







文章目录
文章目录
- 文章目录
- 基础
- 集合
- JVM
- 并发线程
- Web
- Spring
- SpringBoot
- 数据库
- Redis
- 设计一个RPC
- 常考算法
基础
JDK、JDK、JRE的关系

Java基本数据类型
- 基本数据类型:整型(6种)、字符型(1种)、布尔型(1种)
- 引用类型:数组、字符串、自定义类

基本类型与包装类型区别
- 默认值:成员变量包装类型不赋值就是 null ,而基本类型有默认值且不是 null。
- 泛型:包装类型可用于泛型,而基本类型不可以。
- 存放位置:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
- 内存大小:相比于对象类型, 基本数据类型占用的空间非常小。
final作用
| final修饰 | 解释 |
|---|---|
| 类 | 不可以被继承 |
| 方法 | 不能被重写 |
| 变量 | 不能被改变,不可变值的是变量的引用,指向的内容可以改变 |
final finally finalize
| 区别 | 描述 |
|---|---|
| final | 如上解释 |
| finally | 一般作用在try-catch代码块中,一般用来存放一些关闭资源的代码 |
| finalize | 属于Object类的一个方法,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。 |
String、StringBuffer、StringBuilder
| String | StringBuffer | StringBuilder | |
|---|---|---|---|
| 可变性 | 不可变 | 可变 | 可变 |
| 安全性 | 安全,因为final | 安全,因为加锁 | 不安全 |
| 适用 | 少量操作 | 多线程+大量操作 | 单线程+大量操作 |
Int和Integer的区别
// 问题1:Integer和int比较
Integer a = new Integer(3);
Integer b = 3;
System.out.println(a == b);// false,引用类型和值类型不能比较
Integer d = new Integer(3);
System.out.println(a == d); // false,两个引用类型用==不能比较
int c = 3;
System.out.println(c == d); // true,Integer遇到int比较,Integer会拆箱成int做值比较
System.out.println("-------");
Integer底层提前缓存好了[-128,127]的值,所以创建两个范围的对象时,地址是一样的
// 问题2:Integer值返回缓存
Integer f1 = 100;
Integer f2 = 100;
System.out.println(f1 == f2);// true
Integer f3 = 129;
Integer f4 = 129;
System.out.println(f3 == f4);
System.out.println("-------");// false
原因:当一个Integer对象赋给int值的使用,调用Integer的valueOf方法
public static Integer valueOf(int i) {
// i在[-128,127]时,就会自动去引用常量池中的Integer对象,不会new新的
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Equals、==、hashCode区别
| == | equals | hashCode |
|---|---|---|
| 基本数据类型用,比较的是首地址值 | 引用类型用,比较是内容值 | 对象在内存中的地址,算出对象的哈希码值,并将其返回,重写equals方法,必须重写hashCode,因为集合类是通过HashCode判断重复的 |
序列化类中有一个不可序列化的对象
给该类设置关键字transiient告诉JDK不可被序列化
元注解
Java中使用返回值类型@interface表示该类是一个注解配置类,注解配置不能使用class、interface、abstract修饰
// 自定义注解,以下只是简单的演示。实际开发注解还需要一个注解处理器,自行百度学习
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.CLASS)
@Documented
public @interface FruitProvider {
public int id() default -1;
public String name() default "";
public String address() default "";
}
public class Apple {
// 使用自定义注解
@FruitProvider(id = 1, name = "红富士", address = "北京市")
private String appleProvider;
public String getAppleProvider() {
return appleProvider;
}
public void setAppleProvider(String appleProvider) {
this.appleProvider = appleProvider;
}
}
四大元注解:目标、保留、文档、继承
@Target:说明注解对象修饰范围

