







一、任务
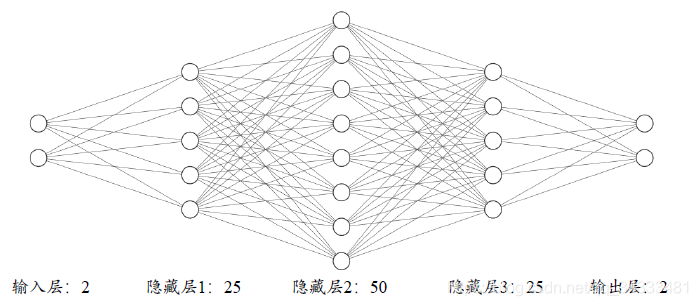
实现一个4 层的全连接网络实现二分类任务,网络输入节点数为2,隐藏层的节点数设计为:25,50,25,输出层2 个节点,分别表示属于类别1 的概率和类别2 的概率,如图所示。我们并没有采用Softmax 函数将网络输出概率值之和进行约束,而是直接利用均方差误差函数计算与One-hot 编码的真实标签之间的误差,所有的网络激活函数全部采用Sigmoid 函数,这些设计都是为了能直接利用梯度推导公式。
二、数据集
通过scikit-learn 库提供的便捷工具生成2000 个线性不可分的2 分类数据集,数据的特征长度为2,采样出的数据分布如图 所示,所有的红色点为一类,所有的蓝色点为一类,可以看到数据的分布呈月牙状,并且是是线性不可分的,无法用线性网络获得较好效果。为了测试网络的性能,按照7: 3比例切分训练集和测试集,其中2000 ∗ 0 3 =600个样本点用于测试,不参与训练,剩下的1400 个点用于网络的训练。
import matplotlib.pyplot as plt
import seaborn as sns #要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
N_SAMPLES = 2000 # 采样点数
TEST_SIZE = 0.3 # 测试数量比率
# 利用工具函数直接生成数据集
X, y = make_moons(n_samples = N_SAMPLES, noise=0.2, random_state=100)
# 将2000 个点按着7:3 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=TEST_SIZE, random_state=42)
print(X.shape, y.shape)
# 绘制数据集的分布,X 为2D 坐标,y 为数据点的标签
def make_plot(X, y, plot_name, file_name=None, XX=None, YY=None, preds=None,dark=False):
if (dark):
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
plt.figure(figsize=(16,12))
axes = plt.gca()
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=30)
plt.subplots_adj 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









