







1.编译器说明
而现阶段的 hotspot 就是默认使用解释和编译混合 -Xmixed 执行代码,首先会使用模板解释器对字节码进行解释,如果发现一段代码是热点代码则会使用C1、C2等即时编译器优化编译后再执行。
在 Hotspot VM 中解释执行并不是传统意义的一边解释(生成中间代码)一边执行,而是根据字节码类型而派发到对应的机器码去执行,HotSpot VM 有一个 C++ 字节码解释器,还有一个 Template Interpreter 模板解释器。
综合来看 Hotspot VM 的代码执行实际上由三部分形成:C++解释器、模板解释器、JIT编译器,他们的性能是不断优化提升的。早期只有 C++解释器,后来实现了模板解释器,后来加入了 JNI 即使编译实现混合执行。
他们的功能都是将字节码指令转换为机器代码的,其中 JIT(Just-In-Time)意思是机器码代码生成技术,HotSpot中指的 JIT 模块主要是调用 C1/C2 编译器进行编译,如果按照机器码代码生成来讲的话,模板解释器也属于JIT范畴。区别如下:

解释器和编译器都会使用即时代码生成技术,流程是先申请一块内存,将其设置为可执行,再写入机器代码,最后将内存地址转换为函数指针,最后再调用这个函指针。
通过这种方法可以运行时计算 JavaMethod 需要执行的机器代码片段进行调用。
int main(){
// 机器代码
constexpr unsigned char code[] = {
0x55,0x48,0x89,0xe5,0x89,0x7d,0xfc,0x89,0x75,0xf8,
0x8b,0x75,0xfc,0x03,0x75,0xf8,0x89,0xf0,0x5d,0xc3
}
// 申请 ncode 大小的内存,设置为可执行权限
constexpr int ncode = sizeof(code)/sizeof(code[0]);
void* mem = mmap(0,ncode,PROT_WRITE|PORT_EXZEC,MAP_PRIVATE|MAP_ANONYMOUS,-1,0);
memcpy(mem,code,ncode);
// 将地址转换为函数指针
auto add_fun= (int(*)(int,int))mem;
// 调用加法函数
printf("res=%d",add_fun(3,2));
munmap(mem,ncode);
return 0;
}
JIT编译器模块:
负责编译器优化的是 JIT 模块,底层会调用 C1/C2编译器进行编译。
其中C1用于客户端模,需要快速响应用户请求,编译速度块,资源占用少,产出的代码性能适中。
C2用于服务端模式,适用于长期运行的服务端程序,在编译上花更多时间使用更激进的优化以提高全局性能。
AOT编译器模块:
JDK9 引入了 AOT编译器(静态提前编译器,Ahead of Time Compiler),它和 JIT 是并列关系。
JDK9 引入了实验性 AOT 编译工具aotc。它借助了 Graal 编译器,将所输入的 Java 类文件转换为机器码,并存放至生成的动态共享库之中。
所谓 AOT 编译,是与即时编译相对立的一个概念。即时编译指的是在程序的运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。
而 AOT 编译指的则是,在程序运行之前,便将字节码转换为机器码的过程。
破坏了 java“ 一次编译,到处运行”,必须为每个不同的硬件,OS 编译对应的发行包。需要继续优化中,最初只支持 Linux X64 java base。
Graal 编译器:
自 JDK10 起,HotSpot 又加入了一个全新的及时编译器:Graal 编译器。和C1、C2 是并列关系。
目前,带着实验状态标签,需要使用开关参数去激活才能使用。-XX:+UnlockExperimentalvMOptions -XX:+UseJVMCICompiler。
即时编译:
在即时代码生成的基础上我们已经在运行时动态生成了机器代码片段了,但是这些代码的在什么时候下进行生成、按照何种规则进行生成、编译完成后如何被虚拟机执行这就涉及到即时编译技术。分层编译、栈上替换、退优化。
分层编译:
在分层编译的工作模式出现前,HotSpot 虚拟机通常时采用解释器与其中一个编译器直接搭配的方式工作。为了在程序启动相应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机在编译子系统中加入了分层编译功能。JDK 6 时初步实现,JDK 7 开始服务端模式虚拟机中作为默认编译策略被开启。
其中分层编译使用 -XX:+tieredCompilation开启,设置了0~4四个层级,层级之前运行转换。定义如下:
综合了 C1 的高启动性能及 C2 的高峰值性能。这两个 JIT compiler 以及 interpreter 将 HotSpot 的执行方式划分为五个级别:
enum CompLevel {
CompLevel_any = -1,
CompLevel_all = -1,
CompLevel_none = 0, // Interpreter
CompLevel_simple = 1, // C1
CompLevel_limited_profile = 2, // C1, invocation & backedge counters
CompLevel_full_profile = 3, // C1, invocation & backedge counters + mdo
CompLevel_full_optimization = 4, // C2 or Shark }
level 0:interpreter 解释执行。
level 1:C1 编译,无 profiling(性能监控)
level 2:C1 编译,仅方法及循环 back-edge 执行次数的 profiling
level 3:C1 编译,除 level 2 中的 profiling 外还包括 branch(针对分支跳转字节码)及 receiver type(针对成员方法调用或类检测,如 checkcast,instnaceof,aastore 字节码)的 profiling
level 4:C2 编译
栈上替换:
模板解释器会使用方法计数(识别热点函数)和回边计数(识别热点循环),或简称为OSR(On Stack Replacement)编译。OSR机制类似于协程切换,也就是将解释器的数据打包到OSR buffer,然后在编译后的代码里面提取OSR buffer的数据放入编译后的执行栈再继续执行。
为了输出编译行为,-XX:+PrintCompilation开启,会输出所有编译过的方法:

时间戳表示编译完成的时间,与该时间相对的是JVM启动时间。属性字符有多种:
%表示栈上替换(方法后面的@2表示发生栈上替换的字节码索引);
s表示编译同步方法;
!表示方法存在异常处理器;
b表示阻塞模式下发生的编译;
n表示封装native方法所发生的编译。
编译级别即分层编译的等级。方法大小表示Java字节码大小而非编译产出的机器代码大小。
如果发生退优化,需要撤销之前编译过的方法,这时候尾部会标注made notentrant(方法取消进入),或made zombie(僵尸代码)。
产生made not entrant的原因可能是编译器的乐观假设被打破,或者发生了分层编译。
如代码清单7-7所示,MemNode::main方法首先经过3级的C1编译,后续又经过4级的C2编译,此时C1产生的机器代码就会被标注为取消进入,