@Retention:该注解保留时长
- source :在源文件中有效, 源文件中就保留
- class:字节码文件中有效, 即在Class文件中被保留
- runtime:在运行时有效,即在运行时被保留
@Documented:表示被Javadoc文档工具化,只是一个标记注解,没有成员
@Inherited:表示该类型是被继承的,表名该注解类可以作用于其子类
Java的面向对象
| 名称 | 概念 |
|---|---|
| 封装 | 将事物封装成一个类,减少耦合,隐藏细节。保留特定接口和外部联系 |
| 继承 | 从已知的类中派生出一个新的类,可以通过覆盖/重写增强功能 |
| 多态 | 本质是一个程序中存在多个同名的不同方法 |
封装:将事物封装成一个类,减少耦合,隐藏细节。保留特定接口和外部联系
继承:从已知的类中派生出一个新的类,可以通过覆盖/重写增强功能
- Java中类的初始化顺序:
- 父类静态成员变量、静态代码块;子类静态成员变量、静态代码块
- 父类普通成员变量和代码块,再执行父类构造方法
- 子类普通成员变量和代码块,再执行父类构造方法
- 子类特点:
- 父类非private的属性和方法
- 添加自己的方法和属性,对父类进行扩展
- 重新定义父类的方法=方法的覆盖/重写
多态:本质是一个程序中存在多个同名的不同方法
-
子类的覆盖实现
-
方法的重载实现
-
子类作为父类对象使用
什么方法重载、方法重写?
重载(overload):一个类中存在多个同名的不同方法,这些方法的参数个数、顺序和类型不同均可以构成方法重载
重写(override):子类对父类非私有方法的重新编写,涉及写的就会有子父类
如果只有方法返回值不同,可以构成重载吗?
不可以,因为我们调用某个方法,并不关心返回值。编译器根据方法名和参数无法确定我们调用的是那个方法。
Java中有goto关键字吗
goto和const是Java中的保留字,现在未使用,未使用的原因是保证程序的可读性,并且避免使用beak+lebel带标签的语句
| 跳出循环方式1 | 跳出循环方式2 | 跳出循环方式3 |
|---|---|---|
| break+label,不推荐使用 | flag+break | throw new 抛出异常 |
抽象类和接口
- 接口是抽象类的变体,「接口中所有的方法都是抽象的」。而抽象类是声明方法的存在而不去实现它的类。
- 接口可以多继承,抽象类不行。
- 接口定义方法,不能实现,默认是 「public abstract」,而抽象类可以实现部分方法。
- 接口中基本数据类型为 「public static final」 并且需要给出初始值,而抽类象不是的。
接口和抽象类该如何选择?
当我们仅仅只需要定义一些抽象方法而不需要额外的具体方法/变量的时候,用接口;反之,考虑抽象类
接口的普通方法、default修饰方法:
public interface MyInterface {
// 接口的普通方法只能等待实现类实现,不能具体定义
void test();
// 但是JDK8以后,接口可以default声明,然后具体定义
default void say(String message) {
System.out.println("hello:"+message);
}
}
public class MyInterfaceImpl implements MyInterface {
// 实现接口里的抽象方法
@Override
public void test() {
System.out.println("test被执行");
}
// 当然也可以重写say方法
public static void main(String[] args) {
MyInterfaceImpl client = new MyInterfaceImpl();
client.test();
client.say("World");
}
}
执行结果:
test被执行
hello:World
如果实现类实现了两个接口,两个接口都有相同的(default)默认方法名,那么该方法重写会报错
解决办法:
- 实现类重写多个多个接口的默认方法
- 手动指定重写哪个接口的默认方法
public interface MyInterface {
void test();
default void say(String message) {
System.out.println("hello:"+message);
}
}
public interface MyInterface1 {
default void say(String message) {
System.out.println("hello1:" + message);
}
}
public class MyInterfaceImpl1 implements MyInterface, MyInterface1 {
@Override
public void test() {
System.out.println("test是普通方法被重写");
}
@Override
public void say(String message) {
// 方法一:System.out.println("实现类重写多个接口相同的默认方法:" + message);
// 方法二:指定重写哪个接口的默认方法
MyInterface.super.say(message);
}
public static void main(String[] args) {
MyInterfaceImpl1 client = new MyInterfaceImpl1();
client.say("好的");
}
}
执行结果:
实现类重写多个接口相同的默认方法:hello+好的
浅拷贝和深拷贝
| 浅拷贝 | 深拷贝 |
|---|---|
| 被复制的对象的所有变量都含有与原来对象相同的值,对拷贝后对象的引用依然指向原来的对象 | 不仅复制对象的所有非引用成员变量值,还要为引用类型的成员变量创建新的实例,并且初始化为形式参数实例值 |
创建对象的方式
| 创建对象方式 | 是否调用构造器 |
|---|---|
| new + 类名 | 是 |
| Class.newInstance | 是 |
| Constructor.newInstance | 是 |
| Clone | 否 |
| 反序列化 | 否 |
值传递和引用传递
值传递:传递是一个对象副本,即使副本改变,也不会影响原对象
引用传递:传递不是实际的对象,而是对象的引用。因此,外部对引用对象的改变会反映到所有的对象上
public class Test {
public static void main(String[] args) {
int a = 1;
// 基本数据类型:值传递,原值不会变
change(a);
System.out.println(a);
}
private static void change(int num) {
num++;
}
}
public class Test1 {
public static void main(String[] args) {
// 以下2个是引用传递,会改变原值
StringBuilder hello1 = new StringBuilder("hello1");
StringBuffer hello2 = new StringBuffer("hello2");
// String存放在常量池,虽然是引用传递,但不会改变原值
String hello3 = new String("hello3");
change1(hello1);
change2(hello2);
change3(hello3);
System.out.println(hello1);
System.out.println(hello2);
System.out.println(hello3);
}
private static void change3(String str) {
str += " world";
}
private static void change1(StringBuilder str) {
str.append(" world");
}
private static void change2(StringBuffer str) {
str.append(" world");
}
}
public class Test3 {
public static void main(String[] args) {
StringBuffer hello = new StringBuffer("hello");
System.out.println("before:" + hello);
changeData(hello);
// 前后值:都没有发生改变
// 因为changeData中str形参重新执行了str1,与原值hello无关了
System.out.println("after:" + hello);
}
private static void changeData(StringBuffer str) {
StringBuffer str1 = new StringBuffer("Hi");
str = str1;
str1.append("world");
}
}
public class PassTest {
public static void main(String[] args) {
int i = 1;
String str = "hello";
Integer num = 200;
int[] arr = {1, 2, 3, 4, 5};
MyData my = new MyData();
change(i, str, num, arr, my);
/*
结果:传值还是传引用?
i = 1 传值。基本数据类型不会变
str = hello 传常量池地址。字符串不变
num = 200,传堆中的地址。原包装类不变,和字符串一样
arr = [2, 2, 3, 4, 5] 传堆中数组的首地址。发生了改变
my.a = 11,传堆中地址,资源类变量发生改变。资源类中的变量,会在堆中生成一个实例
*/
System.out.println("i = " + i);
System.out.println("str = " + str);
System.out.println("num = " + num);
System.out.println("arr = " + Arrays.toString(arr));
System.out.println("my.a = " + my.a);
}
public static void change(int j, String s, Integer num, int[] arr, MyData myData) {
j += 1;
s += "world";
num += 1;
arr[0] += 1;
myData.a += 1;
}
}
class MyData {
int a = 10;
}
结果:
- 基本数据类型是值传递,不会改变原值
- String和包装类是引用传递,但不会改变原值,因为形参指向了另一个新生成的对象,原值不变
- 数组和自定义类时引用传递,会改变原值,因为数组是连续地址空间,没有在堆中新生成实例;自定义类中的成员变量分配在堆中,也没有重新生成实例
i = 1 // 传值。基本数据类型不会变
str = hello // 传常量池地址。字符串不变
num = 200 // 传堆中的地址。原包装类不变,和字符串一样
arr = [2, 2, 3, 4, 5]// 传堆中数组的首地址。发生了改变
my.a = 11// 传堆中地址,资源类变量发生改变。资源类中的变量,会在堆中生成一个实例
权限修饰符
| 作用域 | 当前类 | 同一包 | 子孙类 | 其他包 |
|---|---|---|---|---|
| public | 可以 | 可以 | 可以 | 可以 |
| protected | 可以 | 可以 | 可以 | 不可以 |
| default | 可以 | 可以 | 不可以 | 不可以 |
| private | 可以 | 不可以 | 不可以 | 不可以 |
反射机制
反射优缺点
| 反射优点 | 反射缺点 | 反射使用场景 |
|---|---|---|
| 装载到JVM中得的信息,动态获取类的属性方法等信息,提高语言灵活性和扩展性 | 性能较差,速度低于直接运行 | Spring等框架 |
| 提高代码复用率 | 程序的可维护性降低 | 动态代理 |
获取字节码
| 方式1 | 方式2 | 方式3 |
|---|---|---|
| 类名.class | 对象名.getClass() | Class.forName(classPath) |
public class User {
String username;
String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", password='" + password + '\'' +
'}';
}
}
public class ThreeClassGetDemo {
public static void main(String[] args) throws ClassNotFoundException {
// 方式一:类.class
Class<Integer> intClass = int.class;
// 方式二:对象.getClass()
User user = new User();
Class<? extends User> userClass = user.getClass();
// 方式三:Class.forName(类名)
String ClassName = "基础.反射.User";
Class<?> userClass1 = Class.forName(ClassName);
}
}
public class UserClassDemo {
public static void main(String[] args) {
String className = "基础.反射.User";
try {
// 通过反射获取userClass
Class<?> userClassByForName = Class.forName(className);
// 获取构造器
Constructor<?> constructor = userClassByForName.getConstructor();
// 生成user实例
User user = (User) constructor.newInstance();
user.setUsername("张三");
user.setPassword("123");
System.out.println(user);
// 反射来修改成员变量
Class<? extends User> userClassByuser = user.getClass();
userClassByuser.getDeclaredField("username").set(user, "张三1");
userClassByuser.getDeclaredField("password").set(user, "456");
// 反射修改方法
Method setUsername = userClassByuser.getMethod("setUsername", String.class);
setUsername.invoke(user, "张三2");
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
}
}
}
打印结果:
User{username='张三', password='123'}
User{username='张三2', password='456'}
获取构造器等
| 获取构造器 | 获取成员变量 | 获取成员方法 | |
|---|---|---|---|
| 非私有 | getConstructor(类型.class) | getMethod(名, 参数.class); | getDeclaredField(“id”); |
| 私有 | getDeclaredConstructor(类型.class)和setAccessible(true) | getDeclaredMethod(名, 参数.class);setAccessible(true) | getDeclaredField(“id”);setAccessible(true) |
定义测试的User:看到原类的构造器、成员属性、方法,想着怎么使用反射生成
package reflect;
public class User {
private int id=1;
private String name="张三";
private static Date date;
public User() {
}
public User(int id) {
this.id = id;
}
private User(String name) {
this.name = name;
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public void fun1() {
System.out.println("无参的fun1被调用");
}
public void fun2(int id) {
System.out.println("fun2:" + id);
}
public void fun3(int id, String s) {
System.out.println("fun3:" + id + "," + s);
}
private void fun4(Date date) {
System.out.println("fun4:" + date);
}
public static void fun5() {
System.out.println("fun5");
}
public static void fun6(String[] args) {
System.out.println(args.length);
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static Date getDate() {
return date;
}
public static void setDate(Date date) {
User.date = date;
}
}
public class Demo1 {
/**
* 获取非私有构造器
*/
@Test
public void test2() throws Exception {
Class<?> userClazz = Class.forName("reflect.User");
Constructor<?> c1 = userClazz.getConstructor();
Constructor<?> c2 = userClazz.getConstructor(int.class);
Constructor<?> c3 = userClazz.getConstructor(int.class, String.class);
User user = (User) c3.newInstance(1, "A");
System.out.println(user);
}
/**
* 获取私有构造器
*/
@Test
public void test3() throws Exception {
Class<?> userClazz = Class.forName("reflect.User");
// 私有需要declared修饰
Constructor<?> c = userClazz.getDeclaredConstructor(String.class);
// setAccessible设置暴露破解
c.setAccessible(true);
User user = (User) c.newInstance("A");
System.out.println(user);
}
/**
* 获取所有构造器:私有和非私有
*/
@Test
public void test4() throws Exception {
Class<?> userClazz = Class.forName("reflect.User");
Constructor<?>[] constructors = userClazz.getDeclaredConstructors();
for (Constructor c : constructors) {
System.out.println(c);
}
}
}
特殊情况:因为1.4是将字符数组分开作为小个体,String[]作为方法参数需要(Object)强转/new Object[]{包装}
public class Demo2 {
/**
* 获取非私有的成员方法
*/
@Test
public void test1() throws Exception {
Class<?> claszz = Class.forName("reflect.User");
User user = (User) claszz.newInstance();
Method fun1 = claszz.getMethod("fun1", null);
fun1.invoke(user, null);
Method fun2 = claszz.getMethod("fun2", int.class);
fun2.invoke(user, 1);
Method fun3 = claszz.getMethod("fun3", int.class, String.class);
fun3.invoke(user, 1, "A");
}
/**
* 获得私有方法
*/
@Test
public void test2() throws Exception {
Class<?> claszz = Class.forName("reflect.User");
User user = (User) claszz.newInstance();
// declared修饰private
Method fun4 = claszz.getDeclaredMethod("fun4", Date.class);
// setAccessible设置暴露破解
fun4.setAccessible(true);
fun4.invoke(user, new Date());
}
/**
* 获得无数组参数的静态方法
*/
@Test
public void test3() throws Exception {
Class<?> claszz = Class.forName("reflect.User");
Method fun5 = claszz.getDeclaredMethod("fun5");
fun5.invoke(null);
}
/**
* 特殊情况:获得String数组参数的静态方法
*/
@Test
public void test4() throws Exception {
Class<?> claszz = Class.forName("reflect.User");
Method fun6 = claszz.getDeclaredMethod("fun6", String[].class);
// fun6.invoke(null, new String[]{"1","2"}); 是要报错的,因为JDK4是把字符数组当做一个个对象解析
// 以下两种方式解决:
fun6.invoke(null, (Object) new String[]{"1", "2"});
fun6.invoke(null, new Object[]{new String[]{"1", "2"}});
}
}
一般来说成员属性都是私有的:getDeclaredField(setAccessible)后set值
public class Demo3 {
/**
* 获取非静态的私有成员变量
*/
@Test
public void test1() throws Exception {
Class<?> userClass = Class.forName("bean.User");
User user = (User) userClass.newInstance();
Field id = userClass.getDeclaredField("id");
id.setAccessible(true);
id.set(user, 2);
Field name = userClass.getDeclaredField("name");
name.setAccessible(true);
name.set(user, "李四");
System.out.println(user);
}
/**
* 获取静态成员变量
*/
@Test
public void test2() throws Exception {
Class<?> userClass = Class.forName("bean.User");
Field date = userClass.getDeclaredField("date");
date.setAccessible(true);
date.set(null, new Date());
System.out.println("User的Date:" + User.getDate());
}
}
String.intern问题
public class StringQuestion {
/*
intern:返回值一个字符串,内容与此字符串相同,但一定取自具有唯一字符串的池
*/
public static void main(String[] args) {
String str1 = new StringBuilder("58").append("同城").toString();
System.out.println(str1);
System.out.println(str1.intern());
System.out.println(str1 == str1.intern());
System.out.println("-----------");
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2);
System.out.println(str2.intern());
System.out.println(str2 == str2.intern());
}
}
58同城
58同城
true
-----------
java
java
false
第一个是true,第二个为什么是false?
因为JDK初始化sun.misc.Version会在常量池自动生成一个“Java”,与剩余生成的”Java“地址肯定不一样。其余字符串都是用户创建才会在常量池生成
public class Version {
private static final String launcher_name = "java";
private static final String java_version = "1.8.0_271";
private static final String java_runtime_name = "Java(TM) SE Runtime Environment";
private static final String java_profile_name = "";
...
}
异常分类
异常的概念:异常指在方法不能按照 常方式 ,可以通过抛出异常的方式退出 该方法,在异常中封装了方法执行 程中的错误信息及原因 调用 该异 常后可根据务的情况选择处理该异常或者继续抛出。
| 异常分类 | 概述 |
|---|---|
| Error | Java 程序运行错误 ,如果程序在启动时出现 Error 则启 动失败;如果程序在运行过程中出现 Error ,则系统将退出进程 |
| Exception | Java 程序运行异常,即运行中的程序发生了人们不期望发生的情况,可以被Java异常机制处理 |
| Exception分类 | 解释 | 常见 |
|---|---|---|
| RuntimeException | Java 虚拟机正常运行期间抛出的异常 | NullPointerException、ClassCastException ArraylndexOutOfBundsException |
| CheckedException | 编译阶段 Java 编译器会检查 CheckedException 异常井强调捕获 | IO Exception、SQLExcption、ClassNotFoundException |


捕获异常
public class ThrowException {
// 抛出异常的3种方式
// 1.throw:获取方法中的异常,throw 后面的语句块将无法被执行(finally除外)
private static void getThrow() {
String str = "str";
int index = 10;
if (index > str.length()) {
throw new StringIndexOutOfBoundsException("index > str.length");
} else {
System.out.println(str);
}
}
// 2.throws作用在方法上
private static int getThrows(int a, int b) throws Exception {
return a / b;
}
// 3.tryCatch包裹
private static void getTryCatch() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("最后必须会执行");
}
}
}
内部类
| 内部类 | 解释 |
|---|---|
| 静态内部类 | 可以访问外部类的静态变量和方法 |
| 成员内部类 | 非静态内部类,不能定义静态方法和变量(final除外) |
| 局部内部类 | 类中方法中定义的一个类 |
| 匿名内部类 | 继承一个父类或者实现一个接口的方式直接定义并使用的类 |
public class Outer {
private void test(final int i) {
new Service() {
public void method() {
for (int j = 0; j < i; j++) {
System.out.println("匿名内部类" );
}
}
}.method();
}
}
//匿名内部类必须继承或实现一个已有的接口
interface Service{
void method();
}
泛型
泛型:「把类型明确的工作推迟到创建对象或调用方法的时候才去明确的特殊的类型」
泛型标记

泛型擦除
「在编译阶段使用泛型,运行阶段取消泛型,即擦除」。
擦除是将泛型类型以其父类代替,如String 变成了Object等。其实在使用的时候还是进行带强制类型的转化,只不过这是比较安全的转换,因为在编译阶段已经确保了数据的一致性。
使用泛型
泛型类
泛型类的使用:类名后<?>
public class TDemo<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
public static void main(String[] args) {
TDemo<Integer> tDemo1 = new TDemo<>();
TDemo<String> tDemo2 = new TDemo<>();
tDemo1.setValue(1);
System.out.println(tDemo1.getValue());
tDemo2.setValue("a");
System.out.println(tDemo2.getValue());
}
}
泛型方法
泛型方法使用:在方法返回值前定义泛型<?>,也可以继承一些接口<? extends Comparable>
public static <E extends Comparable<E>> void bubbleSort0(E[] arr) {
// 只需要n-1层外部循环
for (int i = arr.length - 1; i > 0; i--) {
for (int j = 0; j < i && arr[j].compareTo(arr[j + 1]) > 0; j++) {
swap(arr, j, j + 1);
}
}
}
泛型接口
接口<?>,其实现类指定类型如implement 接口
public interface TInterfer<T> {
public T getId();
}
public class TInterferImpl implements TInterfer<String> {
@Override
public String getId() {
return UUID.randomUUID().toString().substring(0, 3);
}
}
序列化
| 名词 | 关键字 | 特性 |
|---|---|---|
| 序列化 | implements Serializable | 底层字节数组,保存对象的状态信息,不能保存静态变量 |
| 反序列化 | transient | 被该关键字修饰的,不能被反系列化 |
创建对象的方式
- new 对象名
- Class.newInstance
- Constructor.newInstance
- clone
- 反序列化
集合
List、Set、Map
集合中的最上层接口只有2类:Map和Collection,List和Set是Collection的下一层。
| 三者名称 | 特性 | 安全类 | 安全原理 |
|---|---|---|---|
| List | 有序、可重复 | CopyOnWriteArrayList | 读写分离,写时复制 |
| Set | 无需、不可重复 | CopyOnWriteArraySet | 读写分离,写时复制 |
| Map | 键值对形式存储 | ConcurrentMap | 没哈希冲突就CAS,有哈希冲突就Syn加锁 |

