






快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
[cpp] view plain copy
int AdjustArray(int s[], int l, int r) //返回调整后基准数的位置
{
int i = l, j = r;
int x = s[l]; //s[l]即s[i]就是第一个坑
while (i < j)
{
// 从右向左找小于x的数来填s[i]
while(i < j && s[j] >= x)
j--;
if(i < j)
{
s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑
i++;
}
// 从左向右找大于或等于x的数来填s[j]
while(i < j && s[i] < x)
i++;
if(i < j)
{
s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑
j--;
}
}
//退出时,i等于j。将x填到这个坑中。
s[i] = x;
return i;
}
再写分治法的代码:
[cpp] view plain copy
void quick_sort1(int s[], int l, int r)
{
if (l < r)
{
int i = AdjustArray(s, l, r);//先成挖坑填数法调整s[]
quick_sort1(s, l, i - 1); // 递归调用
quick_sort1(s, i + 1, r);
}
}
这样的代码显然不够简洁,对其组合整理下:
[cpp] view plain copy
//快速排序
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j];
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i];
}
s[i] = x; //注意 是s【i】=x,用最开始的土填上最后的坑
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}
时间复杂度分析:
在最优情况下,Partition每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为.log2n.+1(.x.表示不大于x的最大整数),即仅需递归log2n次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,我们就有了下面的不等式推断。
- T(n)≤2T(n/2) +n,T(1)=0
- T(n)≤2(2T(n/4)+n/2) +n=4T(n/4)+2n
- T(n)≤4(2T(n/8)+n/4) +2n=8T(n/8)+3n
- ……
- T(n)≤nT(1)+(log2n)×n= O(nlogn)
也就是说,在最优的情况下,快速排序算法的时间复杂度为O(nlogn)。
在最坏的情况下,待排序的序列为正序或者逆序,每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为 ,最终其时间复杂度为O(n2)。
,最终其时间复杂度为O(n2)。
平均的情况,设枢轴的关键字应该在第k的位置(1≤k≤n),那么:
 |
由数学归纳法可证明,其数量级为O(nlogn)。
就空间复杂度来说,主要是递归造成的栈空间的使用,最好情况,递归树的深度为log2n,其空间复杂度也就为O(logn),最坏情况,需要进行n‐1递归调用,其空间复杂度为O(n),平均情况,空间复杂度也为O(logn)。
可惜的是,由于关键字的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
优化,博文转自:点击打开链接
4、四种优化方式:
优化1:当待排序序列的长度分割到一定大小后,使用插入排序
原因:对于很小和部分有序的数组,快排不如插排好。当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排
截止范围:待排序序列长度N = 10,虽然在5~20之间任一截止范围都有可能产生类似的结果,这种做法也避免了一些有害的退化情形。摘自《数据结构与算法分析》Mark Allen Weiness 著
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}//else时,正常执行快排 测试数据:
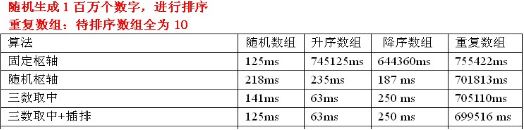
测试数据分析:针对随机数组,使用三数取中选择枢轴+插排,效率还是可以提高一点,真是针对已排序的数组,是没有任何用处的。因为待排序序列是已经有序的,那么每次划分只能使待排序序列减一。此时,插排是发挥不了作用的。所以这里看不到时间的减少。另外,三数取中选择枢轴+插排还是不能处理重复数组
优化2:在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割
举例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三数取中选取枢轴:下标为4的数6
转换后,待分割序列:6 4 6 7 1 6 7 6 8 6
