






提示:学习笔记 欢迎指点
一、为什么要使用分布式文件系统呢?
单机系统
项目初建时期由于时间资源等各种原因,通常就直接在项目目录下建立静态文件夹,用于用户存放项目中的文件资源。如果按不同类型再细分,可以在项目目录下再建立不同的子目录来区分。例如:resources\static\file、resources\static\img等。
优点:这样做比较便利,项目直接引用就行,实现起来也简单,无需任何复杂技术,保存数据库记录和访问起来也很方便。
缺点:如果只是后台系统的使用一般也不会有什么问题,但是作为一个前端网站使用的话就会存在弊端。一方面,文件和代码耦合在一起,文件越多存放越混乱;另一方面,如果流量比较大,静态文件访问会占据一定的资源,影响正常业务进行,不利于网站快速发展。
独立文件服务器
随着公司业务不断发展,将代码和文件放在同一服务器的弊端就会越来越明显。为了解决上面的问题引入独立图片服务器,工作流程如下:项目上传文件时,首先通过ftp或者ssh将文件上传到图片服务器的某个目录下,再通过ngnix或者apache来访问此目录下的文件,返回一个独立域名的图片URL地址,前端使用文件时就通过这个URL地址读取。
优点:图片访问是很消耗服务器资源的(因为会涉及到操作系统的上下文切换和磁盘I/O操作),分离出来后,Web/App服务器可以更专注发挥动态处理的能力;独立存储,更方便做扩容、容灾和数据迁移;方便做图片访问请求的负载均衡,方便应用各种缓存策略(HTTP Header、Proxy Cache等),也更加方便迁移到CDN。
缺点:单机存在性能瓶颈,容灾、垂直扩展性稍差。
分布式文件系统
通过独立文件服务器可以解决一些问题,如果某天存储文件的那台服务突然down了怎么办?可能你会说,定时将文件系统备份,这台down机的时候,迅速切换到另一台就OK了,但是这样处理需要人工来干预。另外,当存储的文件超过100T的时候怎么办?单台服务器的性能问题?这个时候我们就应该考虑分布式文件系统了。
业务继续发展,单台服务器存储和响应也很快到达了瓶颈,新的业务需要文件访问具有高响应性、高可用性来支持系统。分布式文件系统,一般分为三块内容来配合,服务的存储、访问的仲裁系统,文件存储系统,文件的容灾系统来构成,仲裁系统相当于文件服务器的大脑,根据一定的算法来决定文件存储的位置,文件存储系统负责保存文件,容灾系统负责文件系统和自己的相互备份。
优点:扩展能力: 毫无疑问,扩展能力是一个分布式文件系统最重要的特点;高可用性: 在分布式文件系统中,高可用性包含两层,一是整个文件系统的可用性,二是数据的完整和一致性;弹性存储: 可以根据业务需要灵活地增加或缩减数据存储以及增删存储池中的资源,而不需要中断系统运行
缺点:系统复杂度稍高,需要更多服务器。
毫无疑问FastDFS就属于我们上面介绍的分布式文件系统。
二、FastDFS 简介
概念
FastDFS 是一个轻量级、开源的、高性能、分布式的文件系统。它的主要功能包括:
- 文件存储
- 文件同步
- 文件访问(文件上传和文件下载)
- 解决了大容量存储和负载均衡的问题
FastDFS 非常适合以文件为载体的在线服务,如相册网站、视频网站等等。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制。并注重高可用、高性能等指标。使用FastDFS很容易搭建一套高性能的文件服务器集群,提供文件上传、下载等服务。