LIst
| LIst类 | 底层数据结构 | 特性 | 安全性 |
|---|---|---|---|
| ArrayList | 数据 | 增删慢,查询快, | 不安全,安全需要CopyOnWriteArrayList |
| Vector | 数组 | 增删慢,查询快 | 安全,底层是对每一个结点都加Syn |
| LinkedList | 双向链表 | 增删快,查询慢 | 不安全,安全需要CopyOnWriteLinkedList |
Queue
| Queue | 解释 |
|---|---|
| ArrayBlockingQueue | 数组结构组成的有界阻塞队列 |
| LinkedBlockingQueue | 由链表组成的有界阻塞队列(大小默认是21亿,不推荐默认使用) |
| LinkedBlockingDeque | 由链表结构组成的双向阻塞队列 |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayBlockingQueue | 使用优先级队列实现的延迟无界队列 |
| SynchronousQueue | 不存储元素的阻塞队列=单个元素的队列 |
| LinkedTransferQueue | 由链表结构组成的无界阻塞队列 |
Set
| Set | 底层 | 特性 |
|---|---|---|
| HashSet | HashMap<key,PRESENT> | 无序不重复 |
| TreeSet | 二叉树 | 排序不重复 |
| LinkedHashSet | LinkedHashMap<key,PRESENT> | 可前后遍历,不重复 |
Map
| Map | 底层 | 安全性 |
|---|---|---|
| HashMap | 数组+链表/红黑树 | Map不安全 |
| ConcurrentMap | 数组+链表/红黑树 | 安全,原理是冲突syn+不冲突CAS |
| TreeMap | 二叉树 | 不安全 |
| LinkedHashMap | 双向链表 | 不安全 |
HashMap

存储数据的流程
- 对key的hash后获得数组index;2.数组位置为空,初始化容量为16
- 数组位置为空,初试化容量为16
- hash后没有碰撞,就放入数组
- 有碰撞且节点已存在,则替换掉原来的对象
- 有碰撞且节点已经是树结构,则挂载到树上
- 有碰撞且节点已经是链表结构,则添加到链表末尾,并判断链表是否需要转换为树结构(链表结点大于8就转换)
- 完成put操作后,判断是否需要resize()操作

hashMap不安全原因
- 在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。因为采用的是头插法,所以会可能会有循环链表产生,导致数据有问题,在 1.8 版本已修复,改为了尾插法
- 在JDK1.8中,如果在「插入数据时多个线程命中了同一个槽」,可能会有数据覆盖的情况发生,导致线程不安全
HashMap和Hashtable
| 特性 | HashMap | Hashtable |
|---|---|---|
| 安全性 | 不安全,分为1.7和1.8 | 单个线程安全,原因是加了同步锁 |
| hashcode | 对key的hashcode重新计算 | 直接使用key的HashCode |
| key,value | 都可以为null | 都不能为null(注意,idea不会提示报错,但是运行出现空指针异常,源码有提示) |
| 长度 | 默认16,扩容翻倍 | 默认11,扩容+1 |
key,value为空的问题:
public static void main(String[] args) {
HashMap<Integer, Integer> hashmap = new HashMap<>();
hashmap.put(null, null);// hashmap两个都可以存null
Hashtable<Integer, Integer> hashtable = new Hashtable<>();
hashtable.put(null, null);//hashtable任一个都不能存null,但idea不会报错,运行会出现空指针异常
}
HashMap的长度为什么是2的幂次方?
答:提高数组利用率,减少冲突(碰撞)的次数,提高HashMap查询效率
// 源码计算index的操作:n是table.length
if ((p = tab[i = (n - 1) & hash]) == null)
ConcurrentHashMap
线程安全的底层原理:没有哈希冲突就大量CAS插入+如果有哈希冲突就Syn加锁

TreeMap
treeMap底层使用红黑树,会按照Key来排序
- 如果是字符串,就会按照字典序来排序
- 如果是自定义类,就要使用2种方法指定比较规则
- 实现Compareable接口,但是需要重新定义比较规则就要修改源码,麻烦
- 创建实例时候,传入一个比较器Comparator,重新定义规则不需要修改源码,推荐使用
public class TreeMapDemo {
public static void main(String[] args) {
// treeMap中自定义类需要指定比较器
// 方式一:自定义类实现Comparable接口
TreeMap<User, User> treeMap1 = new TreeMap<>();
// 方式二:创建实例指定比较器Comparator
TreeMap<User, User> treeMap2 = new TreeMap<>(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
// 定义比较规则
return 0;
}
});
}
}
public class User implements Comparable {
private String id;
private String username;
@Override
public int compareTo(Object obj) {
// 这里定义比较规则
return 0;
}
}
ArrayList和LinkedList
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层 | 动态数组,查询快,插入慢 | 双向链表,查询慢,插入快 |
| 安全 | 不安全 | 不安全 |
| 接口 | 都是List接口的实现类,存储有序,可重复 | 都是List接口的实现类,存储有序,可重复 |
Vetor和CopyOnWriteList
list安全类是如下两个:Vetor、CopyOnWriteList; Collections.synchronizedLis是JDK包装实现线程安全的工具类
| Vector | Collections.synchronizedList | CopyOnWriteList | |
|---|---|---|---|
| 线程安全原理 | synchronized加载方法上 | 内部类封装SynchronizedList方法 | 写加锁,读不加锁,通过volatile保证可见性 |
public synchronized int capacity() {
return elementData.length;
}
// Vetor锁都加在方法上
public synchronized int size() {
return elementCount;
}
public synchronized boolean isEmpty() {
return elementCount == 0;
}
...
}
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -7754090372962971524L;
final List<E> list;
// Collections.synchronizedList:内部类SynchronizedList,锁加载内部类里面
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
....
}
// CopyOnWriteList 写加锁
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// CopyOnWriteList是复制数组保证线程安全
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
// CopyOnWriteList 读不加锁,原数组通过 transient volatile保证不可系列化和可见性
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
public E get(int index) {
return get(getArray(), index);
}
LinkedHashMap和LinkedHashSet
答:LinkedHashMap可以记录下元素的插入顺序和访问顺序
- LinkedHashMap内部的Entry继承于HashMap.Node,这两个类都实现了Map.Entry<K,V>
- 底层链表是双向链表,Node不光有value,next,还有before和after属性,保证了各个元素的插入顺序
- 通过构造方法public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder), accessOrder传入true可以实现LRU缓存算法(访问顺序)
集合是不安全
并发修改异常:ConcurrentModificationException
// 普通的集合类都是线程不安全的:java.util.ConcurrentModificationException
private static void ListIsNotSafe() {
List<String> list = new ArrayList<>();
for (int i = 0; i < 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list.toString());
}, String.valueOf(i)).start();
}
}
集合安全的方法
集合安全:
1.老API:Vector
2.集合安全工具类:Collections.synchronizedList
3.读写锁:new CopyOnWriteArrayList<>()
private static void ListSafe() {
List<String> list = new ArrayList<>();
List<String> list1 = new Vector<>();
List<String> list2 = Collections.synchronizedList(list);
List<String> list3 = new CopyOnWriteArrayList<>();
for (int i = 0; i < 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list.toString());
}, String.valueOf(i)).start();
}
}
LRU算法
最近最少使用算法: 根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
public class LRUCache {
/**
* 输入
* ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
* [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
* 输出
* [null, null, null, 1, null, -1, null, -1, 3, 4]
* 解释
* LRUCache lRUCache = new LRUCache(2);// 长度为2
* lRUCache.put(1, 1); // 缓存是 {1=1}
* lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
* lRUCache.get(1); // 返回 1
* lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
* lRUCache.get(2); // 返回 -1 (未找到)
* lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
* lRUCache.get(1); // 返回 -1 (未找到)
* lRUCache.get(3); // 返回 3
* lRUCache.get(4); // 返回 4
*/
private int size;
private int capacity;
private Map<Integer, DLinkedNode> cache;
private DLinkedNode head;
private DLinkedNode tail;
public LRUCache(int capacity) {
// 当前链表长度
this.size = 0;
// 链表最大长度
this.capacity = capacity;
// map作为缓存,存储key,value
this.cache = new HashMap<>(capacity);
// 头尾虚拟指针,不存任何值:题目规定key、value>=0,这里可以传-1表示头尾结点
this.head = new DLinkedNode(-1, -1);
this.tail = new DLinkedNode(-1, -1);
this.head.next = tail;
this.tail.pre = head;
}
public int get(int key) {
if (size == 0) {
return -1;
}
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 操作过的数放到头部 且 删除原链表位置
deleteNode(node);
removeToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
// 缓存里有put的值
if (node != null) {
// 更新缓存
node.value = value;
// 操作过的数放到头部 且 删除原链表位置
deleteNode(node);
removeToHead(node);
return;
}
// 缓存里没有put的值
// 当前链表长度=最大值:清理缓存,删除末尾结点,更新size
if (size == capacity) {
cache.remove(tail.pre.key);
deleteNode(tail.pre);
size--;
}
// 生成新的结点放入缓存,放到链表头部,更新size
node = new DLinkedNode(key, value);
cache.put(key, node);
removeToHead(node);
size++;
}
private void deleteNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
private void removeToHead(DLinkedNode node) {
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
}
/**
* 定义双向链表结点数据结构
*/
private class DLinkedNode {
int key;
int value;
DLinkedNode pre;
DLinkedNode next;
public DLinkedNode(int key, int value) {
this.key = key;
this.value = value;
}
public DLinkedNode() {
}
}
}
雪花算法、UUID、自增ID区别
自增ID,是最简单的方式,但是不适合分表分库场景,如果把同一张表放到两个库里,那么会出现主键冲突,ID重复
UUID:值没什么规律,是字符串类型,性能肯定不如自增,优点就是可用于分表分库场景
雪花ID:时间戳 + 机器码(机器中心+数据中心) + 序列号。递增的,是long类型,可用于分表分库场景,性能比UUID好。
如果是简单的小项目,可以考虑用自增ID,如果是中大型项目,推荐用雪花ID
在这里插入图片描述
JVM
JVM运行机制

内存结构
| 堆 | 方法区 | 栈 | 本地方法栈 | PCR | |
|---|---|---|---|---|---|
| 存放对象 | 实例化对象,分为年轻代、老年代、永久代 | 常量、静态变量、类信息、JIT后代码 | 栈帧(局部变量表、操作数栈、动态链接、方法出口) | 本地Native方法 | 存放当前线程执行的字节码的位置指示器 |
| 私有/共享 | 共享 | 共享 | 私有 | 私有 | 私有 |
| 异常 | OutOfMemoryError | OutOfMemoryError | StackOverflowError | StackOverflowError | 不会抛出异常 |
| 调参 | -Xms、-Xmx、-Xmn | -XX:MetaspaceSize | -Xss |

堆

年轻代:占堆的1/3。分类如下
| 堆分类 | 解释 | 补充 |
|---|---|---|
| Eden | Java新创建的对象,如果新对象属于大对象,直接放到老年代 | 调整老年代对象大小:XX:PretenureSizeThreshold |
| SurvivorFrom | 将上一次MinorGC的幸存者作为这一次MinorGC的扫描对象 | |
| SurvivorTo | 上一次MinorGC的幸存者,对象晋升为老年代次数默认15次 | 调整晋升为老年代次数:XX:MaxTenuringThreshold |
老年代:占堆的2/3
永久代:存放永久的Class和Meta数据,不会发生垃圾回收
如何确定垃圾
| 引用计数法 | GC Roots | |
|---|---|---|
| 优点 | 简单 | 不会产生循环依赖问题 |
| 缺点 | 无法解决对象之间的循环依赖问题 | 比引用计数法复杂 |
| 对象 | 堆中存在的对象 | 栈引用的对象、方法区中的静态引用、JNI中的引用 |