枢轴key:6本次划分后,未对与key元素相等处理的结果:1 4 6 6 7 6 7 6 8 6
下次的两个子序列为:1 4 6 和 7 6 7 6 8 6
本次划分后,对与key元素相等处理的结果:1 4 6 6 6 6 6 7 8 7
下次的两个子序列为:1 4 和 7 8 7
经过对比,我们可以看出,在一次划分后,把与key相等的元素聚在一起,能减少迭代次数,效率会提高不少
具体过程:在处理过程中,会有两个步骤
第一步,在划分过程中,把与key相等元素放入数组的两端
第二步,划分结束后,把与key相等的元素移到枢轴周围
举例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三数取中选取枢轴:下标为4的数6
转换后,待分割序列:6 4 6 7 1 6 7 6 8 6
枢轴key:6第一步,在划分过程中,把与key相等元素放入数组的两端
结果为:6 4 1 6(枢轴) 7 8 7 6 6 6
此时,与6相等的元素全放入在两端了
第二步,划分结束后,把与key相等的元素移到枢轴周围
结果为:1 4 66(枢轴) 6 6 6 7 8 7
此时,与6相等的元素全移到枢轴周围了
之后,在1 4 和 7 8 7两个子序列进行快排
void QSort(int arr[],int low,int high)
{
int first = low;
int last = high;
int left = low;
int right = high;
int leftLen = 0;
int rightLen = 0;
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}
//一次分割
int key = SelectPivotMedianOfThree(arr,low,high);//使用三数取中法选择枢轴
while(low < high)
{
while(high > low && arr[high] >= key)
{
if (arr[high] == key)//处理相等元素
{
swap(arr[right],arr[high]);
right--;
rightLen++;
}
high--;
}
arr[low] = arr[high];
while(high > low && arr[low] <= key)
{
if (arr[low] == key)
{
swap(arr[left],arr[low]);
left++;
leftLen++;
}
low++;
}
arr[high] = arr[low];
}
arr[low] = key;
//一次快排结束
//把与枢轴key相同的元素移到枢轴最终位置周围
int i = low - 1;
int j = first;
while(j < left && arr[i] != key)
{
swap(arr[i],arr[j]);
i--;
j++;
}
i = low + 1;
j = last;
while(j > right && arr[i] != key)
{
swap(arr[i],arr[j]);
i++;
j--;
}
QSort(arr,first,low - 1 - leftLen);
QSort(arr,low + 1 + rightLen,last);
} 测试数据:
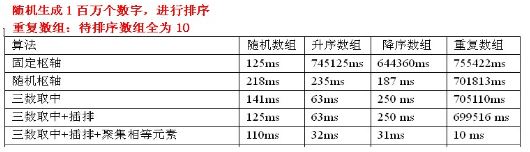
测试数据分析:三数取中选择枢轴+插排+聚集相等元素的组合,效果竟然好的出奇。
原因:在数组中,如果有相等的元素,那么就可以减少不少冗余的划分。这点在重复数组中体现特别明显啊。
其实这里,插排的作用还是不怎么大的。
优化3:优化递归操作
快排函数在函数尾部有两次递归操作,我们可以对其使用尾递归优化
优点:如果待排序的序列划分极端不平衡,递归的深度将趋近于n,而栈的大小是很有限的,每次递归调用都会耗费一定的栈空间,函数的参数越多,每次递归耗费的空间也越多。优化后,可以缩减堆栈深度,由原来的O(n)缩减为O(logn),将会提高性能。
void QSort(int arr[],int low,int high)
{
int pivotPos = -1;
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}
while(low < high)
{
pivotPos = Partition(arr,low,high);
QSort(arr,low,pivot-1);
low = pivot + 1;
}
} 注意:在第一次递归后,low就没用了,此时第二次递归可以使用循环代替
测试数据:

测试数据分析:其实这种优化编译器会自己优化,相比不使用优化的方法,时间几乎没有减少
优化4:使用并行或多线程处理子序列(略)
所有的数据测试:
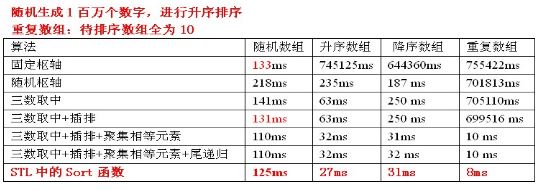
概括:这里效率最好的快排组合 是:三数取中+插排+聚集相等元素,它和STL中的Sort函数效率差不多
注意:由于测试数据不稳定,数据也仅仅反应大概的情况。如果时间上没有成倍的增加或减少,仅仅有小额变化的话,我们可以看成时间差不多。















 3819
3819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}