但是方法仍然保留在CodeCache,直到该方法不被虚拟机及服务线程使用,也不被其他方法调用时,再将方法标注为made zombie。
2.编译队列和编译任务 CompileQueue、
CompileTask
编译队列用来存放编译任务,主要是 add()/remove() 方法。类定义如下:
class CompileQueue : public CHeapObj<mtCompiler> {
private:
const char* _name;
Monitor* _lock;
CompileTask* _first;
CompileTask* _last;
CompileTask* _first_stale;
int _size;
void purge_stale_tasks();
public:
CompileQueue(const char* name, Monitor* lock) {
_name = name;
_lock = lock;
_first = NULL;
_last = NULL;
_size = 0;
_first_stale = NULL;
}
const char* name() const { return _name; }
Monitor* lock() const { return _lock; }
void add(CompileTask* task);
void remove(CompileTask* task);
void remove_and_mark_stale(CompileTask* task);
CompileTask* first() { return _first; }
CompileTask* last() { return _last; }
CompileTask* get();
bool is_empty() const { return _first == NULL; }
int size() const { return _size; }
void mark_on_stack();
void free_all();
NOT_PRODUCT (void print();)
};
编译任务定义如下:
class CompileTask : public CHeapObj<mtCompiler> {
friend class VMStructs;
private:
static CompileTask* _task_free_list; // 空闲的编译任务队列
#ifdef ASSERT
static int _num_allocated_tasks;
#endif
Monitor* _lock; // 该任务的锁
uint _compile_id;
Method* _method; // 该编译任务对应的方法
jobject _method_holder; // _method所属的klass的引用
int _osr_bci; // 栈上替换方法相对于字节码基地址的偏移
bool _is_complete; // 编译任务的状态
bool _is_success;
bool _is_blocking;
int _comp_level; // 编译级别
int _num_inlined_bytecodes; // 栈上替换方法对应的字节码的字节数
nmethodLocker* _code_handle; // nmethodLocker是nmethod的一个容器,用来保存编译完成的代码
CompileTask* _next, *_prev;
bool _is_free;
// Fields used for logging why the compilation was initiated:
jlong _time_queued; // in units of os::elapsed_counter()
Method* _hot_method; // which method actually triggered this task
jobject _hot_method_holder;
int _hot_count; // information about its invocation counter
const char* _comment; // more info about the task
const char* _failure_reason;
// 省略
};
编译任务提交函数是 CompileBroker::compile_method(),编译策略对象 AdvancedThresholdPolicy::submit_compile() 中会调用这个函数提交编译任务:
nmethod* CompileBroker::compile_method(methodHandle method, int osr_bci,
int comp_level,
methodHandle hot_method, int hot_count,
const char* comment, Thread* THREAD) {
// 省略
// do the compilation
if (method->is_native()) {
// PreferInterpreterNativeStubs表示是否总是使用解释器的stub调用本地方法,默认值为false
if (!PreferInterpreterNativeStubs || method->is_method_handle_intrinsic()) {
AdapterHandlerLibrary::create_native_wrapper(method);
} else {
return NULL;
}
} else {
// 如果因为CodeCache满了则延缓编译
if (!should_compile_new_jobs()) {
CompilationPolicy::policy()->delay_compilation(method());
return NULL;
}
// 执行编译
compile_method_base(method, osr_bci, comp_level, hot_method, hot_count, comment, THREAD);
}
return osr_bci == InvocationEntryBci ? method->code() : method->lookup_osr_nmethod_for(osr_bci, comp_level, false);
}
最终在 CompileBroker::compile_method_base() 函数中创建 CompileTask 编译任务并提交,代码如下:
void CompileBroker::compile_method_base(methodHandle method,
int osr_bci,
int comp_level,
methodHandle hot_method,
int hot_count,
const char* comment,
Thread* thread) {
// 省略
// Outputs from the following MutexLocker block:
CompileTask* task = NULL;
bool blocking = false;
CompileQueue* queue = compile_queue(comp_level);
// Acquire our lock.