FastDFS是一种轻量级对象存储解决方案。如果您需要一个用于数据库、K8s和虚拟机(如KVM)的通用分布式文件系统,您可以了解FastCFS,它可以实现强大的数据一致性和高性能。
角色
FastDFS服务端有三个角色:跟踪服务器(tracker server)、存储服务器(storage server)和客户端(client)。
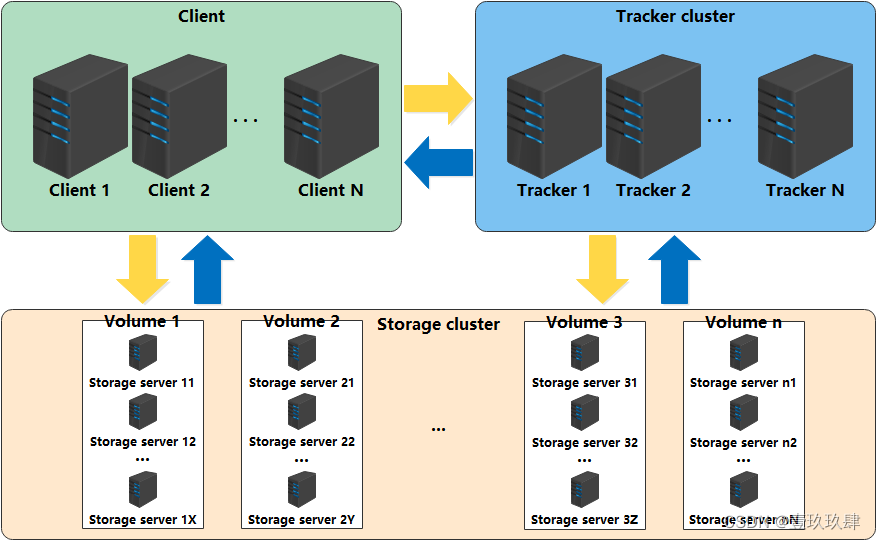
tracker server:跟踪服务器,主要做调度工作,起负载均衡的作用。在内存中记录集群中所有存储组和存储服务器的状态信息,是客户端和数据服务器交互的枢纽。相比GFS中的master更为精简,不记录文件索引信息,占用的内存量很少。
Tracker是FastDFS的协调者,负责管理所有的storage server和group,每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。
Tracker需要管理的元信息很少,会全部存储在内存中;另外tracker上的元信息都是由storage汇报的信息生成的,本身不需要持久化任何数据,这样使得tracker非常容易扩展,直接增加tracker机器即可扩展为tracker cluster来服务,cluster里每个tracker之间是完全对等的,所有的tracker都接受stroage的心跳信息,生成元数据信息来提供读写服务。
storage server:存储服务器(又称:存储节点或数据服务器),文件和文件属性(meta data)都保存到存储服务器上。Storage server直接利用OS的文件系统调用管理文件。
Storage server(后简称storage)以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份,存储空间以group内容量最小的storage为准,所以建议group内的多个storage尽量配置相同,以免造成存储空间的浪费。
以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(group内storage server数量即为该group的副本数),比如将不同应用数据存到不同的group就能隔离应用数据,同时还可根据应用的访问特性来将应用分配到不同的group来做负载均衡;缺点是group的容量受单机存储容量的限制,同时当group内有机器坏掉时,数据恢复只能依赖group内地其他机器,使得恢复时间会很长。
group内每个storage的存储依赖于本地文件系统,storage可配置多个数据存储目录,比如有10块磁盘,分别挂载在/data/disk1-/data/disk10,则可将这10个目录都配置为storage的数据存储目录。
storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
client:客户端,作为业务请求的发起方,通过专有接口,使用TCP/IP协议与跟踪器服务器或存储节点进行数据交互。FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
另外两个概念:
group:组, 也可称为卷。 同组内服务器上的文件是完全相同的 ,同一组内的storage server之间是对等的, 文件上传、 删除等操作可以在任意一台storage server上进行 。
meta data:文件相关属性,键值对( Key Value Pair) 方式,如:width=1024,heigth=768 。
