







混合LoRA专家MoLE
论文概况

- 第一作者发文时为清华软件学院研三学生Xun Wu(吴浔),在微软亚洲研究院自然语言计算组实习,其AMiner主页为https://www.aminer.cn/profile/Xun%20Wu/53f3a428dabfae4b34acdd7c。
- 其他两位作者都是微软亚洲研究院的大牛,尤其Furu Wei,其AMiner主页为https://www.aminer.cn/profile/furu-wei/542ac39fdabfae61d49a4deb
- 论文:https://arxiv.org/pdf/2404.13628
- 代码:https://github.com/yushuiwx/MoLE.git(但是目前还没有公开代码)
目录
引言
最近在研读LoRA相关论文时发现了这篇《MIXTURE OF LORA EXPERTS》,其方法、思想正好能为我所用,遂趁组会汇报此文。
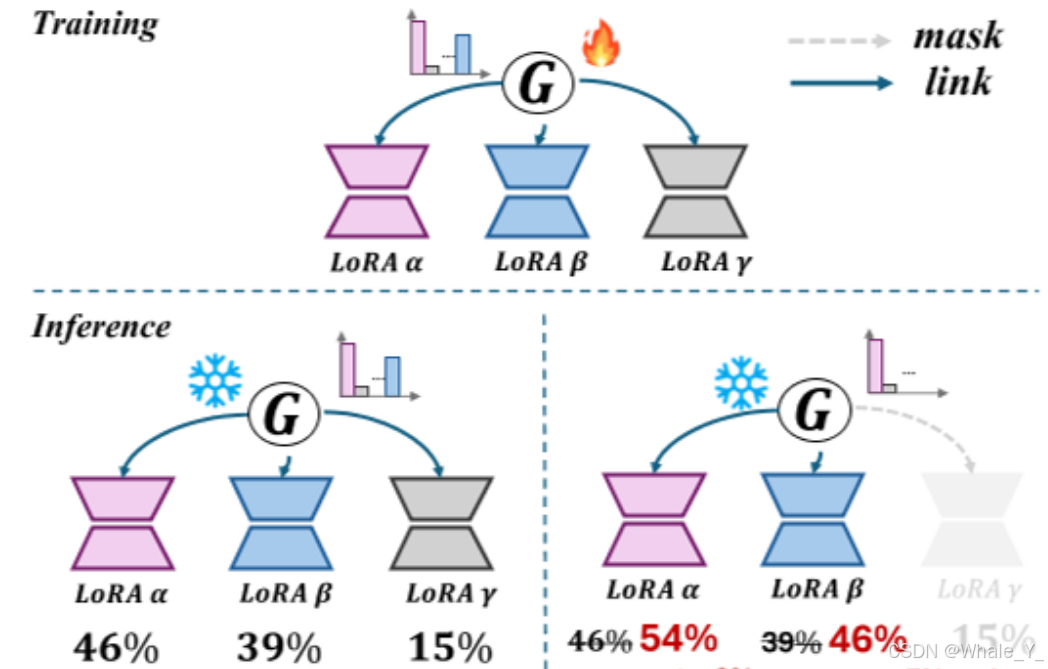
↓↓↓Workflow of MOLE. ↓↓↓
前置知识
- 针对此领域知识尚不熟悉的读者,文节将从微调(Fine-tuning)→LoRA→MoE逐步介绍,掌握此部分知识的读者可以直接查看问题引入。
微调~
- 什么是模型微调(Fine-tuning)?
简单讲就是,在预训练模型的基础上进行进一步训练,以适应特定的任务或数据集。 - 为什么要进行微调?
提高性能、适应特定任务、节省训练时间、减少数据需求、提高泛化能力和降低计算成本等。 - 常见的微调方法有哪几种呢?
首先我们根据微调的参数量将微调大概分为大型模型的全面微调(Full Fine-tuning)FFT和参数高效微调(Parameter-Efficient Fine-Tuning)PEFT。
大型模型的全面微调(Full Fine-tuning)FFT是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。
参数高效微调(Parameter-Efficient Fine-Tuning)PEFT旨在通过最小化微调参数数量和计算复杂度,提升预训练模型在新任务上的表现,从而减轻大型预训练模型的训练负担。
虽然FFT可以获得更好的性能但其需要大量的计算资源和时间成本,而PEFT不仅能提升模型效果,还能显著缩短训练时间和计算成本,使更多研究者能够参与到深度学习的研究中,所以其应用更加广泛。
- 常用的参数高效微调PEFT有哪些呢?