{
// 省略
// 编译任务创建,并添加到编译队列中
task = create_compile_task(queue,compile_id, method,osr_bci, comp_level,hot_method, hot_count, comment,blocking);
}
// 判断是否等待便已完成
if (blocking) {
wait_for_completion(task);
}
}
3.编译策略以及编译任务提交
现在编译线程、编译器C1/C2、编译队列、任务提交入口等都有了,就等编译任务的提交了,在 Hotspot 种编译任务的提交是编译策略来控制的。在全局初始化时,会初始化编译策略。编译策略初始化如下:
hotspot/src/share/vm/runtime/init.cpp init_globals() => 全局模块初始化入口
hotspot/src/share/vm/runtime/compilationPolicy.cpp compilationPolicy_init() => 初始化编译策略,CompilationPolicyChoice 默认为3。
void compilationPolicy_init() {
CompilationPolicy::set_in_vm_startup(DelayCompilationDuringStartup);
switch(CompilationPolicyChoice) {
case 0:
CompilationPolicy::set_policy(new SimpleCompPolicy());
break;
case 1:
#ifdef COMPILER2
CompilationPolicy::set_policy(new StackWalkCompPolicy());
#else
Unimplemented();
#endif
break;
case 2:
#ifdef TIERED
CompilationPolicy::set_policy(new SimpleThresholdPolicy());
#else
Unimplemented();
#endif
break;
case 3:
#ifdef TIERED
CompilationPolicy::set_policy(new AdvancedThresholdPolicy());
#else
Unimplemented();
#endif
break;
default:
fatal("CompilationPolicyChoice must be in the range: [0-3]");
}
CompilationPolicy::policy()->initialize();
}
根据 CompilationPolicyChoice 取值在 server 下默认为3,也就是 AdvancedThresholdPolicy 高级阈值策略,然后调用策略初始化函数。代码如下:
void AdvancedThresholdPolicy::initialize() {
// Turn on ergonomic compiler count selection
if (FLAG_IS_DEFAULT(CICompilerCountPerCPU) && FLAG_IS_DEFAULT(CICompilerCount)) {
FLAG_SET_DEFAULT(CICompilerCountPerCPU, true);
}
int count = CICompilerCount;
// 考虑机器的CPU数量,计算总的后台编译线程数
if (CICompilerCountPerCPU) {
// Simple log n seems to grow too slowly for tiered, try something faster: log n * log log n
int log_cpu = log2_intptr(os::active_processor_count());
int loglog_cpu = log2_intptr(MAX2(log_cpu, 1));
count = MAX2(log_cpu * loglog_cpu, 1) * 3 / 2;
}
// 根据上面计算结果设置 c1/c2线程数
set_c1_count(MAX2(count / 3, 1));
set_c2_count(MAX2(count - c1_count(), 1));
FLAG_SET_ERGO(intx, CICompilerCount, c1_count() + c2_count());
// InlineSmallCode表示只有当方法代码大小小于该值时才会使用内联编译的方式,x86下默认是1000
// 这里是将其调整为2000
#ifdef X86
if (FLAG_IS_DEFAULT(InlineSmallCode)) {
FLAG_SET_DEFAULT(InlineSmallCode, 2000);
}
#endif
#ifdef SPARC
if (FLAG_IS_DEFAULT(InlineSmallCode)) {
FLAG_SET_DEFAULT(InlineSmallCode, 2500);
}
#endif
// IncreaseFirstTierCompileThresholdAt 默认是50%,当CodeCache的已使用量大于50%时就会开始提高触发C1编译的阈值
set_increase_threshold_at_ratio();
set_start_time(os::javaTimeMillis());
}
其他重要的方法:
AdvancedThresholdPolicy::method_invocation_event() => 用于触发普通方法调用下热点代码的编译,
AdvancedThresholdPolicy::method_back_branch_event => 方法用于处理循环调用下热点代码即osr方法的编译。
AdvancedThresholdPolicy::call_event() => call_event方法用于计算方法调用超过阈值时触发的编译的编译级别
AdvancedThresholdPolicy::loop_event() => loop_event方法用于计算循环调用超过阈值时触发的编译的编译级别
其中 AdvancedThresholdPolicy 支持的编译级别:
/*
* The system supports 5 execution levels:
* * level 0 - interpreter
* * level 1 - C1 with full optimization (no profiling)
* * level 2 - C1 with invocation and backedge counters
* * level 3 - C1 with full profiling (level 2 + MDO)
* * level 4 - C2
*/
其中0,2,3三个级别下都会周期性的通知 AdvancedThresholdPolicy某个方法的方法调用计数即invocation counters and循环调用计数即backedge counters。
不同级别下通知的频率不同。这些通知用来决定如何调整编译级别。常见的各级别转换路径如下:
0 -> 3 -> 4,最常见的转换路径,需要注意这种情况下profile可以从level 0开始,level3结束。
0 -> 2 -> 3 -> 4,当C2的编译压力较大会发生这种情形,本来应该从0直接转换成3,为了减少编译耗时就从0转换成2,等C2的编译压力降低再转换成3
0 -> (3->2) -> 4,这种情形下已经把方法加入到3的编译队列中了,但是C1队列太长了导致在0的时候就开启了profile,然后就调整了编译策略按level 2来编译,即时还是3的队列中,这样编译更快
0 -> 3 -> 1 or 0 -> 2 -> 1,当一个方法被C1编译后,被标记成trivial的,因为这类方法C2编译的代码和C1编译的代码是一样的,所以不使用4,改成1
