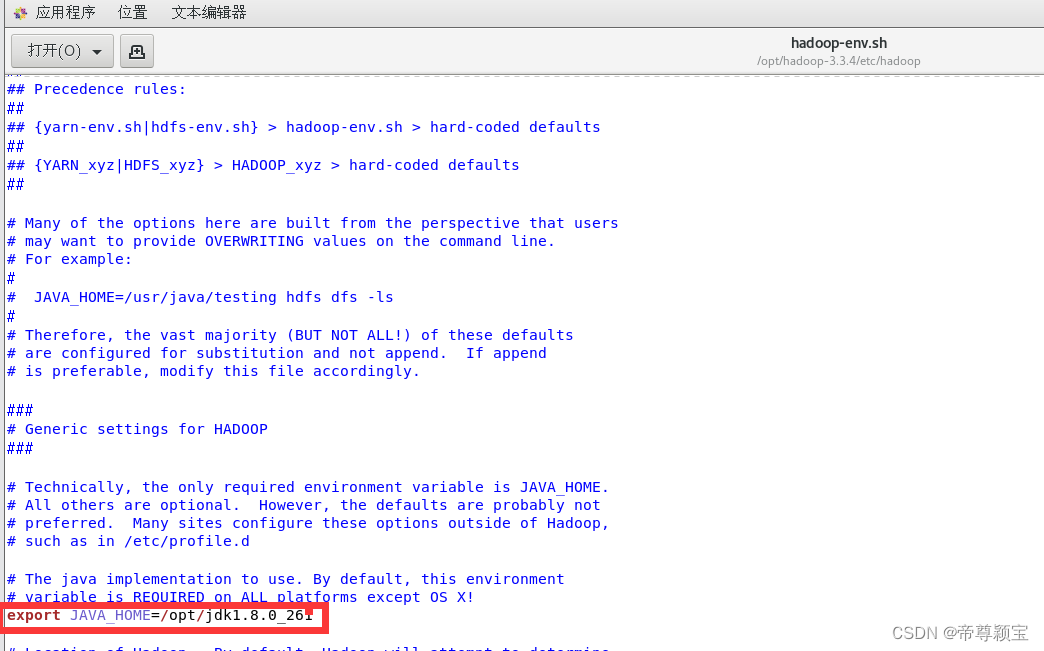
export JAVA_HOME=/opt/jdk1.8.0_261export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root" export HADOOP_HOME=/opt/hadoop-3.3.4 export PATH=$PATH:/opt/hadoop-3.3.4/bin export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native" export HADOOP_PID_DIR=/opt/hadoop-3.3.4/pids
第一行的代码片段是“#export JAVA_HOME=”的修改内容;
第二行的代码片段是在该文件的最后添加的内容。
修改完成后,记得保存关闭。
- 修改core-site.xml文件:使用“文本编辑器”打开,如果右击没有出现“文本编辑器”,则可以选择“使用其他程序打开”,打开之后,选“文本编辑器”。
