



S-LoRA: Serving thousands of concurrent LoRA Adapters
这是斯坦福和UC Berkeley合作的论文(没错,又有大佬Ion Stoica),影响力非常广。主要设计了一种新的方案在一个GPU上同时支持多个lora adapters的并行执行。
摘要
"pretain-then-finetune"通常用于部署LLMs。Low Rank Adaption(LoRA)是一种参数高效的finetuning方法,经常用于将base model适应到多种任务中,从而产生大量从单一base model派生的LoRA adapters。我们观察到,这种范式在服务期间的batch inference中呈现出重大机遇。为了利用这些机会,我们提出了S-LoRA,一个为可扩展服务许多LoRA adapters而设计的系统。S-LoRA将所有adapters存储在main memory中,并将当前运行查询所使用的adapter提取到GPU memory中。为了有效使用GPU memory并减少碎片化,S-LoRA提出了Unified Paging。Unified Paging使用统一的memory pool来管理具有不同rank的动态adapters权重和具有不同序列长度的KV cache tensors。此外,S-LoRA采用了一种新颖的张量并行策略和高度优化的自定义CUDA内核,用于LoRA计算的异构批处理。总的来说,这些特性使S-LoRA能够在单个GPU或跨多个GPU上以很小的开销服务数千个LoRA adapters。与诸如HuggingFace PEFT和vLLM(具有对LoRA服务的简单支持)等最先进的库相比,S-LoRA可以将吞吐量提高多达4倍,并将服务的适配器数量增加几个数量级。因此,S-LoRA能够可扩展地服务许多特定任务的微调模型,并为大规模定制微调服务提供潜力。代码开源在https://github.com/S-LoRA/S-LoRA。
Contributions:
- Unified Paging:为了减少显存碎片和增加batch size,S-LoRA 引入了一个统一内存池。这个内存池通过一个统一页机制管理动态adapters的权重和KV cache tensors。
- Heterogenous Batching: 为了最小化latency的overhead,当batching不同rank的adapters时,S-LoRA 实现了高度优化的定制化CUDA kernels。这些kernels直接在非连续内存上运行,并与内存池设计保持一致,有助于 LoRA 的高效批量推理。
- S-LoRA TP:为了确保跨多个 GPU 的有效并行化,S-LoRA 引入了一种新颖的张量并行策略。 与基本模型相比,这种方法所增加的 LoRA 计算的通信成本最低。 这是通过在小的中间张量上调度通信并将大的中间张量与基本模型的通信融合来实现的。
2. Background
Low rank adapter(LoRA)(Hu et al., 2021)是一种高效的参数微调方法,旨在将预训练的LLMs适应到新任务中。LoRA背后的动机来自于在适应过程中模型更新的低内在维度。在训练阶段,LoRA冻结了预训练基础模型的权重,并在每一层添加了可训练的低秩矩阵。这种方法显著减少了可训练参数的数量和内存消耗。与全参数微调相比,LoRA通常可以将可训练参数的数量减少几个数量级(例如,10000倍),同时保持可比的准确性。对于推理阶段,原始论文建议将低秩矩阵与基础模型的权重合并。因此,在推理期间没有增加额外的开销,这与以前的适配器(如Houlsby et al., 2019)或诸如(Lester et al., 2021)的prompt tuning方法不同。