0 -> 4,一个方法C1编译失败且一直在收集profile信息,就从0切换到4
最终提交编译任务:
hotspot/src/share/vm/runtime/simpleThresholdPolicy.cpp SimpleThresholdPolicy::compile() => 检查方法是否可以编译,可能会修改编译级别
AdvancedThresholdPolicy::submit_compile() => 提交编译任务
CompileBroker::compile_method => 提交编译任务最终入口
在执行OSR栈上替换或者编译任务提交之前,编译策略的决定由 AdvancedThresholdPolicy::common() 函数进行处理,这样才能在SimpleThresholdPolicy::submit_compile()函数提交编译任务。common()函数的实现如下:
CompLevel AdvancedThresholdPolicy::common(Predicate p, Method* method, CompLevel cur_level, bool disable_feedback) {
// 当为OSR编译时,disable_feedback为true,方法编译时,为false
CompLevel next_level = cur_level;
int i = method->invocation_count();
int b = method->backedge_count();
// 当一个方法足够简单时,使用C1编译器就能达到C2的效果
if (is_trivial(method)) {
next_level = CompLevel_simple;
} else {
switch(cur_level) {
case CompLevel_none:
// 当前的编译级次为ComLevel_none,可能会直接到CompLevel_full_optimization级别,如果Metod::_method_data不为NULL并且已经采集了足够信息的话
if (common(p, method, CompLevel_full_profile, disable_feedback) == CompLevel_full_optimization) {
next_level = CompLevel_full_optimization;
}
// 调用AdvancedThresholdPolicy::call_predicate()或AdvancedThresholdPolicy::loop_predicate()函数,
// 函数如果返回true,表示已经充分收集了profile信息,可直接采用第3层的CompLevel_full_profile编译
else if ((this->*p)(i, b, cur_level)) {
// 在 C2 忙碌的情况下,方法会被CompLevel_limited_profile的C1编译,然后再被
// CompLevel_full_profile的C1编译,目的是减少方法在CompLevel_full_profile的执行时间
// Tier3DelayOn的英文解释为:If C2 queue size grows over this amount per compiler thread
// stop compiling at tier 3 and start compiling at tier 2
if (!disable_feedback && CompileBroker::queue_size(CompLevel_full_optimization) > Tier3DelayOn * compiler_count(CompLevel_full_optimization)) {
next_level = CompLevel_limited_profile;
}
// C2如果不忙碌,直接使用CompLevel_full_profile的C1编译即可
else {
next_level = CompLevel_full_profile;
}
}
break;
case CompLevel_limited_profile:
// 特殊情况下,可能解释执行过程中已经采集了足够的运行时信息,直接采用CompLevel_full_optimization的C2编译
if (is_method_profiled(method)) {
next_level = CompLevel_full_optimization;
} else {
MethodData* mdo = method->method_data();
if (mdo != NULL) {
// 如果C2的负载不高时,采用CompLevel_full_profile进行信息的采集
// Tier3DelayOff的英文解释为:If C2 queue size is less than this amount per compiler thread
// allow methods compiled at tier 2 transition to tier 3
if (mdo->would_profile()) {
if (disable_feedback || (CompileBroker::queue_size(CompLevel_full_optimization) <=
Tier3DelayOff * compiler_count(CompLevel_full_optimization) &&
(this->*p)(i, b, cur_level))) {
next_level = CompLevel_full_profile;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
case CompLevel_full_profile:
{
MethodData* mdo = method->method_data();
if (mdo != NULL) {
if (mdo->would_profile()) {
int mdo_i = mdo->invocation_count_delta();
int mdo_b = mdo->backedge_count_delta();
if ((this->*p)(mdo_i, mdo_b, cur_level)) {
next_level = CompLevel_full_optimization;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
}
}
return MIN2(next_level, (CompLevel)TieredStopAtLevel);
}
上面的编译策略会根据热点代码来调用 SimpleThresholdPolicy::compile() 提交编译任务吗,并且提供了分层,下一步就是热点代码统计并触发编译任务提交了。
4.热点代码检测-调用计数
在 Java 函数调用过程中 InterpreterGenerator::generate_native_entry()、InterpreterGenerator::generate_normal_entry() 两个函数在调用中会调用热点统计和判断:
InterpreterGenerator::generate_counter_incr() => 增加调用次数,这种计次判断时提交个编译任务,不会等待编译完成以及栈上替换。
InterpreterGenerator::generate_counter_overflow() => 次数超过阈值
计数信息在 Method 类上有定义:
class Method : public Metadata {
friend class VMStructs;
private:
ConstMethod* _constMethod; // Method read-only data.