垃圾回收算法
| 名称 | 优点 | 缺点 |
|---|---|---|
| 复制算法 | 最简单高效,不会产生碎片。年轻代默认算法 | 利用率低下,只有一半 |
| 标记清除算法 | 利用率较高 | 效率低+空间碎片问题 |
| 标记整理算法 | 解决了空间碎片问题 | 效率还是不高 |
| 分代收集算法 | 新生代用复制算法;老年代用后两者结合算法 | 并不是一种算法,而是一种思想 |
标记清除算法

复制算法

标记整理算法

分代收集算法

四种引用状态
**强引用:**普通存在, P p = new P(),只要强引用存在,垃圾收集器永远不会回收掉被引用的对象。是造成内存泄露的主要原因。
**软引用:**通过SoftReference类来实现软引用,在内存不足的时候会将这些软引用回收掉。
**弱引用:**通过WeakReference类来实现弱引用,每次垃圾回收的时候肯定会回收掉弱引用。
**虚引用:**也称为幽灵引用或者幻影引用,通过PhantomReference类实现。设置虚引用只是为了对象被回收时候收到一个系统通知。
垃圾收集器


生产环境中常用的GC收集器:新生代ParNewGC,老年代CMSGC
| 名称 | 周期 | 算法 | 特点 |
|---|---|---|---|
| Serial收集器 | 新生代 | 单线程复制算法 | 1.单线程收集器;2.缺点是STW |
| ParNew收集器 | 新生代 | 多线程复制算法 | Serial多线程版本 |
| Parallel Scavenge收集器 | 新生代 | 多线程复制算法 | 1.吞吐量优先;2.自适应调节吞吐量策略;3.多线程并行收集 |
| Serial Old收集器 | 老年代 | 单线程标记整理算法 | Serial老年代版本 |
| Parallel Old收集器 | 老年代 | 多线程标记整理算法 | Parallel Scavenge老年代版本 |
| CMS收集器 | 老年代 | 多线程标记清除算法 | 并发收集、低停顿、缺点还是会产生空间碎片 |
| G1收集器 | 老年代 | 标记整理+清除算法 | 并行与并发、分代收集、空间整理、可预测停顿 |
Serial收集器

ParNew收集器

Parallel Scavenge收集器

Serial Old收集器

ParallelOld收集器

CMS收集器
概念:一种以获取最短回收停顿时间为目标的GC。CMS是基于标记-清除算法实现的,是一种老年代收集器,通常与ParNew一起使用。
**CMS的垃圾收集过程分为5步:**有4步的说法,5步的说法,7步的说法,这里按照5步的说法
-
初始标记:需要“Stop the World”,初始标记仅仅只是标记一下GC Root能直接关联到的对象,速度很快。
-
并发标记:是主要标记过程,这个标记过程是和用户线程并发执行的。
-
如果在重新标记之前刚好发生了一次MinorGC,会不会导致重新标记阶段Stop the World时间太长?
答:不会的,在并发标记阶段其实还包括了一次并发的预清理阶段,虚拟机会主动等待年轻代发生垃圾回收,这样可以将重新标记对象引用关系的步骤放在并发标记阶段,有效降低重新标记阶段Stop The World的时间。
-
-
重新标记:需要“Stop the World”,为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录(停顿时间比初始标记长,但比并发标记短得多)。
-
并发清除:和用户线程并发执行的,基于标记结果来清理对象。
-
并发重置:重置CMS的数据结构,等待下一次垃圾回收,与用户线程同时运行

CMS优缺点:
| CMS优点 | CMS缺点 |
|---|---|
| 并发收集,停顿时间低 | 对CPU资源非常敏感;收集过程中会产生浮动垃圾;标记-清除方式会产生内存碎片 |
由于在应用运行的同时进行垃圾回收,所以有些垃圾可能在垃圾回收进行完成时产生,这样就造成了**“Floating Garbage”**,这些垃圾需要在下次垃圾回收周期时才能回收掉。所以,并发收集器一般需要20%的预留空间用于这些浮动垃圾。

CMS时特殊情况:concurrent-mode-failure
现象说明:在 CMS GC 过程中,如果在并行清理的过程中老年代的空间不足以容纳应用产生的垃圾,则会抛出 “concurrent mode failure”。
影响:老年代的 CMS GC 会转入 STW 的串行,所有应用线程被暂停,停顿时间变长。
可能的原因及解决方案:
- 老年代使用太多时才触发 CMS GC,可以调整
- XX:CMSInitiatingOccupancyFraction=N,告诉虚拟机当 old 区域的空间上升到 N% 的时候就开启 CMS; - CMS GC 后空间碎片太多,可以加上
- XX:+UseCMSCompactAtFullCollection和-XX:CMSFullGCsBeforeCompaction=n参数,表示经过 n 次 CMS GC 后做一次碎片整理。 - 垃圾产生速度超过清理速度(比如说新生代晋升到老年代的阈值过小、Survivor 空间过小、存在大对象等),可以通过调整对应的参数或者关注程序代码来解决。
G1收集器

JVM常用调参
public static void main(String[] args) {
String JAVA_OPTS =
"-Xms4096m –Xmx4096m " +
"-XX:NewRatio=2 -XX:SurvivorRatio=8 -Xloggc:/home/work/log/serviceName/gc.log -XX:+PrintGCDetails " +
"-XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -XX:+UseConcMarkSweepGC -XX:+UseParNewGC" +
"-XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=10 ";
}
| JVM 参数 | 说明 |
|---|---|
| Xms | 初始堆大小 |
| Xmx | 最大堆大小 |
| Xmn | 年轻代大小 |
| Xss | 每个线程的堆栈大小 |
| MetaspaceSize | 首次触发 Full GC 的阈值,该值越大触发 Metaspace GC 的时机就越晚 |
| MaxMetaspaceSize | 设置 metaspace 区域的最大值 |
| +UseConcMarkSweepGC | 设置老年代的垃圾回收器为 CMS |
| +UseParNewGC | 设置年轻代的垃圾回收器为并行收集 |
| CMSFullGCsBeforeCompaction=5 | 设置进行 5 次 full gc(CMS)后进行内存压缩。由于并发收集器不对内存空间进行压缩 / 整理,所以运行一段时间以后会产生 “碎片”,使得运行效率降低。此值设置运行多少次 full gc 以后对内存空间进行压缩 / 整理 |
| +UseCMSCompactAtFullCollection | 在 full gc 的时候对内存空间进行压缩,和 CMSFullGCsBeforeCompaction 配合使用 |
| +DisableExplicitGC | System.gc () 调用无效 |
| -verbose:gc | 显示每次 gc 事件的信息 |
| +PrintGCDetails | 开启详细 gc 日志模式 |
| +PrintGCTimeStamps | 将自 JVM 启动至今的时间戳添加到 gc 日志 |
| -Xloggc:/home/admin/logs/gc.log | 将 gc 日导输出到指定的 /home/admin/logs/gc.log |
| +HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs | 当堆内存空间溢出时输出堆的内存快照到指定的 /home/admin/logs |
类加载阶段

加载:JVM读取Class文件,根据Class文件描述创建Java.lang.Class对象的过程
验证:确保Class文件是否符合虚拟机的要求
准备:为类变量分配内空间并设置变量的初始值,初始值指不同数据类型的默认值,但是final和非final不一样
public class InitFinal {
// 没有加final:value1在类初始化的“准备”阶段分配为int类型的默认值0,在“初始化”阶段才分配为10
private static int value1 = 10;
// final表示:value2在类初始化的“准备”阶段分配为10
private static final int value2 = 10;
}
解析:将常量池中的符号引用替换为直接引用
初始化:执行类构造器的方法为类进行初始化,引出了下面的类初始化顺序的面试题
类初始化阶段
- 父类的静态方法、静态代码块
- 子类的静态方法、静态代码块
- 父类被重写的静态方法,父类也要先执行;父类被重写的非静态方法,父类不执行
- 子类的重写父类的非静态方法
- 父类的非静态代码块、构造器
- 子类的非静态代码块、构造器
public class Father {
// 这个方法被子类重写,类初始化是父类被重写的不执行,调到执行子类重写的方法
private int i = test();
private static int j = method();
// 2 静态代码块
static{
System.out.print("(1)");
}
// 7 父类构造方法
Father(){
System.out.print("(2)");
}
// 6 非静态代码块
{
System.out.print("(3)");
}
// 这个方法被子类重写,类初始化是父类被重写的不执行
public int test(){
System.out.print("(4)");
return 1;
}
// 1 执行静态方法
public static int method(){
System.out.print("(5)");
return 1;
}
}
public class Son extends Father{
// 8 父类类初始化完成,顺序执行子类非静态方法,又输出一遍9
private int i = test();
private static int j = method();
// 4 静态代码块
static {
System.out.print("(6)");
}
// 10 子类构造方法
Son() {
System.out.print("(7)");
}
// 9 子类非静态代码块
{
System.out.print("(8)");
}
// 5 被重写的非静态方法test方法
public int test() {
System.out.print("(9)");
return 1;
}
// 3 静态方法
public static int method() {
System.out.print("(10)");
return 1;
}
public static void main(String[] args) {
// 实例化初始化过程1:包含子父类静态加载
new Son();
// 实例化初始化过程2:不包含所有的静态加载
new Son();
}
}
执行结果:
(5)(1)(10)(6)(9)(3)(2)(9)(8)(7)
(9)(3)(2)(9)(8)(7)
类加载器
类加载机制:JVM通过双亲委派进行类的加载,当某个类加载器在接到加载类的请求时,将加载任务依次委托给上一级加载器,如果分类能加载,就父类加载;父类不能记载,再子类往下依次判断是否能加载
- 启动类加载器(bootstrapClassLoader):负责加载支撑JVM运行的位于JRE的
lib目录下的核心类库,比如 rt.jar、charsets.jar等。底层是用C++书写,所以JVM输出为null。 - 扩展类加载器(extClassLoader):负责加载支撑JVM运行的位于JRE的lib目录下的
ext扩展目录中的JAR 类包 - 应用类加载器(appClassLoader):用户
classpath下自己写的类 - 自定义加载器(重写某些方法):负责加载用户
自定义路径下的类包
public class ClassLoaderDemo {
public static void main(String[] args) {
ClassLoader bootstrapCL = String.class.getClassLoader();
System.out.println("启动类加载器:" + bootstrapCL);
ClassLoader extCL = DESCipher.class.getClassLoader();
System.out.println("扩展类加载器:" + extCL);
ClassLoader appCL = ClassLoaderDemo.class.getClassLoader();
System.out.println("应用类加载器:" + appCL);
}
}
执行结果:
启动类加载器:null// 启动类加载器调用底层c++,无返回值
扩展类加载器:sun.misc.Launcher$ExtClassLoader@873330
应用类加载器:sun.misc.Launcher$AppClassLoader@b4aac2
双亲委派机制