但是这个调整只适用于Q,K, V,以及自注意力模块中的输出投影矩阵,不包括feed-forward模块。
由于 LoRA 大大降低了训练和权重存储成本,因此被社区广泛采用,人们为预训练的LLMs和diffusion models创建了数十万个 LoRA adapters(Mangrulkar et al., 2022)。
2.1 Serving Large language models
LLM 的推理过程需要迭代自回归解码。 最初,模型执行前向传递以对prompt进行encoding。 接下来,它一次对输出一个token进行decoding。 顺序过程使decoding速度变慢。 由于每个token都关注其所有先前token的隐藏状态,因此存储所有先前token的隐藏状态变得至关重要。 该存储被称为“KV cache”。 这种机制增加了内存开销,并导致decoding过程的内存密集度大于计算密集度。
在online环境中,challenges变得更加明显,其中不同序列长度的请求动态到达。 为了适应这种动态传入请求,Orca(Yu et al., 2022)引入了一种细粒度、迭代级调度的方法。 Orca 不是在请求级别进行调度,而是在token级别进行批处理。 这种方法允许不断向当前运行的批次添加新请求,从而显着提高吞吐量。 vLLM(Kwon 等人,2023)使用 PagedAttention 进一步优化 Orca 的内存效率。 PagedAttention 采用操作系统中虚拟内存和分页的概念,以分页方式管理动态 KV 缓存张量的存储和访问。 这种方法有效地减少了碎片,有利于更大的批量大小和更高的吞吐量。
当服务超出单个 GPU 内存容量的超大型模型时,或者存在严格的延迟要求时,有必要跨多个 GPU 并行化模型。 人们提出了几种模型并行方法,例如张量并行(Shoeybi et al., 2019)、序列并行(Korthikanti et al., 2023)、管道并行(Huang et al., 2019)以及它们的组合(Narayanan et al., 2023)。 .,2021;郑等人,2022)。
3. Overview of S-LoRA
S-LoRA 包含新的三个主要组成部分。 在第 4 节中,我们介绍了批处理策略,该策略分解了基础模型和 LoRA 适配器之间的计算。 此外,我们还解决了请求调度的挑战,涵盖适配器集群和准入控制等方面。 跨并发适配器进行批处理的能力给内存管理带来了新的挑战。 在第 5 节中,我们将 PagedAttention(Kwon 等人,2023)推广到支持动态加载 LoRA 适配器的 Unfied Paging。 该方法使用统一的内存池以分页方式存储KV缓存和适配器权重,可以减少碎片并平衡KV缓存和适配器权重的动态变化大小。 最后,在第 6 节中,我们介绍了新的张量并行策略,该策略使我们能够有效地解耦基础模型和 LoRA 适配器。
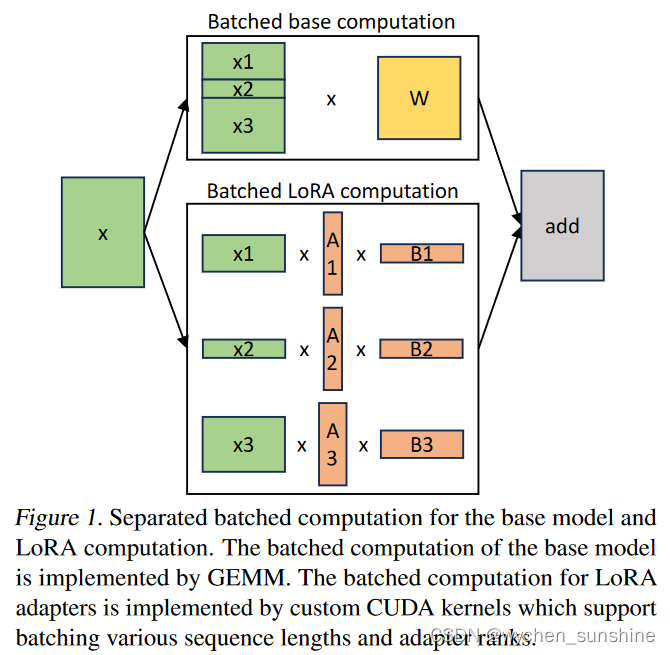
4. Batching and Scheduling
4.1 Batching
我们的Batching策略目标是支持多个LoRA adapters的在线和高并发运行。
对于单个Adapter,Hu等2021 提出的方法是merge adapters weights 到base model的weights,生成一个新的model。这种方式的优点是在推理时没有额外的adapter开销,当新的model与base model参数量相同时。事实上,这也是原始LoRA工作的主要特征。