MethodData* _method_data;
MethodCounters* _method_counters;
..
};
其中 MethodCounters 类用于热点代码跟踪中的方法调用计数和回边计数:
class MethodCounters: public MetaspaceObj {
friend class VMStructs;
private:
InvocationCounter _invocation_counter; // 记录方法调用的次数
InvocationCounter _backedge_counter; // 记录循环跳转的次
..
};
这两个字段可以使用HSDB进行查看, _counter的值,实际的调用计数需要将其右移三位计算就能知道一个方法调用的次数了:
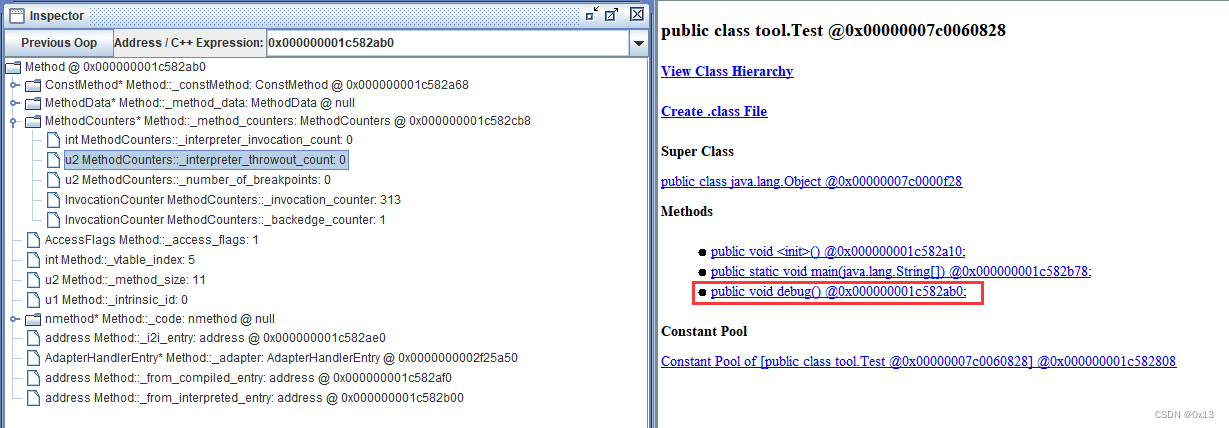
每一个方法都会对应一个方法调用计数器,为了尽可能节省内存空间,HotSpot VM使用_counter记录多个数据信息,这是一个整数类型的组合数字, counter、carry、state 三个字段用一个32位 int 类型数据表示,其中:
* counter:第3-31位表示方法调用计数,每次方法调用加1(每增加一次计数,_counter的值要加8,因为低3位不用来计数),超过半衰周期未触发编译则数据减半,触发编译后调用 reset()函数重置 InvocationCounter 所有数据;
* carry:第2位表示当前方法是否已被编译,方法调用计数器达到阈值并触发编译动作后,carry 被设置为1,表示该方法已被编译;
* state:第0位和第1位表示超出阈值时的处理,枚举值由InvocationCounter类中的State枚举类定义,wait_for_nothing 表示方法调用次数超过阈值后不触发编译,wait_for_compile 表示方法调用次数超过阈值后触发编译。
例如Java普通函数调用过程:
address InterpreterGenerator::generate_normal_entry(bool synchronized) {
// entry_point函数的代码入口地址
address entry_point = __ pc();
// 省略
// 增加方法计数
if (inc_counter) {
generate_counter_incr(&invocation_counter_overflow,&profile_method,&profile_method_continue);
if (ProfileInterpreter) {
__ bind(profile_method_continue);
}
}
// 省
// 跳转到目标Java方法的第一条字节码指令,并执行其对应的机器指令,也就是指令分派了
__ dispatch_next(vtos);
// 次数超过阈值
if (inc_counter) {
// 省略
generate_counter_overflow(&continue_after_compile);
}
return entry_point;
}
这个函数传递的三个参数到 generate_counter_incr() 中,用于后续在判断是否超过limit之后需要跳转的入口:
Label* overflow:rcx的值是否超过InterpreterInvocationLimit,如果大于等于则跳转到overflow
Label* profile_method:则校验methodData是否存在,如果不存在则跳转到profile_method
Label* profile_method_continue:如果rcx的值小于InterpreterProfileLimit,则跳转到profile_method_continue
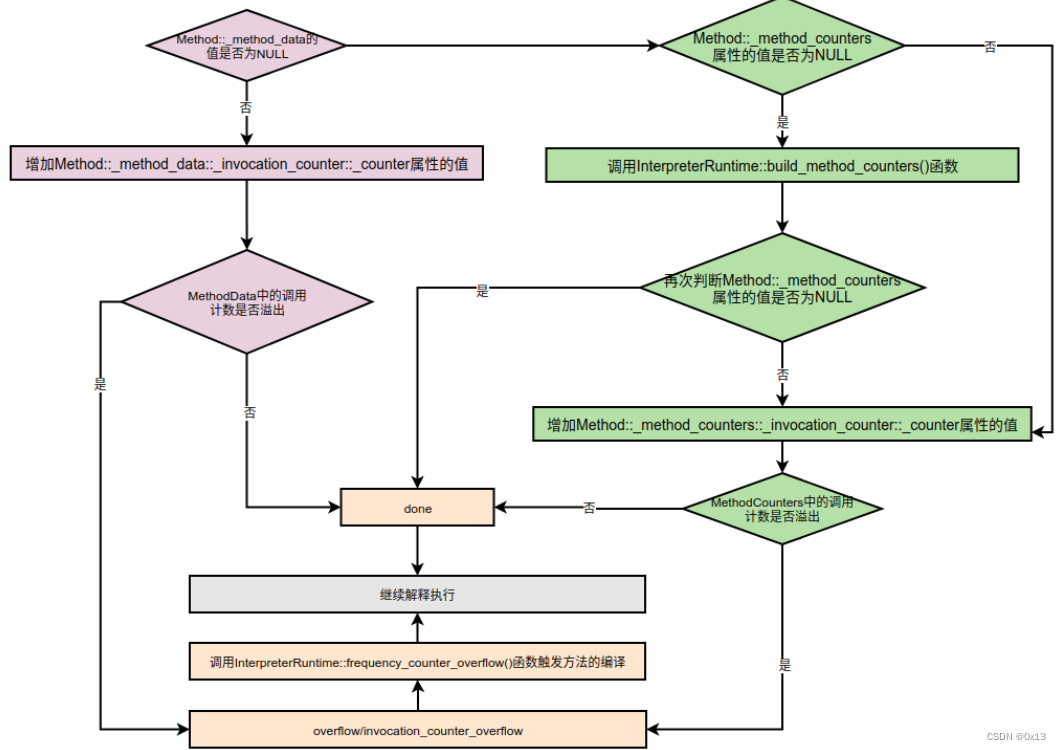
在函数 InterpreterGenerator::generate_counter_incr() 中会增加调用次数,同时也会做调用次数判断。检查Method::_method_data和Mehod::_method_counters属性是否为NULL。
如果不为NULL,则分别向Method::_method_data::_invocation_counter::_counter和Method::_method_counters::_invocation_counter::_counter属性中增加调用计数。
同时还会检查是否溢出,超过调用限制还会触发编译。代码如下:
void InterpreterGenerator::generate_counter_incr(Label* overflow,Label* profile_method,Label* profile_method_continue) {
Label done;