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可 namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data --> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-3.3.4/hadoopdata</value> </property> </configuration>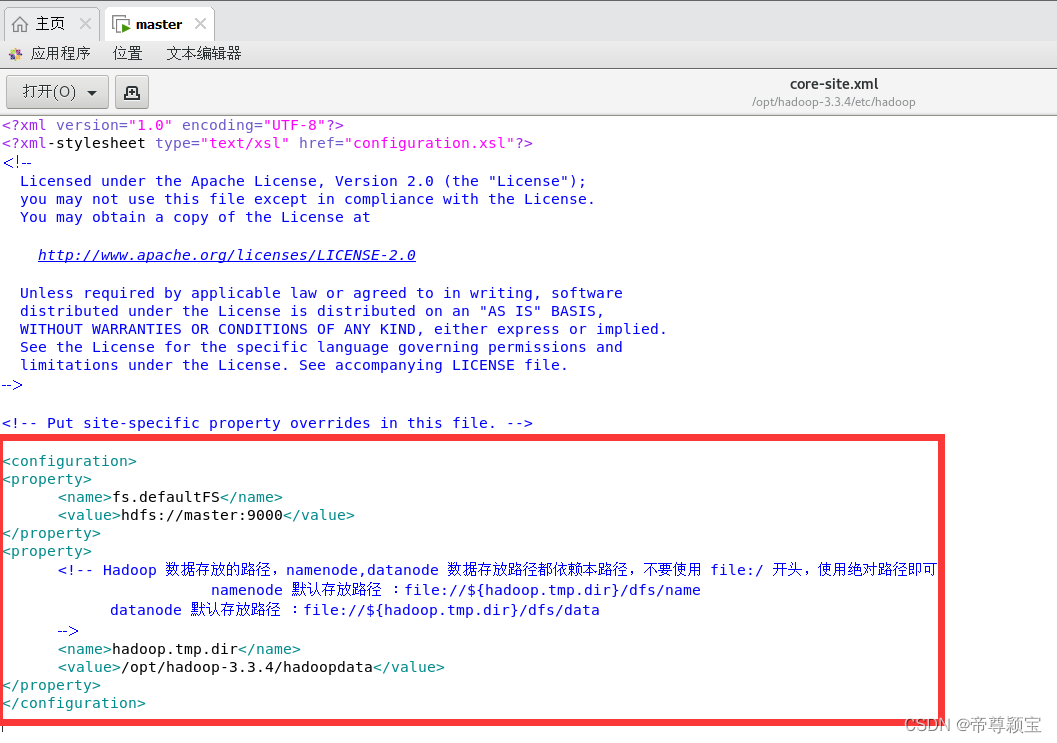
修改完成后,记得保存关闭。
- 在“opt/hadoop-3.3.4”文件夹创建一个“hadoopdata”文件夹:
- 修改hdfs-site.xml文件:使用“文本编辑器打开”,填入以下内容。
<configuration> <property> <name>dfs.namenode.http-address</name> <!-- Master为当前机器名或者IP地址 --> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <!-- 以下为存放节点命名的路径 --> <value>file:/opt/hadoop-3.3.4/hadoopdata/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <!-- 以下为存放数据命名的路径 --> <value>file:/opt/hadoop-3.3.4/hadoopdata/dfs/data</value> </property> <property> <name>dfs.replication</name> <!-- 备份次数,因为有2台DataNode--> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <!-- Web HDFS--> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> </configuration>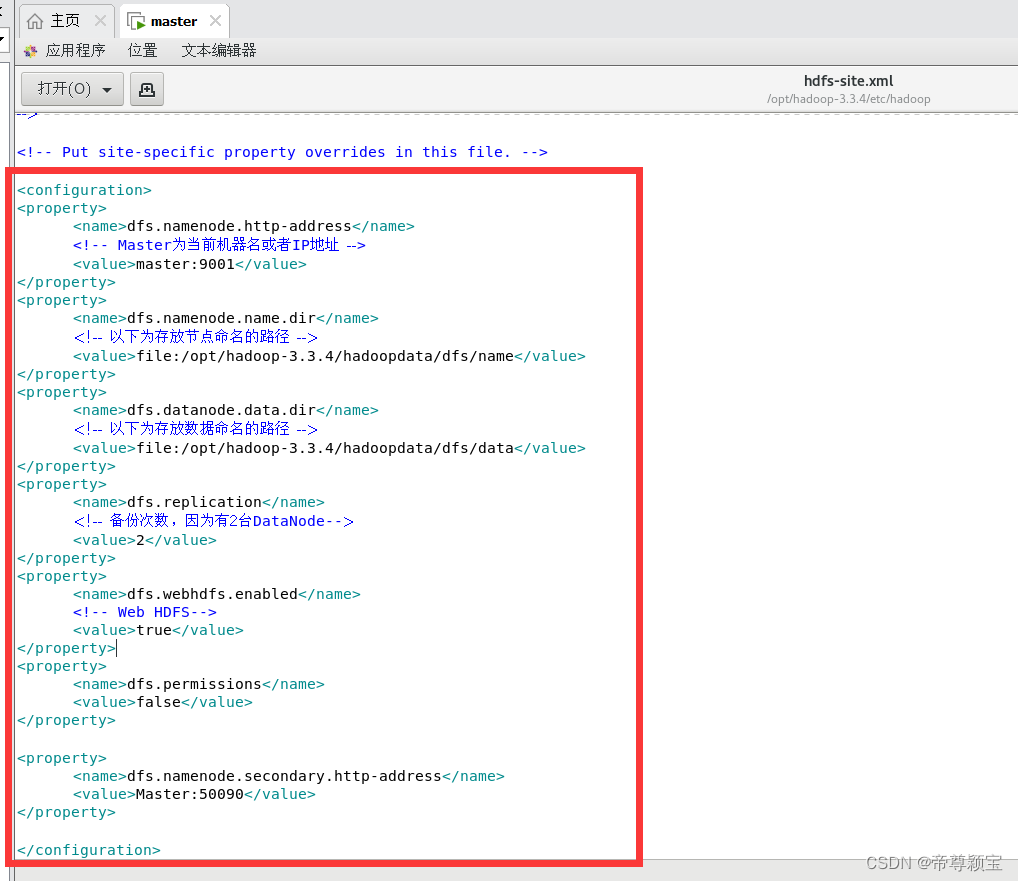
修改完成后,记得保存关闭。
- 修改mapred-site.xml文件:使用“文本编辑器打开”
<configuration> <property> <name>mapreduce.framework.name</name> <!-- MapReduce Framework --> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <!-- MapReduce JobHistory, 当前计算机的IP --> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <!-- MapReduce Web App JobHistory, 当前计算机的IP --> <value>master:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value> </property> </configuration>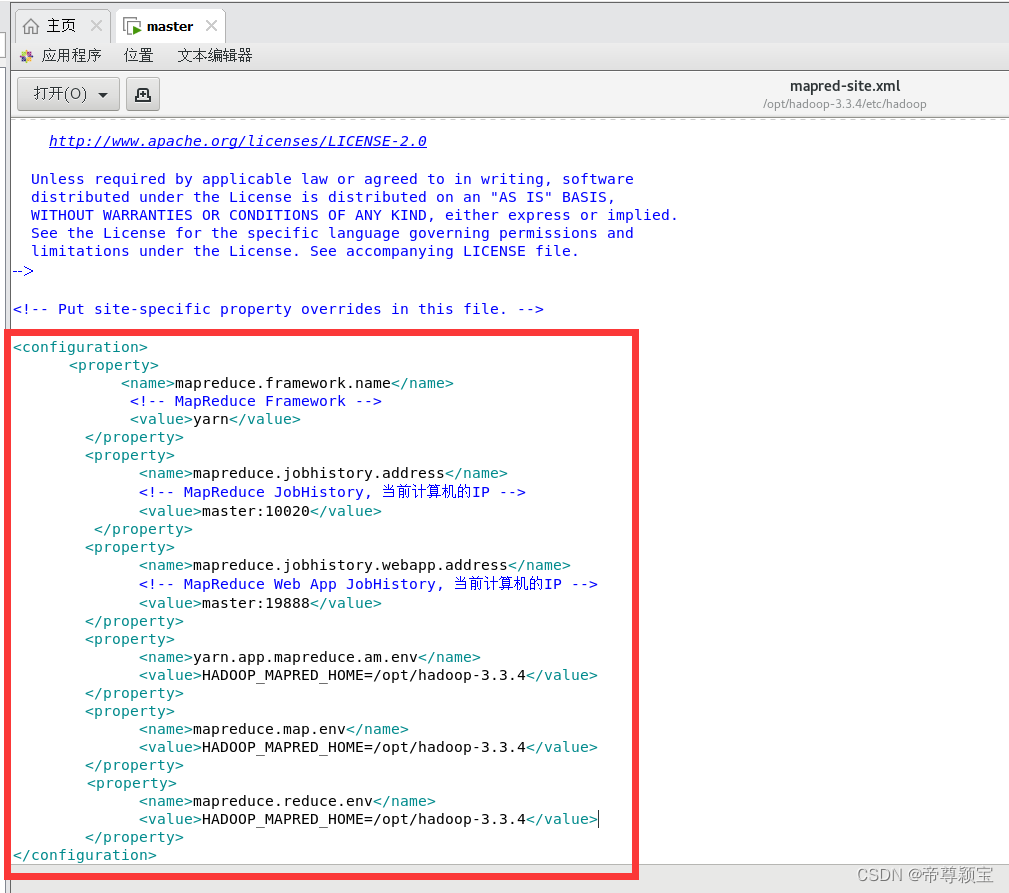
修改完成后,记得保存关闭。
- 修改yarn-site.xml文件:使用“文本编辑器打开”
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <!-- Master为当前机器名或者ip号 --> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <!-- Node Manager辅助服务 --> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <!-- Node Manager辅助服务类 --> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <!-- CPU个数,需要根据当前计算机的CPU设置--> <value>1</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <!-- Resource Manager管理地址 --> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <!-- Resource Manager Web地址 --> <value>master:8088</value> </property> </configuration>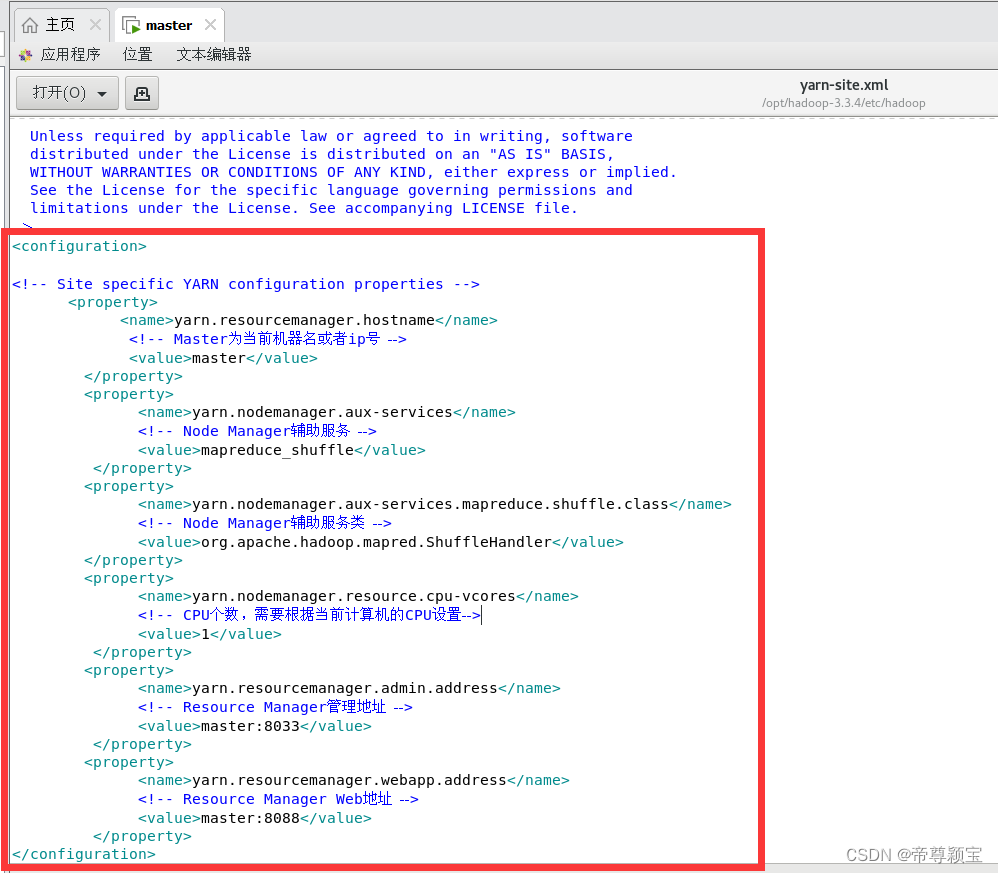
修改完成后,记得保存关闭。
- 修改workers文件:双击打开后,填入以下内容,
master slave0 slave1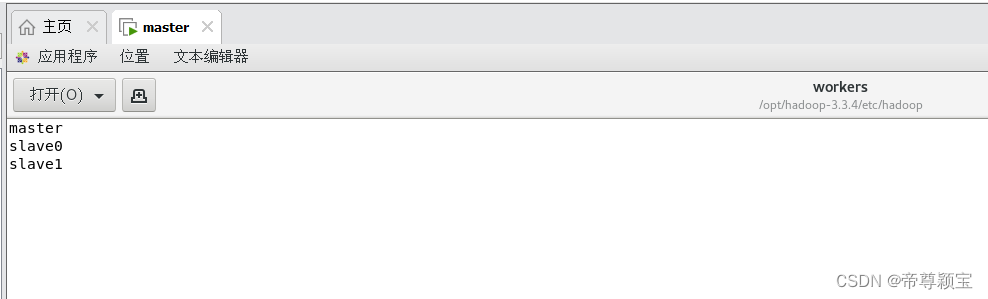
修改完成后,记得保存关闭。