但是当有多个adapters时,将权重合并到base model 中会导致多个权重副本并错过批处理机会。 直接合并模型需要维护完整语言模型的许多副本。 在最初的 LoRA 论文中,作者提出动态添加和减去 LoRA 权重,以便在不增加内存开销的情况下为多个模型提供服务。 然而,这种方法不支持在单独的 LoRA 适配器上进行并发推理,因此限制了批处理机会。
在本文中,我们表明,将 LoRA 适配器合并到base model中对于多 LoRA 高吞吐量服务设置来说效率很低。 相反,我们建议即时计算 LoRA 计算 xAB,如方程式 2 所示。 这避免了权重重复,并支持对成本更高的 xW 操作进行批处理。 但这种方法也增加了计算开销。 然而,由于 xAB 的成本远低于 xW,并且跨不同适配器批处理 xW 可以节省大量成本,因此我们表明节省的成本远远超过了额外的开销。
不幸的是,使用现有 BLAS 库中的批处理 GEMM 内核直接实现基本模型和单个 LoRA 适配器的因子计算将需要大量填充,并导致硬件利用率不佳。 这是因为序列长度和adapter rak的异构性。
在 S-LoRA 中,我们对base model的计算进行batch,然后使用自定义 CUDA kernel分别为所有adapters执行附加的 xAB。 图 1 说明了这一过程。我们不是简单地使用填充并使用 BLAS 库中的批处理 GEMM 内核进行 LoRA 计算,而是实现了自定义 CUDA 内核,以便在没有填充的情况下实现更高效的计算。 在第 5.3 节中,我们讨论实现细节。
虽然如果我们将 LoRA adapters存储在main memory中,LoRA adapters的数量可能会很大,但当前运行的batch所需的 LoRA adapters的数量是可以管理的,因为batch大小受到 GPU memory的限制。 为了利用这一点,我们将所有 LoRA adapters存储在main memory中,并在运行该批次的推理时仅将当前运行batch所需的 LoRA 适配器获取到 GPU RAM。 在这种情况下,可以提供服务的最大adapters数量受主内存大小的限制。 这个过程如图 2 所示。为了实现高吞吐量服务,我们采用 Orca 的迭代级调度批处理策略(Yu et al., 2022)。 在这种方法中,请求在token级别进行调度。 如果空间可用,我们会立即将新请求合并到正在运行的批次中。 一旦达到生成token的最大数量或满足其他停止条件,请求将退出batch。 此过程减少了 GPU memroy使用量,但引入了新的内存管理挑战。 在第 5 节中,我们将讨论有效管理内存的技术。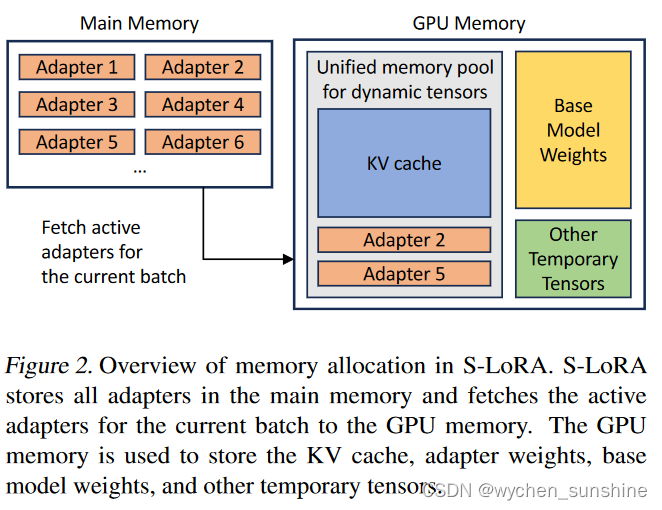
4.2 Adapter Clustering
为了提高批量处理效率,一种潜在的策略是减少运行批次中活跃adpters的数量。通过使用较少的adapters,有机会将更多的内存分配给KV缓存,这反过来又可以促进更大的批量大小。考虑到GPU的常见memory容量,在解码时它们经常被低估。因此,增加batch size可以导致更高的吞吐量**。减少运行批次中适配器数量的一个直接方法是优先处理使用相同适配器的请求,我们称之为“adapter clustering”策略**。然而,adapters clustering也有其自身的一系列权衡。例如,它可能会损害平均延迟或adapters之间的公平性。我们在附录A中提供了一个消融研究,以说明吞吐量和延迟如何根据聚类大小而变化。