//server模式下默认启用分级编译
if (TieredCompilation) {
//因为InvocationCounter的_counter中调用计数部分是前29位,所以增加一次调用计数需要加8,而是1<<3即8
int increment = InvocationCounter::count_increment;
//Tier0InvokeNotifyFreqLog默认值是7,count_shift是_counter属性中非调用计数部分的位数,这里是3
int mask = ((1 << Tier0InvokeNotifyFreqLog) - 1) << InvocationCounter::count_shift;
Label no_mdo;
//开启性能收集
if (ProfileInterpreter) {
// Are we profiling?
__ movptr(rax, Address(rbx, Method::method_data_offset()));
__ testptr(rax, rax);
__ jccb(Assembler::zero, no_mdo);
//获取MethodData的_invocation_counter属性的_counter属性的地址
const Address mdo_invocation_counter(rax, in_bytes(MethodData::invocation_counter_offset()) +in_bytes(InvocationCounter::counter_offset()));
__ increment_mask_and_jump(mdo_invocation_counter, increment, mask, rcx, false, Assembler::zero, overflow);
__ jmp(done);
}
__ bind(no_mdo);
//获取MethodCounters的_invocation_counter属性的_counter属性的地址,get_method_counters方法会将MethodCounters的地址放入rax中
const Address invocation_counter(rax,MethodCounters::invocation_counter_offset() +InvocationCounter::counter_offset());
//获取MethodCounters的地址并将其放入rax中
__ get_method_counters(rbx, rax, done);
//增加计数
__ increment_mask_and_jump(invocation_counter, increment, mask, rcx,false, Assembler::zero, overflow);
__ bind(done);
} else {
//获取MethodCounters的_backedge_counter属性的_counter属性的地址
const Address backedge_counter(rax,MethodCounters::backedge_counter_offset() +InvocationCounter::counter_offset());
//获取MethodCounters的_invocation_counter属性的_counter属性的地址
const Address invocation_counter(rax,MethodCounters::invocation_counter_offset() + InvocationCounter::counter_offset());
//获取MethodCounters的地址并将其放入rax中
__ get_method_counters(rbx, rax, done);
//如果开启性能收集
if (ProfileInterpreter) {
//因为value为0,所以这里啥都不做
__ incrementl(Address(rax,MethodCounters::interpreter_invocation_counter_offset()));
}
//更新invocation_counter
__ movl(rcx, invocation_counter);
__ incrementl(rcx, InvocationCounter::count_increment);
__ movl(invocation_counter, rcx); // save invocation count
__ movl(rax, backedge_counter); // load backedge counter
__ andl(rax, InvocationCounter::count_mask_value); // mask out the status bits
//将rcx中的调用计数同rax中的status做且运算