概念:加载某个类时会先找父亲加载,层层向上,如果都不行,再逐步向下由儿子加载。
双亲委派源码:ClassLoader的loadClass()方法
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
设计双亲委派机制的好处:
- 沙箱安全机制,保证安全性:比如自己写的String类不会被加载,防止JDK核心API不会被随意篡改
- 避免类的重复加载,保证唯一性:当父类加载过该类后,子类不会再加载,保证了被加载类的唯一性
自定义类加载器和打破双亲委派机制
自定义类加载器只需要extends ClassLoader 类,该类有两个核心方法:
loadClass(String, boolean),实现了双亲委派机制findClass(),默认实现是空方法,所以我们自定义类加载器主要是重写findClass方法。
package 基础面试.JVM;
import java.io.FileInputStream;
import java.lang.reflect.Method;
public class MyClassLoader {
static class MyStaticCL extends ClassLoader {
private String classPath;
public MyStaticCL(String classPath) {
this.classPath = classPath.replaceAll("\\.", "/");
}
private byte[] loadByte(String name) throws Exception {
name = name.replaceAll("\\.", "/");
FileInputStream fis = new FileInputStream(classPath + "/" + name + ".class");
int len = fis.available();
byte[] data = new byte[len];
fis.read(data);
fis.close();
return data;
}
// 自定义类加载器:重写findClass
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try {
byte[] data = loadByte(name);
// 转换成class对象返回
return defineClass(name, data, 0, data.length);
} catch (Exception e) {
e.printStackTrace();
throw new ClassNotFoundException();
}
}
// 打破双亲委派:重写loadClass
@Override
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
long t1 = System.nanoTime();
// ,否则使用双亲委派
if (!name.startsWith("基础面试.JVM")) {
c = this.getParent().loadClass(name);
} else {
c = findClass(name);
}
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
}
public static void main(String[] args) throws Exception {
String classpath = "E:\\product\\test";
// 指定类加载器:E:\product\test\基础面试\JVM下的user.class
String userClass = "基础面试.JVM.User";
MyStaticCL classLoader = new MyStaticCL(classpath);
Class<?> userClass1 = classLoader.loadClass(userClass);
Object object = userClass1.newInstance();
Method method = userClass1.getDeclaredMethod("print", null);
method.invoke(object, null);
System.out.println("自定义加载器名字:" + userClass1.getClassLoader().getClass().getName());
}
}
package 基础面试.JVM;
public class User {
private String userName ;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public void print(){
System.out.println("MyStaticCL加载的User.print方法");
}
}
执行结果:
MyStaticCL加载的User.print方法
自定义加载器名字:基础面试.JVM.MyClassLoader$MyStaticCL
并发线程
进程和线程的区别
线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
创建线程的方式
- extends Thread类
- implements Runnabl、Callable接口
- 通过ExecutorService和Callable实现有返回值的线程
- 基于线程池
public class ThreadDemo1 extends Thread {
// 1.继承Thread
// 2.重写run
@Override
public void run() {
System.out.println("threadDemo1 extends thread");
}
public static void main(String[] args) {
// 3.调用start方法
new ThreadDemo1().start();
}
}
public class ThreadDemo2 implements Runnable {
// 1.implements Runnable
// 2.重写run
@Override
public void run() {
System.out.println("ThreadDemo2 implements Runnable");
}
public static void main(String[] args) {
// 3.调用run方法
new ThreadDemo2().run();
}
}
public class ThreadDemo3 implements Callable<String> {
// 1.3 implements Callable<T>
// 2.重写call方法
@Override
public String call() throws Exception {
return "ThreadDemo3 implements Callable<String>";
}
public static void main(String[] args) {
try {
// 3.call()方法执行
System.out.println(new ThreadDemo3().call());
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class ThreadDemo3 implements Callable<String> {
// 1.3 implements Callable<T>
// 2.重写call方法
@Override
public String call() throws Exception {
return "ThreadDemo3 implements Callable<String>";
}
public static void main(String[] args) {
try {
// 3.call()方法执行
System.out.println(new ThreadDemo3().call());
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class ThreadDemo4 {
public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(
2, 2,
1L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(5));
pool.execute(() -> {
System.out.println("执行业务逻辑");
});
pool.shutdown();
}
}
线程通信方式
- 管道/匿名管道(Pipes) :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
- 有名管道(Names Pipes) : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循先进先出(first in first out)。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
- 信号(Signal) :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
- 消息队列(Message Queuing) :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。
- 信号量(Semaphores) :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
- 共享内存(Shared memory) :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
- 套接字(Sockets) : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
线程的调度方式
- 先到先服务(FCFS)调度算法 : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- 短作业优先(SJF)的调度算法 : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- 时间片轮转调度算法 : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法,又称 RR(Round robin)调度。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
- 多级反馈队列调度算法 :前面介绍的几种进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前被公认的一种较好的进程调度算法,UNIX 操作系统采取的便是这种调度算法。
- 优先级调度 : 为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
线程/进程的5种状态

线程的基本方法
6种常见方法
| 方法名 | 描述 |
|---|---|
| wait | 线程等待,是Object类的非静态方法,会释放占有的锁,使得线程进入WAITING状态,所以通常用于同步代码块 |
| sleep | 线程休眠,是Thread类的静态方法,不会释放锁,使得线程进入TIMED-WAITING状态 |
| yield | 线程让步,使当前线程让出(释放) CPU 时间片, 与其他线程重新竞争 |
| interrupt | 线程中断,影响该线程内部的一个中断标识位,但并不会因为调用了 interrupt 方法而改变线程状态(阻塞、终止等) |
| join | 线程加入,等待其他线程终止,当前线程调用子或另一个线程join方法,当前线程阻塞等待join线程执行完毕 |
| notify | 线程唤醒,是Object类的非静态方法,唤醒等待的一个线程,如果全部线程都在等待,则随机唤醒 |

sleep和wait区别
| 区别 | sleep | wait |
|---|---|---|
| 父亲不同 | Thread类 | Object类 |
| 含义不同 | 必须指定等待时间,结束后,恢复运行状态 | 可以不指定等待时间 |
| 是否释放锁不同 | 不会释放对象锁 | 会释放锁,notify唤醒后,才会重新获取对象锁 |
start和run区别
| 区别 | start | run |
|---|---|---|
| 含义不同 | 启动线程,无需等待run方法执行完毕就可继续执行下面代码 | 指定运行线程的run方法,执行完run方法后,线程终止 |
| 状态不同 | thread.start()线程处于就绪状态,没有运行 | thread.run()线程处于运行状态 |
终止线程四种方式
-
正常运行结束
-
使用退出标志位退出线程
public class StopThread1 extends Thread { // 1.volatile修饰的标志位 private volatile boolean exit = false; @Override public void run() { // 2.while判断是否跳出 while (!exit) { // 执行业务逻辑代码 System.out.println("执行业务逻辑,使得exit=true"); } } } -
使用interrpter终止线程
- 在调用sleep等方法后,抛出异常后,配合break跳出循环,才能结束run方法
public class StopThread2 extends Thread { @Override public void run() { // 1.未阻塞判断中断标志位跳出 while (!isInterrupted()) { try { // 2.线程处于阻塞状态,调用interrupter方法后会抛出异常 Thread.sleep(5 * 1000); } catch (InterruptedException e) { e.printStackTrace(); // 3.抛出异常后,break才跳出循环,才能结束run方法 break; } } } } -
使用stop方法终止线程
- 直接调用Thread.stop()是很危险的,极度不安全
锁分类
乐观锁
读取数据时认为别人不会修改数据,所以不会上锁;更新时判断别人有没有更新该数据。
具体做法:比较当前版本与上一次版本号,如果版本号一致,就更新;如果版本号不一致,则重复读、比较、写操作。
Java中的乐观锁通过CAS操作实现,CAS是一种原子更新操作。
悲观锁
每次读取数据时都认为别人会修改数据,所以每次在读写数据时都会上锁。
Java中的悲观锁大部分基于AQS(抽象队列同步器)架构实现。例如常见的Synchronized、ReentrantLock、Semaphore、CountDownLatch等。该框架下的锁会先尝试以CAS乐观锁去获取锁,如果获取不到,则会转换为悲观锁。
自旋锁
如果持有锁的线程在很短时间内释放锁,那么哪些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞、挂起状态,只需要等一等,在等待持有锁的线程释放锁后立刻获取锁,避免锁时间的消耗。
优点:
- 可以减少CPU上下文切换,对于占用锁的时间非常短或锁竞争不激烈,性能提升明显,提高时间效率
缺点:
- 线程在自旋过程中长时间获取不到锁资源,将引起CPU的浪费
手写一个自旋锁:
class MyResource {
}
public class WhileLockDemo {
AtomicReference<MyResource> atomicReference = new AtomicReference<>();
MyResource myResource = new MyResource();
private void method1() {
System.out.println(Thread.currentThread().getName() + ",加锁啦");
while (!atomicReference.compareAndSet(null, myResource)) {
}
}
private void method2() {
atomicReference.compareAndSet(myResource, null);
System.out.println(Thread.currentThread().getName() + ",解锁啦");
}
public static void main(String[] args) {
WhileLockDemo demo = new WhileLockDemo();
new Thread(() -> {
demo.method1();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
demo.method2();
}, "线程1").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> {
demo.method1();
demo.method2();
}, "线程2").start();
}
}
Synchronized
作用范围:
- 修饰成员变量和非静态方法,锁this对象的实例
- 修饰静态方法,锁Class字节码
- 修饰代码块,锁所有代码块中配置的对象
底层原理:
- 进入时,执行monitorenter,将计数器+1,释放锁monitorexit时,计数器-1
- 当一个线程判断到计数器为0时,则当前锁空闲,可以占用;反之,当前线程进入等待状态
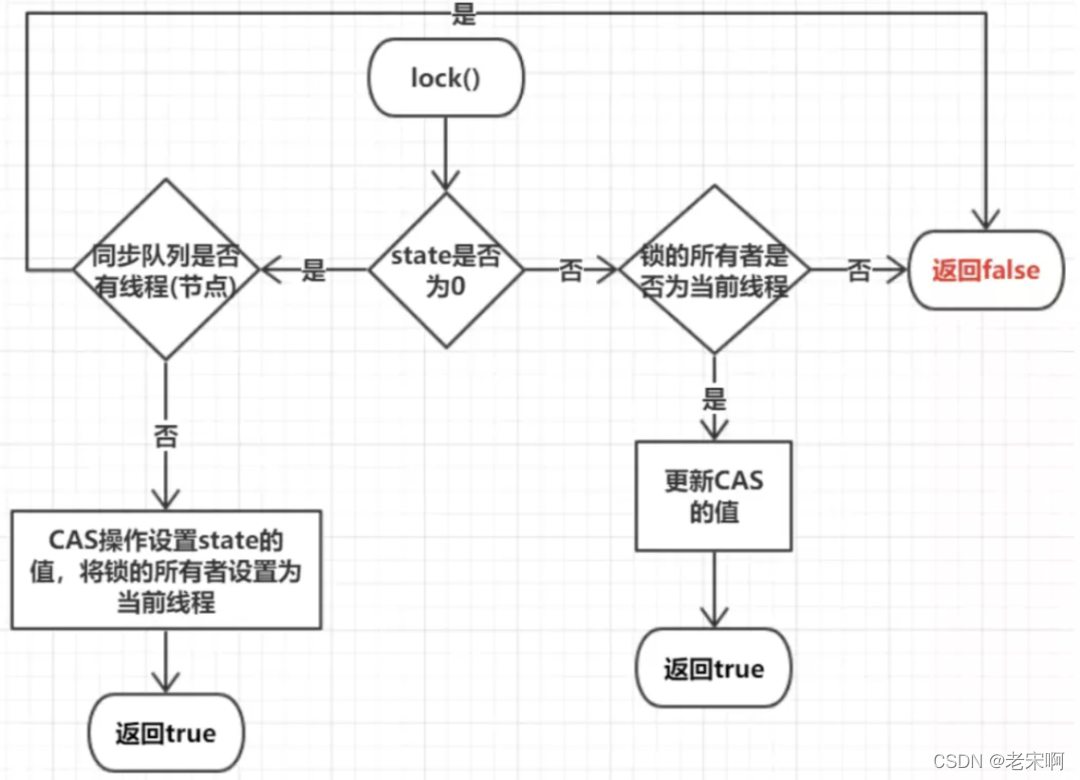
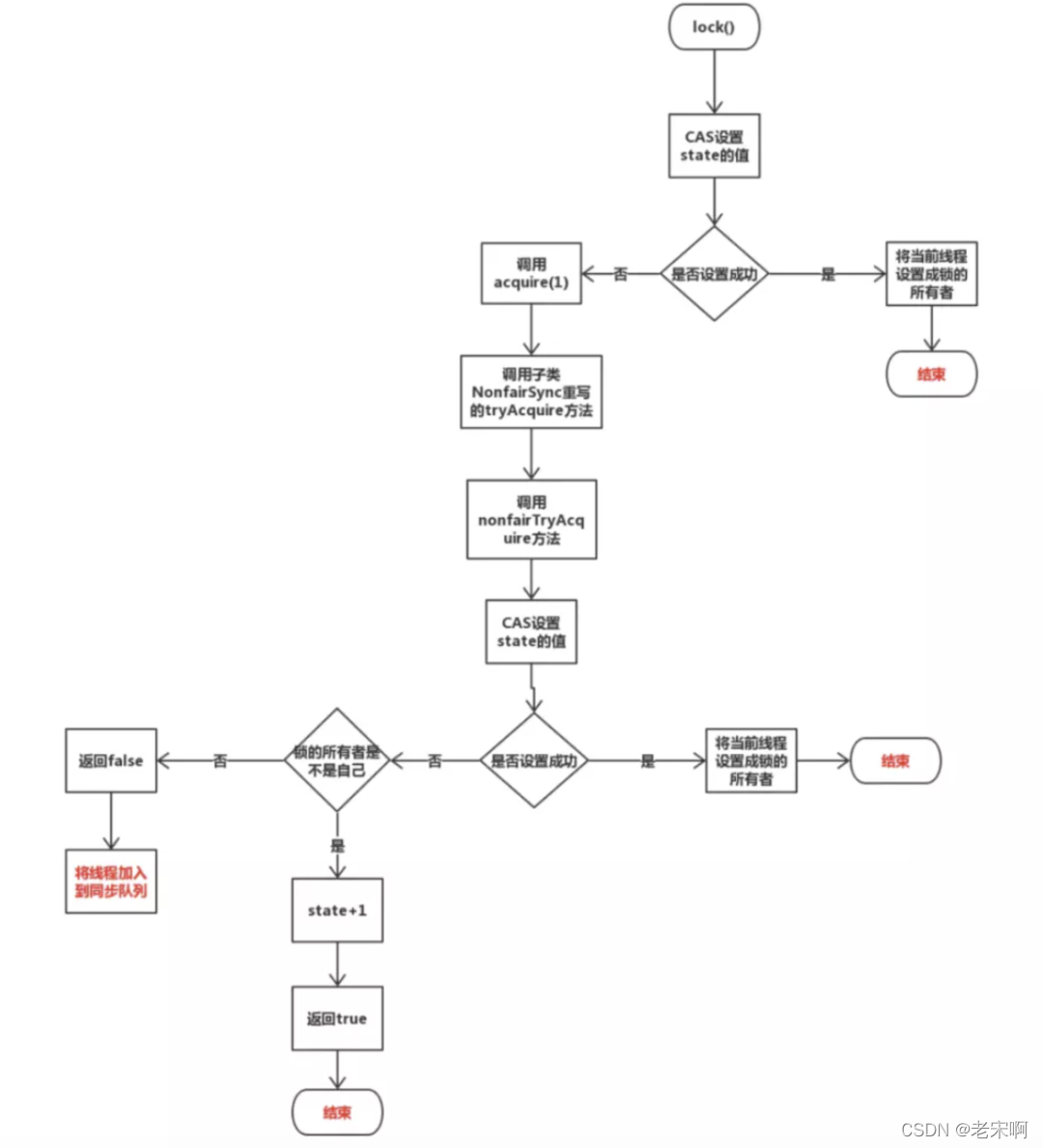
ReenTrantLock
继承了Lcok接口并实现了再接口中定义的方法,是一个可重入的独占锁。ReenTrantLock通过AQS来实现锁的获取和释放。
ReentrantLock有两种模式,一种是公平锁,一种是非公平锁。
- 公平模式下等待线程入队列后会严格按照队列顺序去执行
- 非公平模式下等待线程入队列后有可能会出现插队情况
「公平锁」
「非公平锁」
ReentrantLock如何避免死锁
底层原理:通过AQS来实现锁的获取和释放
如何避免死锁:响应中断、可轮询锁、定时锁
响应中断:
public class InterruptiblyLock {
private static ReentrantLock lock1 = new ReentrantLock();
private static ReentrantLock lock2 = new ReentrantLock();
public static void main(String[] args) {
long curTime = System.currentTimeMillis();
Thread thread1 = new Thread(() -> {
try {
// 如果当前线程未被中断,则获取锁
lock1.lockInterruptibly();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock2.lockInterruptibly();
System.out.println(Thread.currentThread().getName() + ",执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 判断当前线程是否持有锁,如果持有就释放
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getName() + ",退出");
}
}, "线程1");
Thread thread2 = new Thread(() -> {
try {
lock2.lockInterruptibly();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock1.lockInterruptibly();
System.out.println(Thread.currentThread().getName() + ",执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 判断当前线程是否持有锁,如果持有就释放
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getName() + ",退出");
}
}, "线程2");
thread1.start();
thread2.start();
while (true) {
if (System.currentTimeMillis() - curTime >= 3000) {
// 响应式中断线程2,让线程1走完
thread2.interrupt();
}
}
}
}
执行结果