4.3 Admission Control
在S-LoRA中,我们还应用了一种准入控制策略,以在流量高于服务系统容量时维持良好的表现。服务系统通常以服务水平目标(SLO)为特征,该目标指定了处理请求所需的期望延迟。如果服务系统有固定的容量,它必须实施一种准入控制机制,如果系统无法满足其SLO,则拒绝请求。否则,如果不拒绝任何请求,并且进入的请求数量长时间大于系统容量,服务系统必将违反SLO。我们在S-LoRA中实现了一种模拟准入控制的中止策略,称为早期中止策略。直观上,我们估计了我们可以在SLO内服务的最后请求集,然后按照到达时间的顺序为它们服务。更多的实现细节和数学论证将推迟到附录B中讨论。
5. Memory Management
与同时服务单个基础模型相比,同时服务多个LoRA adapters带来了新的内存管理挑战。为了支持许多adapters,S-LoRA将它们存储在主存储器中,并动态地将当前运行批次所需的adapters权重加载到GPU RAM中。在这个过程中,存在两个明显的挑战。第一个是内存碎片化,这是由于动态加载和卸载各种大小的适配器权重造成的。第二个是适配器加载和卸载引入的延迟开销。为了有效地应对这些挑战,我们提出了统一分页,并通过对适配器权重进行预取来使I/O操作与计算重叠。
5.1 Unified Paging
了解适配器权重的性质对于优化内存使用至关重要。 我们的主要观察是,这些动态适配器权重在几个方面类似于动态 KV 缓存:
- Variable sizes and operations: 正如 KV 缓存大小随序列长度波动一样,活动适配器的排名也可以取决于与每个请求关联的适配器的选择。 KV 缓存在请求到达时分配,并在请求完成后释放。 类似地,适配器权重会随着每个请求而加载和清除。 如果管理不当,这种可变性可能会导致碎片。
- Dimensionality:层中请求的 KV 缓存张量的形状为 (S, H),其中 S 表示序列长度,H 表示隐藏维度。 同时,LoRA权重的形状为(R,H),其中R代表秩,H代表隐藏维度。 两者共享一个维度大小 H,可用于减少碎片。
受这些相似之处的启发,我们将 PagedAttention(Kwon 等人,2023)的想法扩展到统一分页,除了 KV 缓存之外,它还管理适配器权重。 统一分页使用统一的内存池来共同管理KV缓存和适配器权重。 为了实现这一点,我们首先为内存池静态分配一个大缓冲区。 该缓冲区使用除基本模型权重和临时激活张量占用的空间之外的所有可用空间。 KV 缓存和适配器权重均以分页方式存储在该内存池中,每个页面对应一个 H 向量。因此,序列长度为 S 的 KV 缓存张量会占用 S 个页面,而 LoRA 权重张量为 排名R占用R页。 图 3 说明了我们的内存池的布局,其中 KV 缓存和适配器权重以交错且不连续的方式存储。 这种方法显着减少了碎片,确保各种等级的适配器权重能够以结构化和系统的方式与动态KV缓存共存。
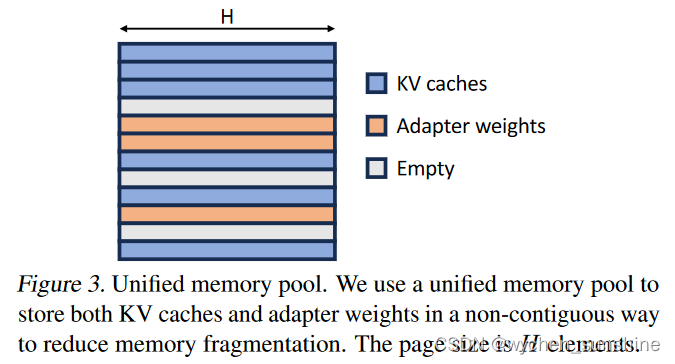
5.2 Prefetching and Overlapping
尽管统一内存池减少了碎片,但加载和卸载产生的 I/O 开销仍然是一个问题,尤其是在处理大量或大型适配器时。 等待加载这些适配器所带来的延迟可能会影响系统的效率。
为了主动解决这个问题,我们引入了动态预测机制。 在运行当前的解码批次时,我们根据当前的等待队列预测下一个批次所需的适配器。 这种预测允许我们预取并将它们存储在可用内存中。 这种前瞻性策略使下一批所需的大部分适配器在运行之前就已就位,从而减少了适配器交换的 I/O 时间。