LoRA(LOW-RANK ADAPTATION)系列、Adapter Tuning适配器微调、Prefix Tuning前置微调、Prompt Tuning提示微调(包括P-Tuning系列)等(具体区别和特点可以查看这篇文章),其中LoRA因其能提升参数调整效度,高效切换任务、减少推理延迟,进一步降低微调成本并且更具性价比而被广泛使用。 - LoRA的原理是什么呢?
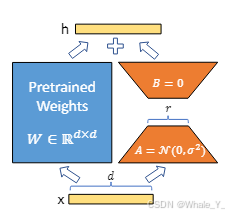
我们从提出LoRA的原文中获取答案,“它冻结预训练模型权重并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量”[LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS,2022ICLR,微软公司]。简单理解就是在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改,细节可以去查看原文。
↓↓↓LoRA ↓↓↓
- MoE呢?这和LoRA又有什么联系?
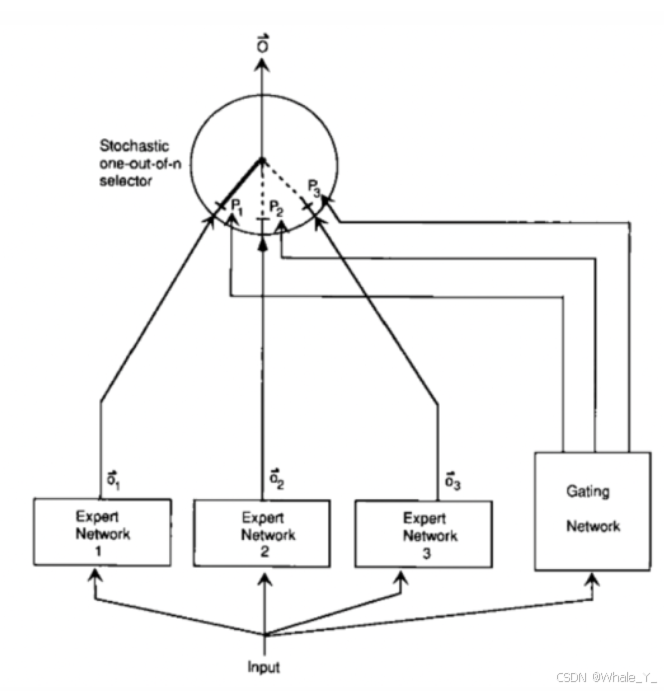
什么是MoE?这要追溯到1991年的一篇论文Adaptive mixtures of local experts。其主要思路是设立多个互相独立的专家系统(Expert Network),将一个复杂场景分割成多个特定场景,并由每个expert独立的处理特定场景中的某个子任务,从而实现学习网络独立的权重更新,说白了专业的事情交给专业的人干,这个“人”可以是一个专家,也可以是一群专家协作,总之目的是要达到最好效果。
↓↓↓MoE ↓↓↓
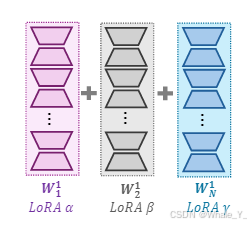
那MoE和LoRA又有什么联系呢?LoRA有个特点是可以高效切换任务,如何做到的呢,通过训练多个LoRA模块达到对不同下游任务的微调,通过使用和屏蔽不同的LoRA模块来实现任务切换,有没有发现这里的一个LoRA模块是不是就像是一个expert,一个LoRA模块负责一项任务,于是乎很多学者便对此展开了很多研究,包括我们要介绍的这篇文章也是基于此展开。
问题引入
- 本文基于什么背景展开研究?