可轮询锁:
通过boolean tryLock()获取锁,如果有可用锁,则获取锁并返回true。如果没有可用锁,则立刻返回false。
定时锁:
通过boolean tryLock(long time,TImeUnit unit)获取定时锁。如果在给定的时间内获得锁,且当前线程未被中断,则获取锁返回true。如果在规定时间内获取不到可用锁,将禁止当前线程,并且发生以下三种情况之一,该线程一直处于休眠状态
- 当期线程获取到可用锁并返回true
- 当前线程在进入该方法时设置了线程的中断状态,或者当前线程在获取锁时被中断,将抛出InterruptedException,并清除当前线程的已中断状态。
- 当前线程获取锁的时间超过了等待时间,返回false。如果设定的时间<=0,则完全不等待。
Synchronized和ReenTrantLock区别
相同点:
- 都用于控制多线程对共享对象的范问
- 都是可重入锁,默认都是非公平锁
- 都保证了可见性和互斥性
| 不同点 | syn | lock |
|---|---|---|
| 含义 | 关键字,隐式获取锁和释放锁 | Api层面,显示获锁和释放锁 |
| 使用 | 不需要手动释放 | 需要手动释放,否则死锁 |
| 中断 | 不可中断,除非抛出异常或者正常运行完毕 | 可响应式中断,try/trylock(time)/lockInterruptibly |
| 公平 | 只能是非公平锁 | 默认非公平,传参为true表示公平 |
| 底层 | 同步阻塞,悲观策略 | 同步非阻塞,乐观并发策略 |
练习题:(Lock能精确唤醒) AA打印5次,BB打印10次,CC打印15次,紧接着AA打印5次,…重复10论
class MyRenLockResources {
// 1=AA,2=BB,3=CC
private int threadName = 1;
private Lock lock = new ReentrantLock();
private Condition a = lock.newCondition();
private Condition b = lock.newCondition();
private Condition c = lock.newCondition();
public void print5() {
lock.lock();
try {
//1 判断 防止虚假唤醒,使用while
while (threadName != 1) {
//不等于1 就不是AA干活,AA等待
a.await();
}
//2 干活 模拟打印5次
for (int i = 1; i <= 5; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
//3 通知别的线程
threadName = 2;
b.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print10() {
lock.lock();
try {
//1 判断 防止虚假唤醒,使用while
while (threadName != 2) {
//不等于1 就不是AA干活,AA等待
b.await();
}
//2 干活 模拟打印5次
for (int i = 1; i <= 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
//3 通知别的线程
threadName = 3;
c.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print15() {
lock.lock();
try {
//1 判断 防止虚假唤醒,使用while
while (threadName != 3) {
//不等于1 就不是AA干活,AA等待
c.await();
}
//2 干活 模拟打印5次
for (int i = 1; i <= 15; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
//3 通知别的线程
threadName = 1;
a.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
public class SyncAndReentrantLockDemo {
public static void main(String[] args) {
MyRenLockResources myResources = new MyRenLockResources();
new Thread(() -> {
for (int i = 1; i <= 10; i++) {
myResources.print5();
}
}, "AA").start();
new Thread(() -> {
for (int i = 1; i <= 10; i++) {
myResources.print10();
}
}, "BB").start();
new Thread(() -> {
for (int i = 1; i <= 10; i++) {
myResources.print15();
}
}, "CC").start();
}
}
ReentrantReadWriteLock
读加读锁,写加写锁;多个读锁不互斥、读锁和写锁互斥。
如果系统要求共享数据可以同时被很多线程并发读,但不能支持并发写,使用读锁能很大提高效率。
如果系统要求共享数据可以只能有一个线程并发写,但不能支持并发读,需要用到写锁。
public class SafeCache {
private final Map<String, Object> cache = new HashMap<>();
/**
* 读写锁:读写分离。多个读锁不互斥,写锁互斥且读锁和写锁也互斥
*/
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
/**
* 读加读锁
*/
public Object get(String key) {
readLock.lock();
try {
return cache.get(key);
} finally {
readLock.unlock();
}
}
/**
* 写加写锁
*/
public void put(String key, Object value) {
writeLock.lock();
try {
cache.put(key, value);
} finally {
writeLock.unlock();
}
}
}
Java并发关键字
CountDownLath
概念:用一个信号量去等待子线程执行完毕,类似计数器
- 使用枚举类给线程命名,学习countDownLatch和枚举类减少if判断作用
public enum CountryEnum {
ONE(1, "齐"),
TWE(2, "燕"),
THREE(3, "楚"),
FOUR(4, "赵"),
FIVE(5, "魏"),
SIX(6, "韩");
private Integer retCode;
private String retMessage;
//Enum自带Setter,只用生产getter
public Integer getRetCode() {
return retCode;
}
public String getRetMessage() {
return retMessage;
}
//构造器
CountryEnum(Integer retCode, String retMessage) {
this.retCode = retCode;
this.retMessage = retMessage;
}
//获取枚举类中的值
public static CountryEnum forEach_CountryEnum(Integer codeIndex) {
// 枚举自带的元素数组,可用于遍历
CountryEnum[] eles = CountryEnum.values();
for (CountryEnum ele : eles) {
if (codeIndex == ele.getRetCode()) {
return ele;
}
}
return null;
}
}
public class CountDownLatchDemo {
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 1; i <= 6; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "国,被灭了");
countDownLatch.countDown();
// 使用枚举类给线程命名,学习countDownLatch和枚举类减少if判断作用
}, CountryEnum.forEach_CountryEnum(i).getRetMessage()).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName() + ":秦国一统天下");
}
}
执行结果:
齐国,被灭了
魏国,被灭了
赵国,被灭了
楚国,被灭了
燕国,被灭了
韩国,被灭了
main:秦国一统天下
CyclicBarrier
概念:循环屏障,多线程等待。CyclicBarrier运行状态叫Barrier状态,在调用await()方法后,处于Barrier状态。
await():挂起当前线程知道所有线程都为Barrier状态同时执行后续逻辑
public class CyclicBarrierDemo {
public static void main(String[] args) {
// 同步器CyclicBarrier:指定屏障前等待线程数量, 到达屏障后执行的语句
CyclicBarrier barrier = new CyclicBarrier(7, () -> {
// 构造器第二个参数:Runnable接口
System.out.println("龙珠齐,召唤神龙");
});
for (int i = 1; i <= 7; i++) {
final int resources = i;
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 收集到第" + resources + "颗龙珠");
//满足屏障初始化条件才能执行,否则等待
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
执行结果:
1 收集到第1颗龙珠
3 收集到第3颗龙珠
4 收集到第4颗龙珠
2 收集到第2颗龙珠
5 收集到第5颗龙珠
6 收集到第6颗龙珠
7 收集到第7颗龙珠
龙珠齐,召唤神龙
Semaphore
概念:一种基于技术的信号量,用于控制同时访问某些资源的线程个数,具体做法是acquire()获取许可,如果没有许可,就等待;在许可使用完毕后,release()释放许可,以便其他线程使用。
public class SemaphoreDemo {
public static void main(String[] args) {
// 模拟3个车位,同时只能有3个线程同时访问,形参=1就是syn
// 1.同步器semaphore(信号量):指定X个线程可以获取资源
Semaphore semaphore = new Semaphore(3);
// 2.创建4个线程=有4个车位
for (int i = 1; i <= 4; i++) {
new Thread(() -> {
try {
// 3.信号量开始计算
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "\t 抢到车位");
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + "\t 停1s后离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 4.信号量释放计数
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
}
执行结果:
1 抢到车位
3 抢到车位
2 抢到车位
2 停1s后离开车位
1 停1s后离开车位
3 停1s后离开车位
4 抢到车位
4 停1s后离开车位
volatile关键字的作用
| 作用 | 可见性 | 防止指令重排 |
|---|---|---|
| 底层原理 | 修改汇编Lock前缀指令,监听MESI缓存一致性协议 | 读写的内存屏障指令 |
模拟可见性:volatile是一个轻量级的同步锁,保证可见性
private static void seeOkByVolatile() {
MyResources myResources = new MyResources();
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + ",进入啦");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
myResources.add();
System.out.println(Thread.currentThread().getName() + ",已经修改data:" + myResources.data);
}, "线程A").start();
while (myResources.data == 0) {
/* System.out.println(Thread.currentThread().getName() + ",while等待");*/
}
System.out.println(Thread.currentThread().getName() + ",模拟结束,data:" + myResources.data);
}
public class MyResources {
volatile int data = 0;
void add() {
this.data = 1;
}
}
保证可见性的底层原理:

模拟指令重排:单例设计模式
public class Singleton {
/**
* volatile保证可见性、防止指令重排,不保证原子性
*/
private volatile static Singleton singleton;
private Singleton() {
}
public static Singleton getInstance() {
// 双端锁外层锁保证singleton实例被创建后,才会加锁,提高效率
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
防止指令重排底层原理:读写的内存屏障指令

死锁
两个或两个以上的进程(线程)在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
死锁条件
| 死锁条件 | 概述 | 破坏死锁 |
|---|---|---|
| 互斥条件 | 该资源任意一个时刻只由一个线程占用 | 无法破坏,因为使用锁的本意就是想让它们互斥的(临界资源需要互斥访问) |
| 请求和保持 | 一个线程 / 进程因请求资源而阻塞时,对已获得的资源保持不放 | 一次性申请所有的资源 |
| 不剥夺 | 线程 / 进程已获得的资源在末使用完之前不能被其他线程 / 进程强行剥夺,只有自己使用完毕后才释放资源 | 占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源 |
| 循环等待 | 若干线程 / 进程之间形成一种头尾相接的循环等待资源关系 | 按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件(最常用) |

手写死锁
写法1:
public class DeadLockDemo1 {
// 资源1,让线程1获得
private static Object resource1 = new Object();
// 资源2,让线程2获得
private static Object resource2 = new Object();
public static void main(String[] args) {
// 线程1
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread().getName() + ":get resource1");
// 线程1等待1s,让线程2获得资源2
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + ":get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + ":get resource2");
// 线程2等待1s,让线程1获得资源1
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread().getName() + ":get resource1");
}
}
}, "线程 2").start();
}
}
执行结果:
线程 1:get resource1
线程 2:get resource2
线程 1:waiting get resource2
线程 2:waiting get resource1
如何避免上述的死锁:让线程2获得资源的锁的顺序和线程1一样,因为破坏了相互等待的条件,所以避免了死锁
写法2:
public class DeadThread implements Runnable{
String lockA;
String lockB;
public DeadThread(String lockA, String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA) {
System.out.println(Thread.currentThread().getName() + "\t 自己持有" + lockA + ",想持有" + lockB);
try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); }
synchronized (lockB) {
System.out.println(Thread.currentThread().getName() + "\t 自己持有" + lockB + ",想持有" + lockA);
}
}
}
}
public class DeadLockDemo2 {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new DeadThread(lockA, lockB), "A").start();
//lockA和lockB互换
new Thread(new DeadThread(lockB, lockA), "B").start();
}
}
A 自己持有lockA,想持有lockB
B 自己持有lockB,想持有lockA
...
排查死锁
| windows系统 | 解释 |
|---|---|
| jps -l | 输出当前包下进程包,对应的Java程序完全的包名,应用主类名下 |
| jstack 死锁进程名 | 查看指定进程名的在JVM栈中的状态 |


阻塞队列
| 阻塞队列 | 解释 |
|---|---|
| 概念 | 队列空,线程再去拿就阻塞;队列满,线程再添加就阻塞 |
| 好处 | 出现阻塞队列后,程序员不用手动去阻塞队列和唤醒队列 |
| 阻塞队列分类 | 解释 |
|---|---|
| ArrayBlockingQueue | 数组结构组成的有界阻塞队列 |
| LinkedBlockingQueue | 由链表组成的有界阻塞队列(大小默认是21亿,不推荐默认使用) |
| LinkedBlockingDeque | 由链表结构组成的双向阻塞队列 |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayBlockingQueue | 使用优先级队列实现的延迟无界队列 |
| SynchronousQueue | 不存储元素的阻塞队列=单个元素的队列 |
| LinkedTransferQueue | 由链表结构组成的无界阻塞队列 |
| 核心API | 抛出异常 | 返回布尔 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
ArrayBlockingQueue
public class BlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
ArrayBlockingQueue<String> blockingQueue = new ArrayBlockingQueue<String>(3);
// 抛出异常组:add/remove/element:会抛出异常:IllegalStateException,一言不合就报异常不推荐使用
blockingQueue.add("1");
blockingQueue.add("2");
blockingQueue.add("3");
// blockingQueue.add("4"); 直接抛出异常
blockingQueue.remove("1");
blockingQueue.remove("2");
blockingQueue.remove("3");
System.out.println("--抛出异常组--");
// 返回布尔型组:offer/poll/peek:失败返回布尔型
blockingQueue.offer("11");
blockingQueue.offer("12");
blockingQueue.offer("13");
System.out.println(blockingQueue.offer("14"));
blockingQueue.poll();
blockingQueue.poll();
blockingQueue.poll();
System.out.println("--返回布尔组--");
// 等待组:put/take:满了就一直等待,等待是为了只要有数据出去立马添加
blockingQueue.put("a");
blockingQueue.put("b");
blockingQueue.put("c");
// blockingQueue.put("d"); 这样会一直等待
// System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println("--等待组--");
// 设置时间组:offer/poll设置失败等待时间
System.out.println(blockingQueue.offer("a", 1L, TimeUnit.SECONDS));
System.out.println(blockingQueue.offer("b", 1L, TimeUnit.SECONDS));
System.out.println(blockingQueue.offer("c", 1L, TimeUnit.SECONDS));
System.out.println("--设置时间组--");
}
}
SynchronousQueue
public class SynchronsBlockingQueue {
public static void main(String[] args) {
// SynchronousQueue:一个线程生产一个,等待别的线程消费完才能进行下去
SynchronousQueue<Integer> blockingQueue = new SynchronousQueue();
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + ",生产了1");
blockingQueue.put(1);
TimeUnit.SECONDS.sleep(1);
//阻塞:SynchronousQueue使用put必须等待别的线程take后
System.out.println(Thread.currentThread().getName() + ",生产了2");
blockingQueue.put(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "线程1").start();
new Thread(() -> {
try {
//消费::SynchronousQueue使用put必须等待别的线程take消费
System.out.println(Thread.currentThread().getName() + ",消费了" + blockingQueue.take());
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + ",消费了" + blockingQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "线程2").start();
}
}
执行结果:
线程1,生产了1
线程2,消费了1
线程1,生产了2
线程2,消费了2
线程池参数
使用ThreadPoolExecutor自建线程池(推荐使用)/Executors工具类(不推荐使用)
// 线程池7大参数
public ThreadPoolExecutor(
// 核心线程数
int corePoolSize,
// 最大线程数
int maximumPoolSize,
// 空闲线程存活时间
long keepAliveTime,
// 线程存活时间单位
TimeUnit unit,
// 阻塞队列
BlockingQueue<Runnable> workQueue,
// 线程工厂
ThreadFactory threadFactory,
// 饱和拒绝策略
RejectedExecutionHandler handler
)
| 线程池参数 | 解释 |
|---|---|
| corePoolSize | 线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。 |
| maximumPoolSize | 线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize; |
| keepAliveTime | 线程池维护线程所允许的空闲时间。当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime; |
| unit | keepAliveTime的单位 |
| workQueue | 用来保存等待被执行的任务的阻塞队列,且任务必须实现Runable接口,在JDK中提供了如下阻塞队列 |
| threadFactory | 它是ThreadFactory类型的变量,用来创建新线程。默认使用Executors.defaultThreadFactory() 来创建线程。使用默认的ThreadFactory来创建线程时,会使新创建的线程具有相同的NORM_PRIORITY优先级并且是非守护线程,同时也设置了线程的名称。 |
| handler | 线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略 |
| workQueue阻塞队列 | 解释 |
|---|---|
| ArrayBlockingQueue | 基于数组结构的有界阻塞队列,按FIFO排序任务 |
| LinkedBlockingQuene | 基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene |
| SynchronousQuene | 一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene |
| PriorityBlockingQuene | 具有优先级的无界阻塞队列 |
| handler拒绝策略 | 解释 |
|---|---|
| AbortPolicy | 直接抛出异常,默认策略 |
| CallerRunsPolicy | 用调用者所在的线程(如以下的main线程)来执行任务 |
| DiscardOldestPolicy | 丢弃阻塞队列中靠最前的任务,并执行当前任务 |
| DiscardPolicy | 直接丢弃任务 |
创建线程池
方式一:Executors
public class ExecutorsDemo {
public static void main(String[] args) {
// 创建线程池方式1:Executors,里面封装了很多,但都不推荐使用
// newFixedThreadPool:核心和最大线程数相同,等待队列是LinkedBlockingQueue,等待时间0
ExecutorService fixedPool = Executors.newFixedThreadPool(5);
// newCachedThreadPool:核心为0,等待队列是SynchronousQueue,最大线程数是最大整数,等待时间60s
ExecutorService cachedPool = Executors.newCachedThreadPool();
// newSingleThreadExecutor:核心和最大为0,等待队列是LinkedBlockingQueue,等待时间0
ExecutorService singletonPool = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
fixedPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + ",办理业务");
});
}
fixedPool.shutdown();
}
}
5种常用的线程池,但是阿里巴巴开发手册都不推荐使用