5.3 Custom Kernels for heterogeneous LoRA batching on Non-Contiguous Memory
由于统一内存池的设计,适配器权重存储在非连续内存中。 为了在此设计下高效运行计算,我们实现了自定义 CUDA 内核,该内核支持在非连续内存布局中以不同的等级和序列长度进行批处理 LoRA 计算。 在预填充阶段,内核处理一系列token并从内存池中收集不同等级的适配器权重。 我们将此内核称为多尺寸批量收集矩阵-矩阵乘法 (MBGMM)。 它在 Triton (Tillet et al., 2019) 中通过平铺实现。 在解码阶段,内核处理单个令牌并从内存池中收集不同等级的适配器权重。 我们将此内核称为多尺寸批量收集矩阵向量乘法 (MBGMV)。 它是从 Punica (Chen, 2023) 修改而来的,以支持批量中的多个等级和更细粒度的内存收集。
6. Tensor pallelism
我们为批量 LoRA 推理设计了新颖的张量并行策略,以支持大型transformer model的多 GPU 推理。 张量并行是最广泛使用的并行方法,因为它的单程序多数据模式简化了其实现以及与现有系统的集成。 在服务大型模型时,张量并行性可以减少每个 GPU 的内存使用量和延迟。 在我们的设置中,额外的 LoRA 适配器引入了新的权重矩阵和矩阵乘法,这需要针对这些添加的项采用新的分区策略。
6.1 Partition Strategy
由于基础模型使用 Megatron-LM 张量并行策略(Shoeybi et al., 2019),我们的方法旨在将添加的 LoRA 计算的输入和输出的分区策略与基础模型的输入和输出的分区策略保持一致。 这样我们就可以通过避免不必要的通信、融合一些通信来最大程度地降低通信成本。
我们使用前馈模块(2 层 MLP)来说明我们的分区策略。 稍后我们将解释如何将该策略轻松地应用于自注意力层。 如图 4 所示,上框说明了基本模型的 Megatron-LM 分区策略:第一个权重矩阵 (W 1) 进行列分区,第二个权重矩阵 (W 2) 进行行分区。 需要进行全归约通信来累积来自分布式设备的部分总和。
下框说明了添加的 LoRA 计算的分区策略。 第一权重矩阵(W 1 )的适配器的矩阵A1和B1是列分区的。 全收集操作用于收集中间结果。 第二权重(W2)的适配器的矩阵A2和B2分别是行分区和列分区的。 all-reduce 操作用于对中间结果求和。 最后,将 LoRA 计算的结果添加到基本模型的结果中(加 2)。 单个全归约操作足以累积最终结果。 值得注意的是,我们本质上是将 matmul 4 的全收集操作与最终的全归约融合在一起。 据我们所知,这种并行化策略之前还没有被研究过。
接下来,我们讨论将策略从 2 层 MLP 调整到 self-attention 层。 与 Megatron-LM 策略类似,我们划分自注意力层的头部维度。 在我们的示例中,查询键值投影权重矩阵可以被视为 W 1 ,输出投影权重矩阵在我们的示例中可以被视为 W 2 。
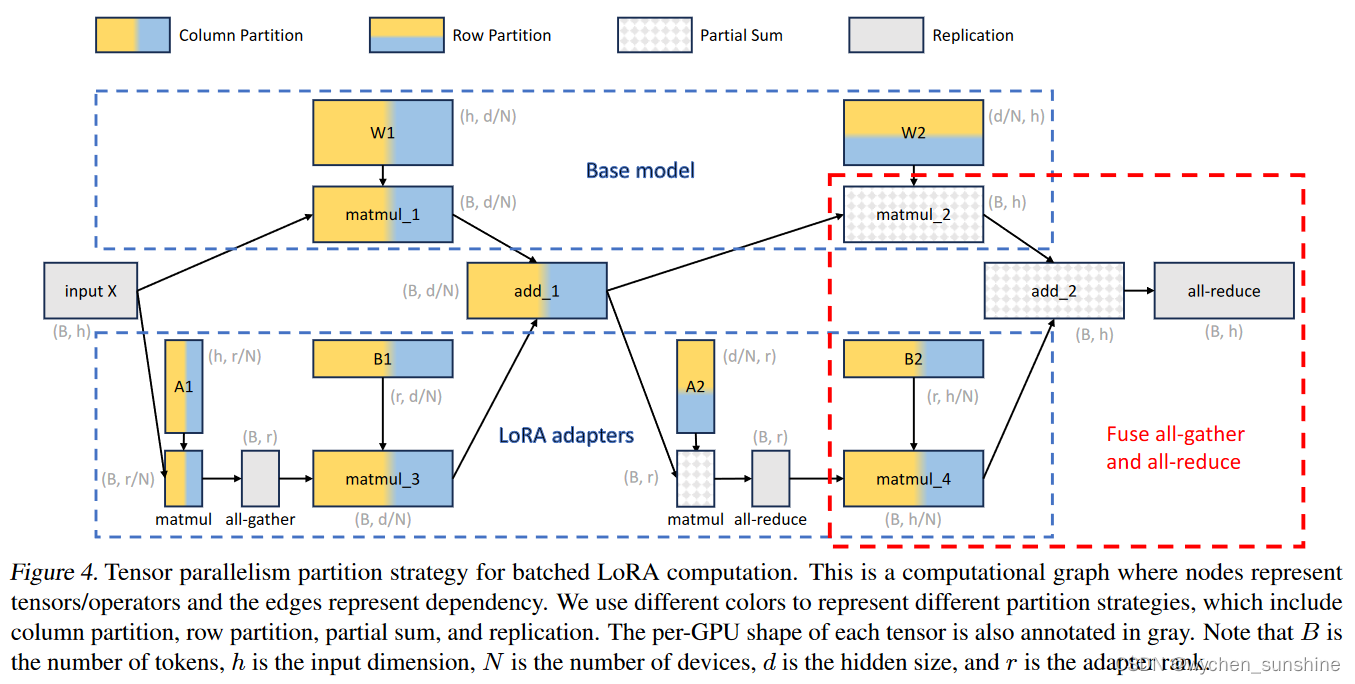
6.2 Communication and Memory Cost Analysis
详细可以参考原论文。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