这里我们摘自原文“LoRA 的模块化架构促进了对多个训练 LoRA 的协同组合的进一步研究,旨在放大各种任务的性能。然而,这些训练有素的 LoRA 的有效组合提出了一个艰巨的挑战:(1)线性算术组合可能会导致原始预训练模型固有的生成能力或单独训练的LoRA独特属性的降低,从而可能导致次优结果。(2) 基于参考调整的组合在适应性方面表现出局限性,并且由于需要重新训练大型模型,会产生显着的计算成本。”
总结一下就是:(1)线性组合多个 LoRA(通常 ≥ 3)会损害预训练模型的生成性能,为了缓解这种情况,在组合之前应用了权重归一化,但可能会擦除单个训练 LoRA 的独特特征;
↓↓↓
(2) 而为V&L领域提出的Mask方法虽然取得了较好的性能但是手动设计的掩码,它在 LoRA 灵活性方面受到限制,并且涉及大量的训练成本,需要进行完整的模型再训练。
↓↓↓
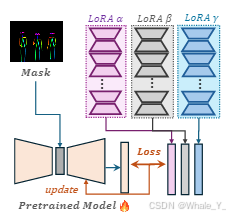
如何在动态、高效的组合多个训练好的LoRA模型的同时,保留每个LoRA模型的自己的特征?
- 为了解决此问题,文章提出了LoRA专家混合模型(MoLE)。MoLE将每一层经过训练的LoRA视为一个独特的专家,并通过在每一层中集成可学习的门控函数来实现分层权重控制,以学习专门针对给定领域目标量身定制的最佳组合权重。MoLE不仅在LoRA合成中表现出增强的性能,而且保留了以最小的计算开销有效合成训练好的LoRA所需的基本灵活性。
↓↓↓
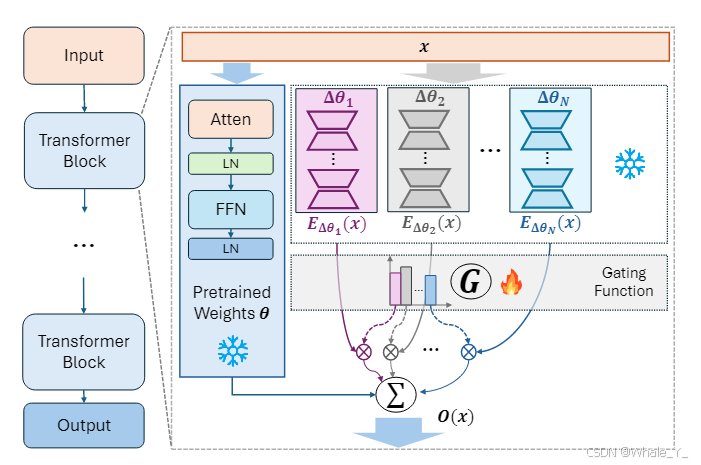
模型解读
- MoLE,混合LoRA专家(Mixture of LoRA Experts)。我们以上图为例来对其进行解读。
- 左侧为整个模型的输入到输出,其中是多个Transformer块,右侧是Transformer块详情展开;
- 右侧部分顶部由x表示输入,底部O(x)表示输出,左边蓝色框中是一个Transformer块的流程,即Atten注意力层、LN归一化层(此处省略了残差链接Add)、FFN前馈层和前馈后的归一化层(省略了残差链接Add),右边则是数个LoRA模块,其下方的G层表示门控函数(Gating Function),再下方表示数个LoRA模块的输出经过一个训练好的门控G函数进行组合权重优化,最后合并蓝色模块原始的Transformer输出得到最终输出。
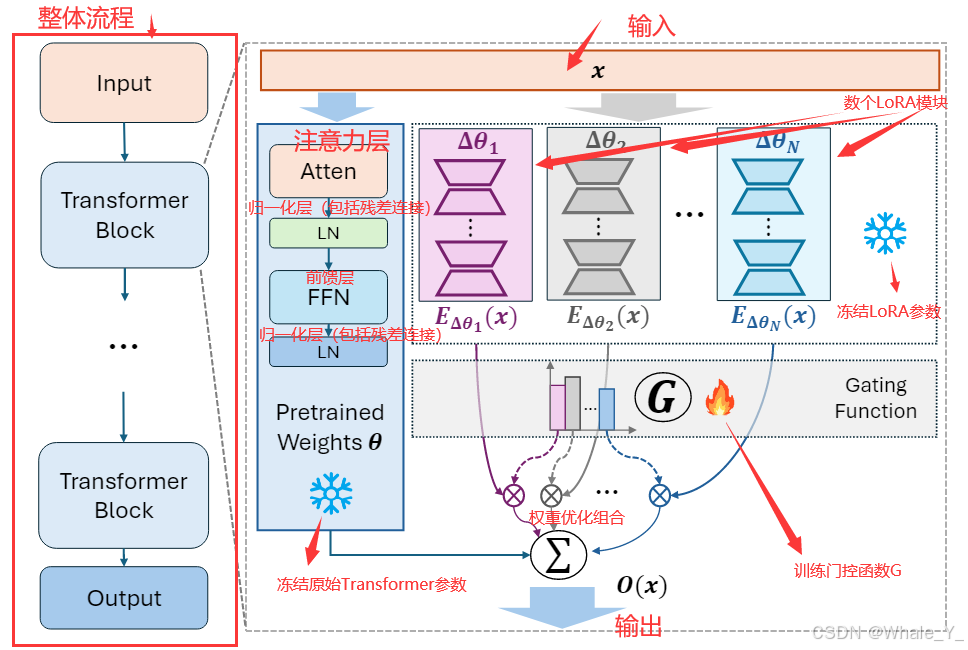
- MoLE整体的过程如上图所示,其中细节部分我们在下节“公式解读”中展开描述。
公式解读
-
(1)公式1出现在文中背景部分,描述的是常用的简单LoRA组合方法,其中 W ^ \hat{W} W^表示模型微调后参数, W W W表示预训练模型的原始参数, △ \triangle △ W W W i 表示 i t h i^{th} ith训练的 LoRA参数, N N N表示LoRA的个数,这种方式可能会在 N N N增加时影响原始权重 W W W,从而降低模型的生成能力,因此有了下面第二个公式“规范化的线性算术组合”。