__ addl(rcx, rax); // add both counters
// profile_method is non-null only for interpreted method so
// profile_method != NULL == !native_call
if (ProfileInterpreter && profile_method != NULL) {
//如果rcx的值小于InterpreterProfileLimit,则跳转到profile_method_continue
__ cmp32(rcx, ExternalAddress((address)&InvocationCounter::InterpreterProfileLimit));
__ jcc(Assembler::less, *profile_method_continue);
//如果大于,则校验methodData是否存在,如果不存在则跳转到profile_method
__ test_method_data_pointer(rax, *profile_method);
}
//比较rcx的值是否超过InterpreterInvocationLimit,如果大于等于则跳转到overflow
__ cmp32(rcx, ExternalAddress((address)&InvocationCounter::InterpreterInvocationLimit));
__ jcc(Assembler::aboveEqual, *overflow);
__ bind(done);
}
}
如果调用次数超过限制会调用 InterpreterGenerator::generate_counter_overflow() 提交编译任务,这时 Java 后续按照 done 继续解释执行,不会等这个编译任务编译完成:
void InterpreterGenerator::generate_counter_overflow(Label* do_continue) {
//InterpreterRuntime::frequency_counter_overflow需要两个参数,第一个参数thread在执行call_VM时传递,第二个参数表明
//调用计数超过阈值是否发生在循环分支上,如果否则传递NULL,我们传递0,即NULL,如果是则传该循环的跳转分支地址
//这个方法返回编译后的方法的入口地址,如果编译没有完成则返回NULL
__ movl(c_rarg1, 0);
__ call_VM(noreg,CAST_FROM_FN_PTR(address,InterpreterRuntime::frequency_counter_overflow),c_rarg1);
__ movptr(rbx, Address(rbp, method_offset)); // restore Method*
__ jmp(*do_continue, relocInfo::none);
}
InterpreterGenerator::generate_counter_overflow() =>
InterpreterRuntime::frequency_counter_overflow() =>
frequency_counter_overflow_inner() => 根据 branch_bcp 参数是否为null来判断是否是需要栈上替换的函数,是则提交编译任务并执行替换,否则异步提交编译任务
SimpleThresholdPolicy::event() =>
AdvancedThresholdPolicy::method_back_branch_event() =>
SimpleThresholdPolicy::compile() => 最终提交编译任务
AdvancedThresholdPolicy::submit_compile() => 提交任务
CompileBroker::compile_method_base() => 提交任务
其中判断是否是OSR是在 frequency_counter_overflow() 函数中,如果需要OSR则会继续调用 method->lookup_osr_nmethod_for()
nmethod* InterpreterRuntime::frequency_counter_overflow(JavaThread* thread, address branch_bcp) {
// 非OSR时这里会一直返回null
nmethod* nm = frequency_counter_overflow_inner(thread, branch_bcp);
assert(branch_bcp != NULL || nm == NULL, "always returns null for non OSR requests");