三、master远程发送文件给slave0和slave1,并对其中的bashrc文件进行修改
- 进入opt文件:cd /opt

- 使用远程发送命令把jdk8与hadoop-3.3.4发送到slave0与slave1机器上:

![]()
![]()
![]()
- master远程控制slave0(slave1),对其bashrc文件进行修改并生效:
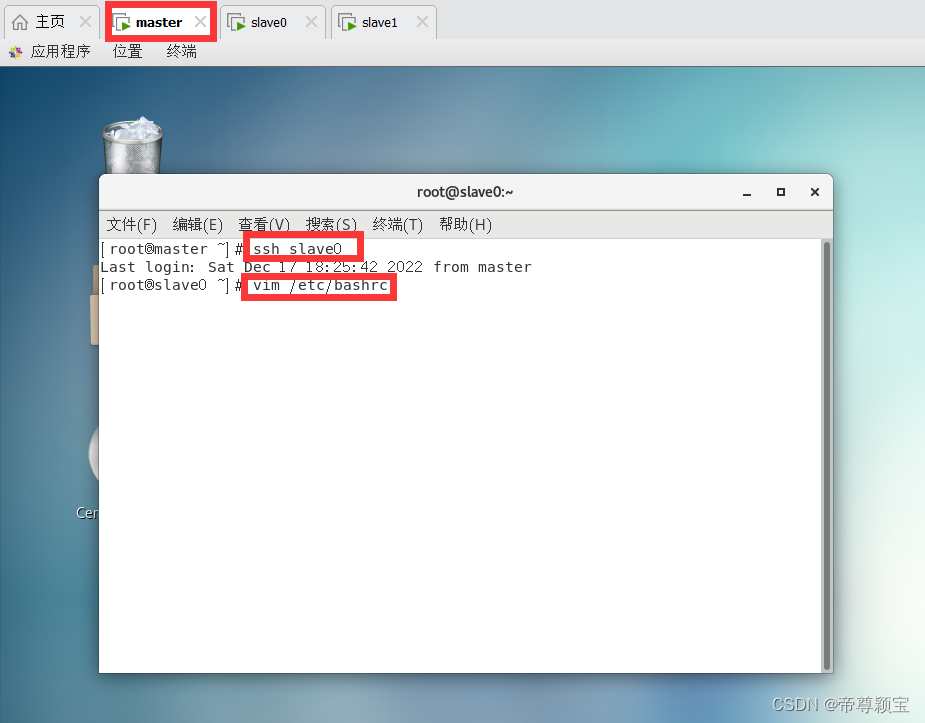
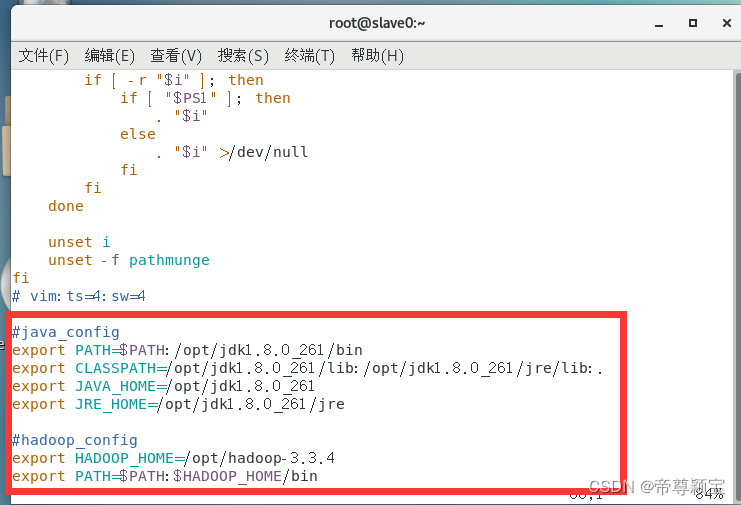
退出vim界面的命令是:“: wq”
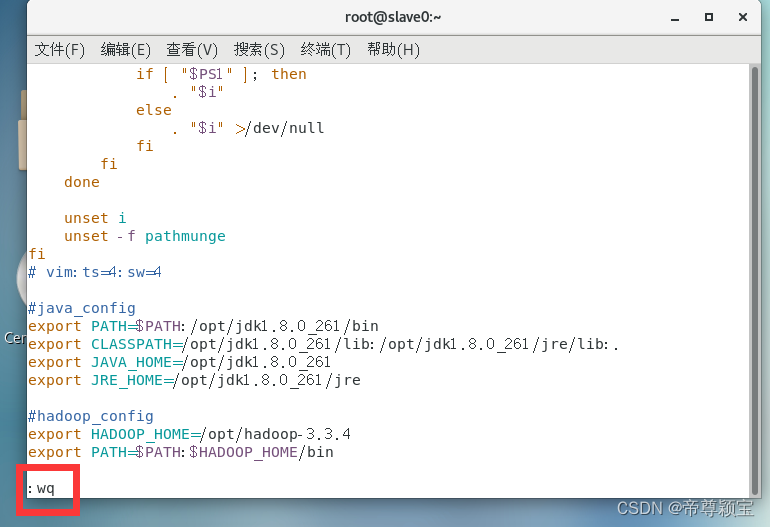
这是master对slave0的远程操控,master对slave1也是同样的方法。
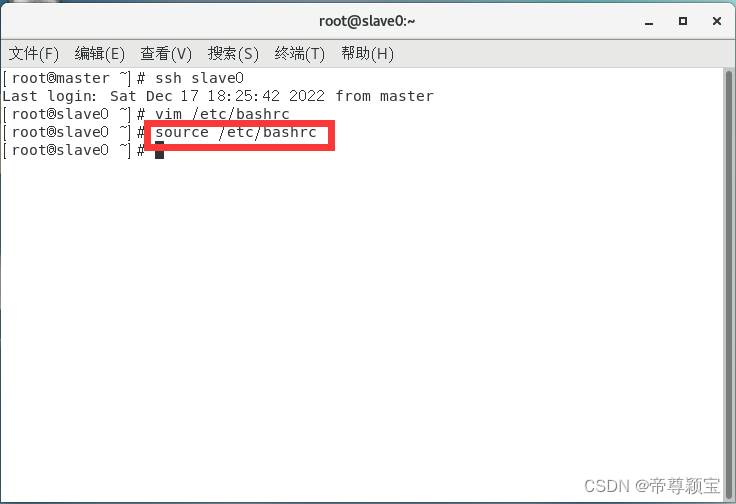
最后要生效bashrc文件:
生效完成后,在终端敲入“exit”,退出slave0(slave1)。
- 以上步骤结束后,保存并关闭所有文件,对Hadoop进行格式化:
hdfs namenode -format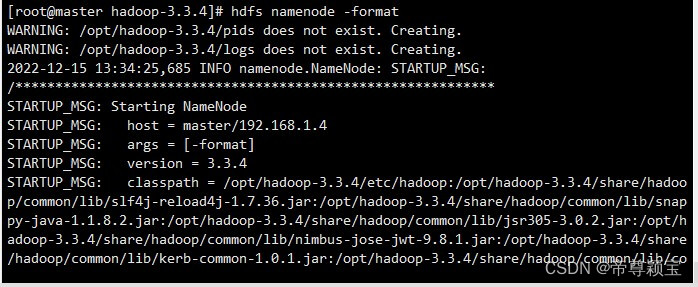