-
(2)公式2是上述公式1的改进,让 Δ \Delta Δ W W W i 乘了一个为每个LoRA分配的权重 w w w i ,其中 ∑ i = 1 N \sum^N_{i=1} ∑i=1N w w w i = 1。这种方式可以防止对原始模型嵌入产生任何不利影响,但会导致单个 LoRA 特征的丢失,因为每个经过训练的 LoRA 的组合权重 w w w i 都会降低。

-
(3)公式3出现的位置是背景的第二部分,用来描述专家混合MoE。MoE与标准的 Transformer 模型不同,每个 MoE 层都包含 N N N个独立的前馈网络{ E i E_{i} Ei} i = 0 N ^N_{i=0} i=0N作为专家,以及一个 α ( ⋅ ) \alpha(·) α(⋅)门控函数,它表示专家输出权重的概率分布建模,用来获取门控值 α ( E i ) \alpha(E_i) α(Ei), h h h是输入的隐藏表示, e i e_i ei表示 E i E_i Ei的可训练嵌入,该公式描述的是将 h h h路由到专家 E i E_i Ei的门控过程。

-
(4)公式4是公式3的进一步延伸, O O O表示MoE层的输出,通过累加专家权重乘专家输出最后再加上原本的隐藏输入token h h h最后得到输出 O O O。这里再加一个 h h h我浅显的理解是残差连接。

-
(5,6)公式5,6出现在文中第三章方法部分第二节“MIXTURE OF LORA EXPERTS”,该部分在讲述本文核心模型图,即上节模型解读的模型图,这两个公式为后面的模型讲解做铺垫,有Transformer基础的不用过多解释,就是Transformer的过程公式,对于公式5其中 x x x是输入, θ \theta θ是预训练模型参数,LN(·)表示归一化层, f A t t n f_{Attn} fAttn是注意力机制,再加上 x x x是进行残差连接;对于公式6表示进行注意力机制后的结果再输入前馈层 f F F N f_{FFN} fFFN,再加上公式5的结果 x θ ‘ x^`_{\theta} xθ‘(残差链接)得到输出 F θ ( x ) F_{\theta}(x) Fθ(x)。
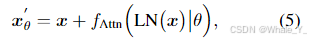
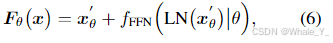
-
(7,8)公式7,8则是将5,6公式中的参数替换为LoRA的 θ \theta θ,记为 Δ θ \Delta\theta Δθ,其中{ Δ θ \Delta\theta Δθ} i = 0 N ^N_{i=0} i=0N, N N N表示训练后的 LoRA 候选数量,则每个LoRA的输出表示为 E Δ θ ( x ) E_{\Delta\theta}(x) EΔθ(x),其中 x ∈ R L × d x\in\mathbb{R}^{L \times d} x∈RL×d, L L L是序列长度, d d d是维度。
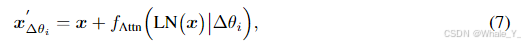