if (branch_bcp != NULL && nm != NULL) {
// 目标方法是一个需要栈上替换的方法,因为frequency_counter_overflow_inner() 函数返回的nm没有加载,所以需要再次查找
frame fr = thread->last_frame();
Method* method = fr.interpreter_frame_method();
int bci = method->bci_from(fr.interpreter_frame_bcp());
nm = method->lookup_osr_nmethod_for(bci, CompLevel_none, false);
}
#ifndef PRODUCT
if (TraceOnStackReplacement) {
if (nm != NULL) {
tty->print("OSR entry @ pc: " INTPTR_FORMAT ": ", nm->osr_entry());
nm->print();
}
}
#endif
return nm;
}
当为非OSR编译时(需要对整个方法进行编译),frequency_counter_overflow_inner() 函数永远返回null,即不会立即执行编译,而是提交任务给后台编译线程编译;
当为OSR编译时,传递的branch_bcp参数不为null,在调用的frequency_counter_overflow_inner()函数中通常会等待编译完成后才会返回。
5.热点代码检测-回边计数OSR
除了上面调用计次之外,还有一类for{}循环、分支跳转中的代码块,通过 javap -v 查看 for 循环字节码指令,主要和 branch 有关。当循环次数达到一定数量就会触发OSR也就是栈上替换。
其中 goto 的字节码指令如下:
void TemplateTable::_goto() {
transition(vtos, vtos);
branch(false, false);
}
其中 _goto d调用了 branch 指令就用于 for、分支跳转等,而即使编译并执行OSR(用编译后的本地代码替换掉原来的字节码指令,所谓的栈上替换就是替换调用入口地址,将原来解释器上的变量,monitor等迁移到编译后的本地代码对应的栈帧中)这一部分逻辑就在 branch 实现中。
最终会调用 InterpreterRuntime::frequency_counter_overflow() 等待编译完成并执行栈上替换。流程如下:
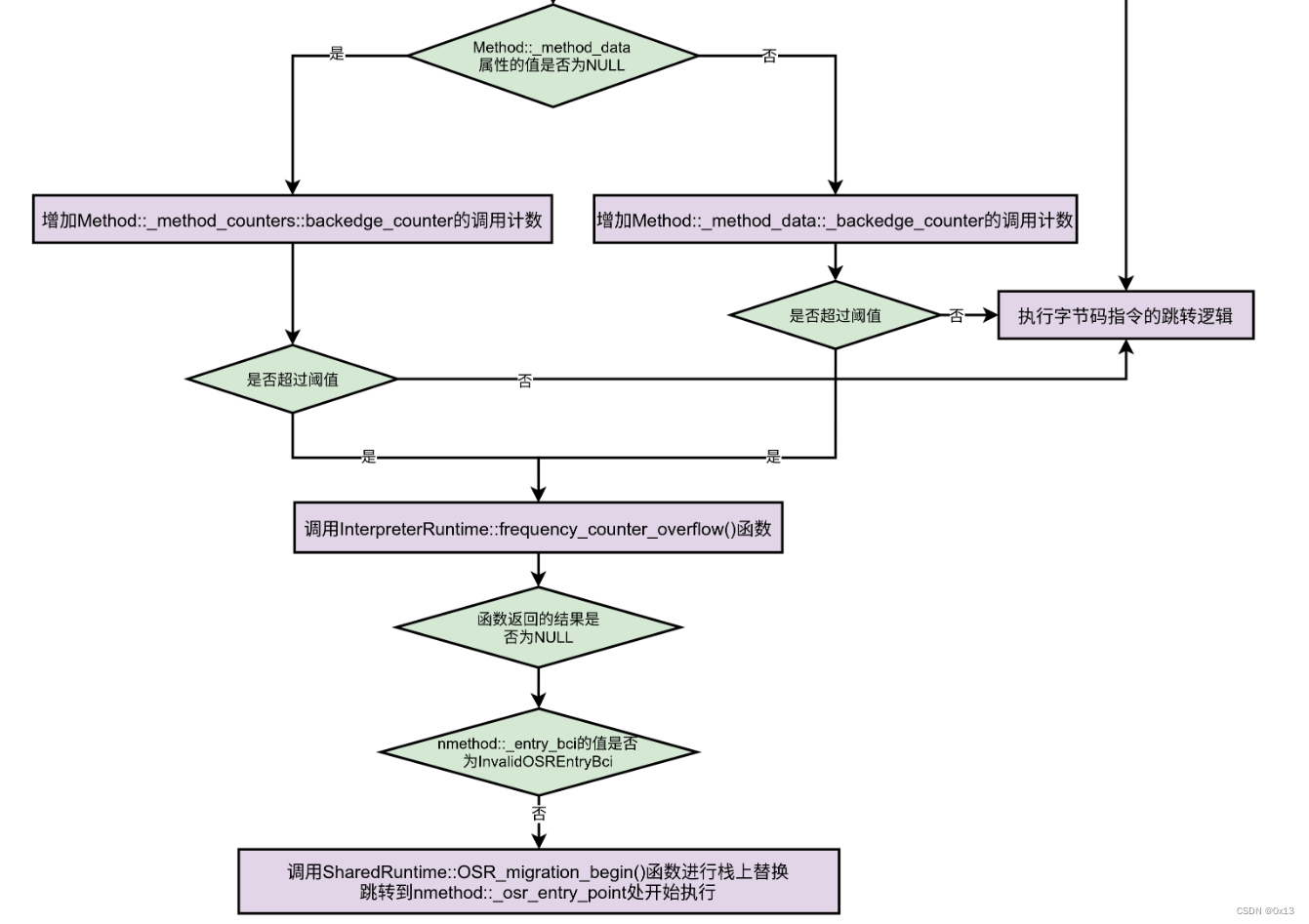
代码如下:
void TemplateTable::branch(bool is_jsr, bool is_wide) {
// 省略
//将当前字节码地址加上rdx保存的偏移量,计算跳转的目标地址
__ addptr(r13, rdx);
// 调用 frequency_counter_overflow() 提交编译任务
__ call_VM(noreg,CAST_FROM_FN_PTR(address,InterpreterRuntime::frequency_counter_overflow),rdx);
// 省略
//开始执行栈上替换了
//将rax中的osr的地址拷贝到r13中
__ mov(r13, rax); // save the nmethod
//调用OSR_migration_begin方法,完成栈帧上变量和monitor的迁移
call_VM(noreg, CAST_FROM_FN_PTR(address, SharedRuntime::OSR_migration_begin));
// 省略
const Register retaddr = j_rarg2;
const Register sender_sp = j_rarg1;
__ movptr(sender_sp, Address(rbp, frame::interpreter_frame_sender_sp_offset * wordSize)); // get sender sp
__ leave(); // remove frame anchor
__ pop(retaddr); // get return address
__ mov(rsp, sender_sp); // set sp to sender sp
__ andptr(rsp, -(StackAlignmentInBytes));
__ push(retaddr);
// 跳转到OSR nmethod,开始执行
__ jmp(Address(r13, nmethod::osr_entry_point_offset()));
}
}
}















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