Tracker相当于FastDFS的大脑,不论是上传还是下载都是通过tracker来分配资源;客户端一般可以使用ngnix等静态服务器来调用或者做一部分的缓存;存储服务器内部分为卷(或者叫做组),卷于卷之间是平行的关系,可以根据资源的使用情况随时增加,卷内服务器文件相互同步备份,以达到容灾的目的。
特点
- 分组存储,简单灵活;
- 对等结构,不存在单点;
- 文件 ID 由 FastDFS 生成,作为文件访问凭证。FastDFS 不需要传统的name server 或 meta server;
- 大、中、小文件均可以很好支持,可以存储海量小文件;
- 一台 storage支持多块磁盘,支持单盘数据恢复;
- 提供了 nginx 扩展模块,可以和 nginx 无缝衔接;
- 支持多线程方式上传和下载文件,支持断点续传;
- 存储服务器上可以保存文件附加属性。
三、上传机制、下载机制
Client为使用FastDFS服务的调用方,并且也是一台服务器,它对tracker和storage的调用均为服务器间的调用。存储服务器采用分组方式,同组内的存储服务器上的文件完全相同。不同组的storage server之间不会相互通信。由storage server主动向tracker server报告状态信息,tracker server之间不会相互通信。
上传交互过程
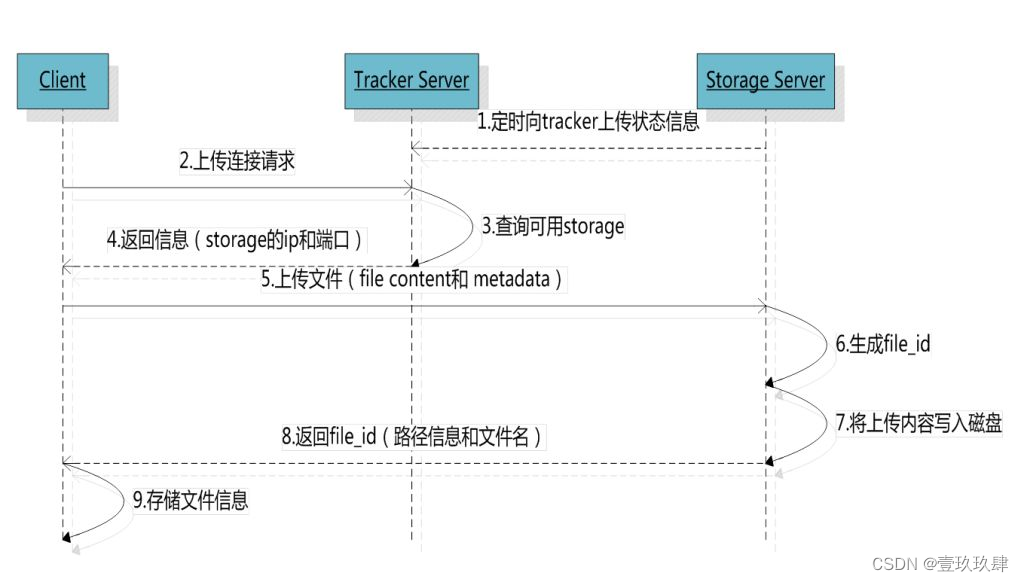
- client询问tracker上传到的storage,不需要附加参数;
- tracker返回一台可用的storage;
- client直接和storage通讯完成文件上传。
客户端上传文件后,存储服务器将 文件ID 返回给客户端,此文件ID用于以后访问该文件的索引信息。
文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
组名:文件上传后所在的storage组名称,在文件上传成功后由storage服务器返回,需要客户端自行保存。
虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path对应。如果配置了store_path0,则虚拟路径是M00,如果配置了store_path1,则虚拟路径是M01,以此类推。
数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
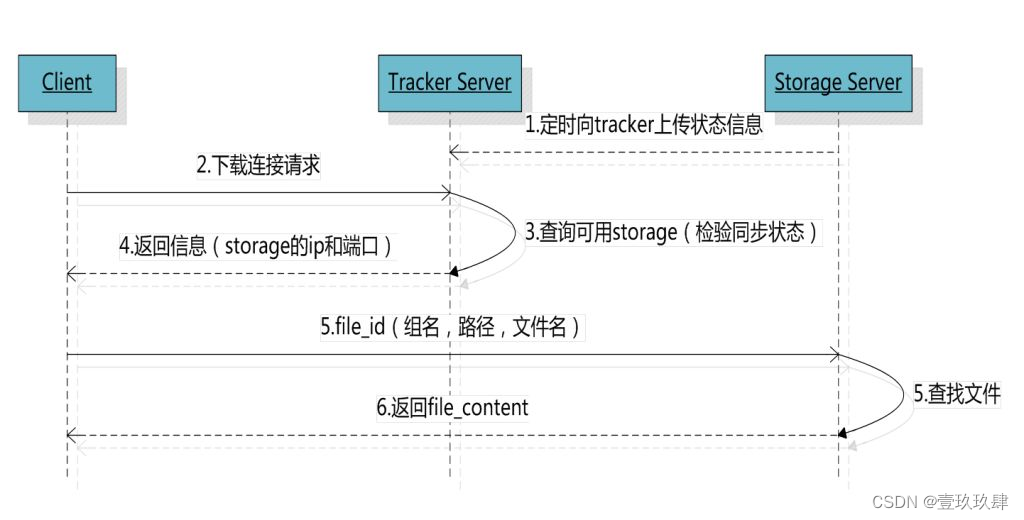
下载交换过程
- client询问tracker下载文件的storage,参数为文件标识(卷名和文件名);
- tracker返回一台可用的storage;
- client直接和storage通讯完成文件下载。
tracker 通过组名/卷名能够很快的定位到客户端需要访问的存储服务器组,并选择合适的存储服务器提供客户端访问。
storage 根据“文件存储虚拟磁盘路径”和“数据文件两级目录”可以很快定位到文件所在目录,并根据文件名找到客户端需要访问的文件。
文件的标识由两部分组成:卷名和文件名,二者缺一不可。
参考
[1]: https://zhuanlan.zhihu.com/p/32798888?utm_source=wechat_session















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