-
(9)公式9是串联(表示为 ⊕)和归一化(用于训练稳定性)LoRA输出的过程,串联后的结果 E Ω ( x ) ∈ R ξ E_\Omega(x)\in\mathbb{R}^\xi EΩ(x)∈Rξ,其中 ξ = N \xi = N ξ=N × \times × L L L × \times × d d d,⊕是串联操作。

-
(10)公式10是获取门控函数 G G G(公式11)的中间变量 ϵ \epsilon ϵ,且 ϵ ∈ R N \epsilon\in\mathbb{R}^N ϵ∈RN,其中 e ∈ R ξ × N e\in\mathbb{R}^{\xi \times N} e∈Rξ×N是门控函数G的可学习参数,Flatten是展平函数,由 e ∈ R ξ × N e\in\mathbb{R}^{\xi \times N} e∈Rξ×N和 ϵ ∈ R N \epsilon\in\mathbb{R}^N ϵ∈RN我们可知Flatten展平后为 R ξ × 1 \mathbb{R}^{\xi \times 1} Rξ×1,转置后为 R 1 × ξ \mathbb{R}^{1 \times \xi} R1×ξ,其相乘结果就是 ϵ ∈ R 1 × N \epsilon\in\mathbb{R}^{1 \times N} ϵ∈R1×N的。该公式的目的是将所有LoR输出转为 N N N维,即每个RoLA专家对应一维,以便公式11使用每一维的数据。
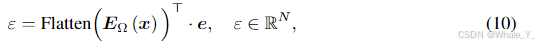
-
(11)公式11是获取 每个LoRA 的门值, ϵ i \epsilon_i ϵi对应第 i i i个LoRA的输出, r r r为温度标量也是可学习的,就是通过指数化后的单个值除以整体的值计算一个LoRA门值,即第 i i i个LoRA的权重。
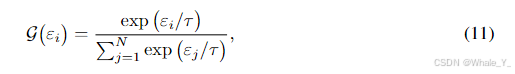
-
(12)公式12中门控函数 G G G的最终输出 E ~ Ω ( x ) \tilde{E}_{\Omega}(x) E~Ω(x)是通过将每个 LoRA 专家输出与相应的门控值相乘获得。
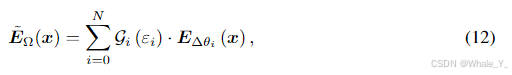
-
(13)公式13为MoLE的最终输出,即将门控函数的输出与预训练网络的输出相加得到。

-
(14,15)公式14提出在第三章的第三节,目的是设计训练目标,其中 L b a l a n c L_{balanc} Lbalanc为门控平衡损失,为何提出平衡损失?文中提到原因是:
观察到随着训练步骤数量的增加,门控函数的分布概率的平均熵逐渐减小,即门控函数趋于收敛到一个状态,其中它始终为早期表现良好的 LoRA 生成较大的权重,最终导致只有少数 LoRA 产生重大影响,而其他 LoRA 的特征丢失。
即要平衡每个LoRA专家的权重,而不让某些LoRA专家权重过大或过小,如何实现呢?使用累乘各个LoRA概率放入损失,当某个LoRA专家的权重过小时会造成损失较大,也就是说各个LoRA专家权重相对平衡时才有较低的损失。(举个例子,比如有两个LoRA专家,