- 格式化完成后,就可以启动集群了:
使用“cd”命令进入到sbin文件夹中。
cd /opt/hadoop-3.3.4/sbin/集群启动命令:
./start-all.sh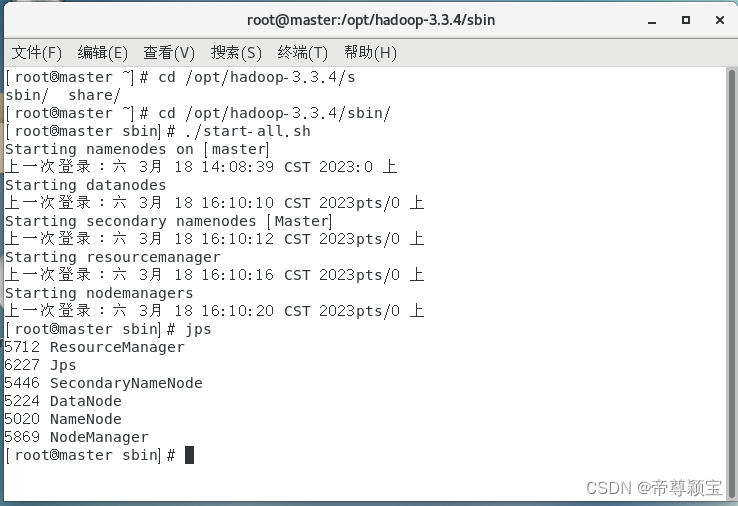
- 第一次使用启动集群,会有6个warning出现,可以不用管(它们是说有几个文件不存在,但是这几个文件,系统会自动创建)。
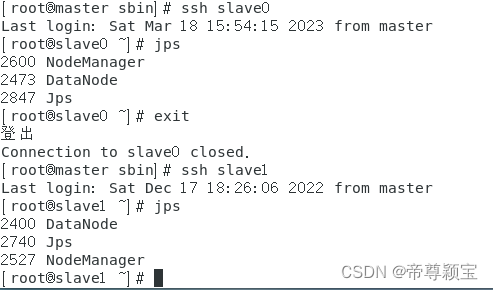
- 集群启动成功后:master会出现6个结果(namenode,jps,resourcemanager,secondarynamenode,datanode,nodemanager);slave0与slave1会出现3个结果(datanode,jps,nodemanager)。
- 关闭集群:前提是在sbin目录下
./stop-all.sh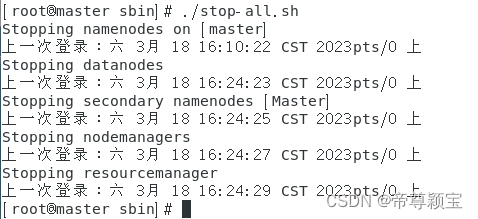















 3206
3206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