q
q
q分别是0.9和0.1,那么
q
1
×
q
2
q^1 \times q^2
q1×q2就是0.09,而当两者为0.5时结果是0.25,0.25>0.09,所以相对平衡时累乘结果大,对数函数就大,取负结果就小,损失就小)
公式15则是对公式14中
q
(
i
)
q^{(i)}
q(i)的解释,其中
M
M
M表示放置门控函数的块的数量,
N
N
N表示 LoRA 的数量,此处设置
M
M
M的原因是文中对门控函数块的数量对模型好坏做了研究,我们可以发现当
M
M
M为1时,即一个单门控制下,公式15就变成了类似公式3一样的专家权重计算。
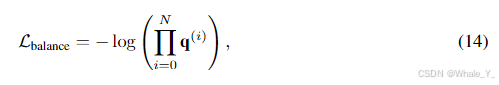
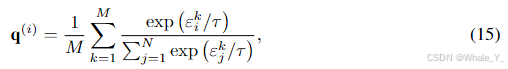
- (16)公式16是本文最后一个公式,其中
L
D
L_D
LD表示不同的领域特定训练目标,比如V&L领域或NLP领域,后者
L
B
a
l
a
n
c
e
L_Balance
LBalance则是上述公式14的平衡损失,
α
\alpha
α用于权重平衡的系数,两者相加构成总体训练目标。

实验结果与分析
实验在V&L领域和NLP领域分别进行实验。
- V&L领域。
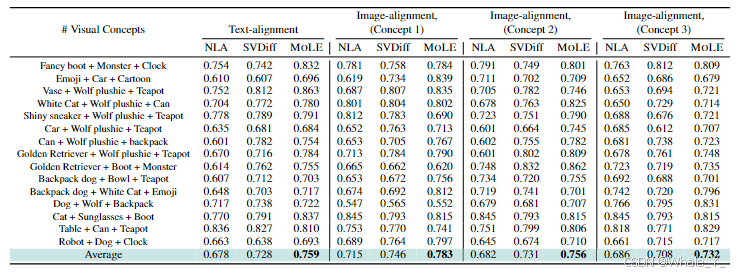
实验设置:将MOLE应用于多主题文本到图像生成任务,使用基于Stable DiffusionV2.1构建的生成器,将2到3个概念组合成一个新的多概念图像,通过组合三个单独训练的 LoRA 来进行实验,图像分辨率处理为512*512,并将学习率设置为1e-5,使用 DDPM 采样器,在每种情况下执行 50 步,并针对每个所需组合训练 400 次迭代,批次大小为 2, α \alpha α为0.5。
对比指标:采用CLIP对比图像相似性和图像文本相似性,与归一化线性算术组合(NLA)和SVDiff进行对比。
主要结果:文本对齐得分方面明显优于其他对比方法,与SVDiff相比平均提高了0.031,整体表明MOLE在准确捕获和描绘用户提供的图像的主题信息以及在单个图像中同时显示多个实体方面具有优越的能力。
- NLP领域。
实验设置:使用Flan-T5作为LLM,基于FLAN数据集创建了多个 LoRA,实验覆盖了Translation,Natural Language Inference (NLI),Struct to Text,Closed-Book QA和Big-Bench Hard (BBH)多个数据集的子任务,为每个所需的 LoRA 组合训练 800 次迭代,初始学习率为1e-5,批次大小为12, α \alpha α为0.5。
对比指标:与最先进的 LoRA 组合方法进行了比较:LoRAhub 和 PEMs。
主要结果:MOLE在五个不同的数据集上超越了最先进的 LoRA 组合方法,强调了MOLE在处理语言生成任务方面的有效性和多功能性。
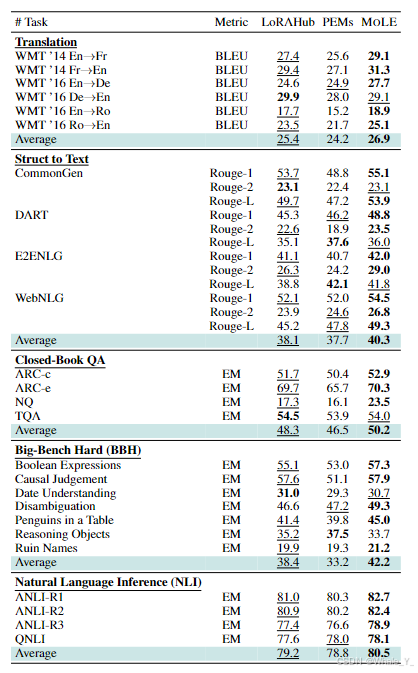
- 分析
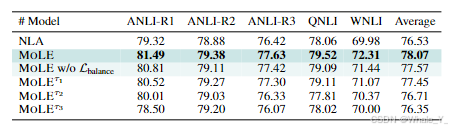
- 门控平衡损失和温控
r
r
r的影响
门控平衡损失 L b a l a n c L_{balanc} Lbalanc导致更加均匀的组合权重分布,这里的温控 r r r也是用来环节门控不平衡的问题,探究了随着 r r r增加其性能如何变化(温控 r r r可以理解为温度越高越活越越不稳定、随机)。下表结果表明了平衡损失 L b a l a n c L_{balanc} Lbalanc的有效性和随着 r r r增加模型性能下降,文中提及的原因是它限制了MOLE中动态LoRA的探索。(w/o表示without)
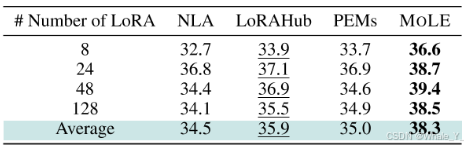
- LoRA数量的影响
实验探索了8、24、48、128数量的LoRA对实验结果的影响,发现在LoRA数量在48时表现优于其他数量,太少或太多都次优。
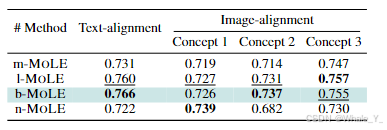
- 粗细粒度们的影响分析
为了检查不同粒度级别的门控函数的影响,在MOLE中划定了四个级别:矩阵级(MOLE,在参数矩阵级别进行门控)、层级、块级和网络级,分别缩写为mMOLE、l-MOLE、b-MOLE 和n-MOLE,中间粒度b-MOLE 和 l-MOLE,取得了最高的性能。 相反,最粗糙的级别,n-MOLE,它只涉及最少的可优化参数(整个网络的单个门控),表现出次优的结果。 此外,最精细的粒度,m-MOLE,表现不佳,可能是因为它过度控制干扰了 LoRA 参数中的固有关系。
- MOLE灵活性
MOLE可以实现LoRAs有效的组合,还可以选择性的mask特定的LoRA专家,并且MOLE可以自动调整而不需要更改内部参数。
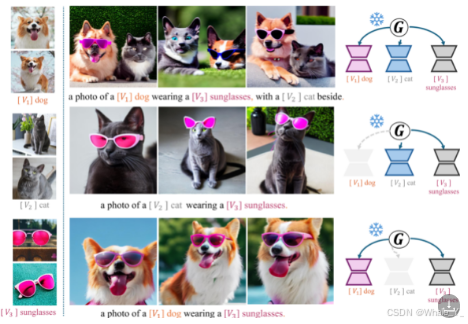
除上述分析外,文中还分析了“进一步与SOTA多概念生成方法进行比较”、“泛化到新的数据集”和“层次控制分析”,在此不对其进行特定分析了,详情请查看原文。
总结
- 引入了LoRA专家混合模型(MOLE),作为一种通用的动态方法,用于组合多个经过训练的LoRAs。 MOLE的关键创新在于其可学习的门控函数,该函数利用每一层多个LoRAs的输出,以确定组合权重,在自然语言处理和视觉与语言领域进行的全面评估表明,MOLE优于现有的LoRA组合方法。
- 局限性:当LoRAs的数量增加到非常大的值(例如,128)时,尽管MOLE表现出优异的性能,但所有LoRA组合方法的性能(包括MOLE)都会下降。 这表明MOLE在执行大规模LoRA组合时仍然面临挑战。 它也强调了研究更好的方法以有效地处理大规模LoRA组合的重要性。
解读到此结束,觉得对您有帮助的话欢迎关注、点赞、收藏和留言交流。

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