方式二:new ThreadPoolExecutor
public class ThreadPoolDemo {
public static void main(String[] args) {
// 1 推荐使用使用自建的线程池,学习7大参数
ThreadPoolExecutor myThreadPool = new ThreadPoolExecutor(
2, 5, 1L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(5),
Executors.defaultThreadFactory(),
// AbortPolicy:直接抛出异常
// CallerRunsPolicy:用调用者所在的线程(本类中的main)来执行任务
// DiscardPolicy:丢弃进来的任务
// DiscardOldestPolicy:丢弃之前的第一个任务
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i <= 20; i++) {
int resource = i;
// 2.执行线程池中的线程
myThreadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t 线程进入,\t 获得资源: " + resource);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 3.终止线程池
myThreadPool.shutdown();
// 4.while判断线程池是否终止
while (!myThreadPool.isTerminated()) {
}
System.out.println("所有线程已经终止");
}
}
pool-1-thread-1 线程进入, 获得资源: 1
pool-1-thread-4 线程进入, 获得资源: 9
pool-1-thread-3 线程进入, 获得资源: 8
main 线程进入, 获得资源: 11
pool-1-thread-2 线程进入, 获得资源: 2
pool-1-thread-5 线程进入, 获得资源: 10
main 线程进入, 获得资源: 12
pool-1-thread-2 线程进入, 获得资源: 3
pool-1-thread-3 线程进入, 获得资源: 4
pool-1-thread-1 线程进入, 获得资源: 5
pool-1-thread-4 线程进入, 获得资源: 7
pool-1-thread-5 线程进入, 获得资源: 6
main 线程进入, 获得资源: 18
pool-1-thread-2 线程进入, 获得资源: 13
pool-1-thread-4 线程进入, 获得资源: 14
pool-1-thread-1 线程进入, 获得资源: 16
pool-1-thread-3 线程进入, 获得资源: 15
pool-1-thread-5 线程进入, 获得资源: 17
pool-1-thread-2 线程进入, 获得资源: 19
pool-1-thread-1 线程进入, 获得资源: 20
所有线程已经终止
线程池执行原理
- 创建一个线程池,在还没有任务提交的时候,默认线程池里面是没有线程的。当然,你也可以调用prestartCoreThread方法,来预先创建一个核心线程。
- 线程池里还没有线程或者线程池里存活的线程数小于核心线程数corePoolSize时,这时对于一个新提交的任务,线程池会创建一个线程去处理提交的任务。当线程池里面存活的线程数小于等于核心线程数corePoolSize时,线程池里面的线程会一直存活着,就算空闲时间超过了keepAliveTime,线程也不会被销毁,而是一直阻塞在那里一直等待任务队列的任务来执行。
- 当线程池里面存活的线程数已经等于corePoolSize了,这是对于一个新提交的任务,会被放进任务队列workQueue排队等待执行。而之前创建的线程并不会被销毁,而是不断的去拿阻塞队列里面的任务,当任务队列为空时,线程会阻塞,直到有任务被放进任务队列,线程拿到任务后继续执行,执行完了过后会继续去拿任务。这也是为什么线程池队列要是用阻塞队列。
- 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列也满了,这里假设maximumPoolSize>corePoolSize(如果等于的话,就直接拒绝了),这时如果再来新的任务,线程池就会继续创建新的线程来处理新的任务,直到线程数达到maximumPoolSize,就不会再创建了。这些新创建的线程执行完了当前任务过后,在任务队列里面还有任务的时候也不会销毁,而是去任务队列拿任务出来执行。在当前线程数大于corePoolSize过后,线程执行完当前任务,会有一个判断当前线程是否需要销毁的逻辑:如果能从任务队列中拿到任务,那么继续执行,如果拿任务时阻塞(说明队列中没有任务),那超过keepAliveTime时间就直接返回null并且销毁当前线程,直到线程池里面的线程数等于corePoolSize之后才不会进行线程销毁。
- 如果当前的线程数达到了maximumPoolSize,并且任务队列也满了,这种情况下还有新的任务过来,那就直接采用拒绝的处理器进行处理。默认的处理器逻辑是抛出一个RejectedExecutionException异常。你也就可以指定其他的处理器,或者自定义一个拒绝处理器来实现拒绝逻辑的处理(比如讲这些任务存储起来)。JDK提供了四种拒绝策略处理类:AbortPolicy(抛出一个异常,默认的),DiscardPolicy(直接丢弃任务),DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池),CallerRunsPolicy(交给线程池调用所在的线程进行处理)。

ThreadLocal
| ThreadLocal | 解释 |
|---|---|
| 概念 | 提供每个线程存储自身专属的局部变量值 |
| 实现原理 | 调用 ThreadLocal 的 set () 方法时,实际上就是往 ThreadLocalMap 设置值,key 是 ThreadLocal 对象,值是传递进来的对象;调用 ThreadLocal 的 get () 方法时,实际上就是往 ThreadLocalMap 获取值,key 是 ThreadLocal 对象 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。因为这个原理,所以 ThreadLocal 能够实现 “数据隔离”,获取当前线程的局部变量值,不受其他线程影响。 |
| 风险 | ThreadLocal 被 ThreadLocalMap 中的 entry 的 key 弱引用,如果 ThreadLocal 没有被强引用, 那么 GC 时 Entry 的 key 就会被回收,但是对应的 value 却不会回收。就会造成内存泄漏 |
| 解决办法 | 每次使用完 ThreadLocal,都调用它的 remove () 方法,清除数据 |
CAS
cas 叫做 CompareAndSwap,「比较并交换」,很多地方使用到了它,比如锁升级中自旋锁就有用到,主要是「通过处理器的指令来保证操作的原子性」,它主要包含三个变量:
「1.变量内存地址」
「2.旧的预期值 A」
「3.准备设置的新值 B」
当一个线程需要修改一个共享变量的值,完成这个操作需要先取出共享变量的值,赋给 A,基于 A 进行计算,得到新值 B,在用预期原值 A 和内存中的共享变量值进行比较,「如果相同就认为其他线程没有进行修改」,而将新值写入内存
AtomicInteger就使用了CAS思想
| 解释 | |
|---|---|
| 概念 | AtomicInteger 内部使用 CAS 原子语义来处理加减等操作 |
| CAS底层原理 | 自旋锁+Unsafe类(原子操作) |
| 缺点 | 循环时间长,开销大;只能保证单个共享变量的原子操作;存在ABA问题 |

// 不保证原子性:使用javap -c反编译查看原因
private static void atomicByAtomicInteger() {
// 1.资源类
MyResources myResources = new MyResources();
// 2.atomicInteger保证原子性
for (int i = 0; i < 20; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
myResources.add1();// i++等操作是不保证原子性
myResources.addByAtomic();// 使用automicInteger保证原子性
}
}, String.valueOf(i)).start();
}
// 3.默认的2个线程是main和GC,所以让大于这个2个线程的等待
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + ",data:" + myResources.data);
System.out.println(Thread.currentThread().getName() + ",atomicInteger:" + myResources.atomicInteger);
}
public class MyResources {
volatile int data = 0;
AtomicInteger atomicInteger = new AtomicInteger();
void add() {
this.data = 1;
}
void add1() {
this.data++;
}
void addByAtomic() {
this.atomicInteger.getAndIncrement();
}
}
ABA问题
CAS会出现ABA问题:自旋操作只关心A和A的结果,中间B可能出现很多次,于是线程不安全
public class ABAQuestion {
public static void main(String[] args) {
AtomicReference<Integer> reference = new AtomicReference<>(1);
new Thread(() -> {
reference.compareAndSet(1, 2);
reference.compareAndSet(2, 1);
}, "线程1").start();
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
reference.compareAndSet(1, 1000);
System.out.println(Thread.currentThread().getName() + ",update:" + reference.get());
}, "线程2").start();
}
}
解决ABA问题
解决ABA问题:使用AtomicStampedReference每次CAS指定版本号/时间戳
public class ABASolution {
public static void main(String[] args) {
AtomicStampedReference<Integer> stampedReference = new AtomicStampedReference<>(100, 1);
new Thread(() -> {
int stamp = stampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + " 版本号1:" + stamp);
//暂停1s等t2线程
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
stampedReference.compareAndSet(100, 101, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + " 版本号2:" + stampedReference.getStamp());
stampedReference.compareAndSet(101, 100, stampedReference.getStamp(), stampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + " 版本号3:" + stampedReference.getStamp());
System.out.println(Thread.currentThread().getName() + " 当前实际值:" + stampedReference.getReference());
}, "t1").start();
new Thread(() -> {
int exceptStamp = stampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + " 期望版本号:" + exceptStamp);
//暂停3s等t1线程
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// t1 线程执行完毕后,版本号 = 3 与 这里的 exceptStamp永不相同,所以执行会失败
boolean result = stampedReference.compareAndSet(100, 200, exceptStamp, exceptStamp + 1);
int nowStamp = stampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + " 修改值结果:" + result + " 当前版本号:" + nowStamp + " 期望版本号:" + exceptStamp);
System.out.println(Thread.currentThread().getName() + " 当前实际值:" + stampedReference.getReference());
}, "t2").start();
}
}
执行结果:
t1 版本号1:1
t2 期望版本号:1
t1 版本号2:2
t1 版本号3:3
t1 当前实际值:100
t2 修改值结果:false 当前版本号:3 期望版本号:1
t2 当前实际值:100
AQS
概念:是1个抽象的队列同步器,通过维护 1个共资源状态( Volatile Int State )和一个先进先出( FIFO )的线程等待队列实现同步
底层原理:维护了一个共享资源的变量state


进程和线程
| 进程 | 线程 | |
|---|---|---|
| 概念 | 进程是资源分配的最小单位 | 线程是CPU调度的最小单位 |
| 不同点 | 进程 | 线程 |
|---|---|---|
| 根本区别 | 进程是操作系统资源分配的基本单位 | 线程是CPU调度的最小单位 |
| 资源开销 | 大 | 线程可频繁切换 |
| 环境运行 | 操作系统中能同时运行多个进程 | 同一个进程包括多个线程 |
Web
五层结构

TCP三次握手/四次挥手
三次握手:TCP数据在传输之前会建立连接,需要三次沟通。
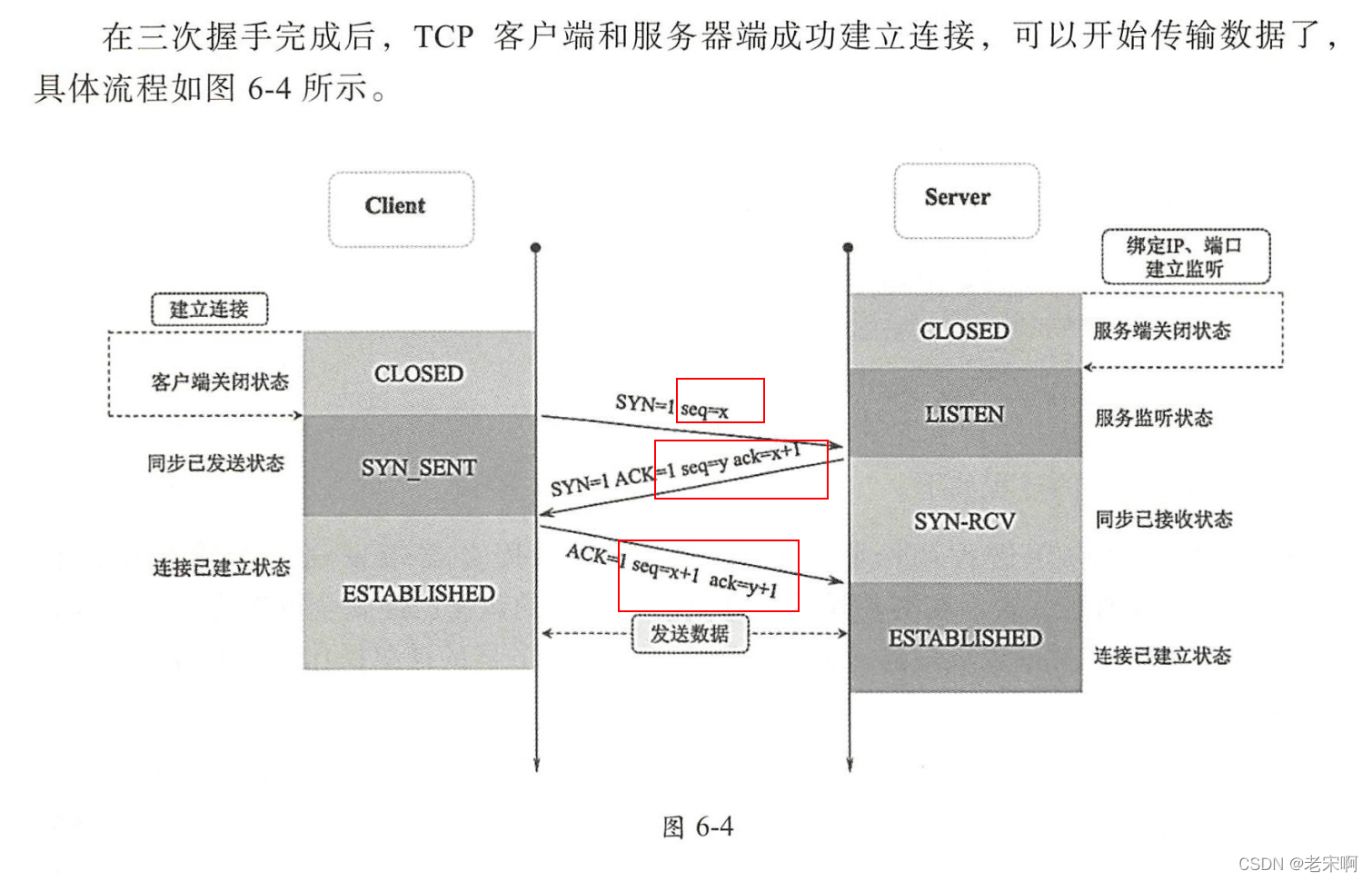
四次挥手:在数据传输完成断开连接的时候,需要四次挥手。
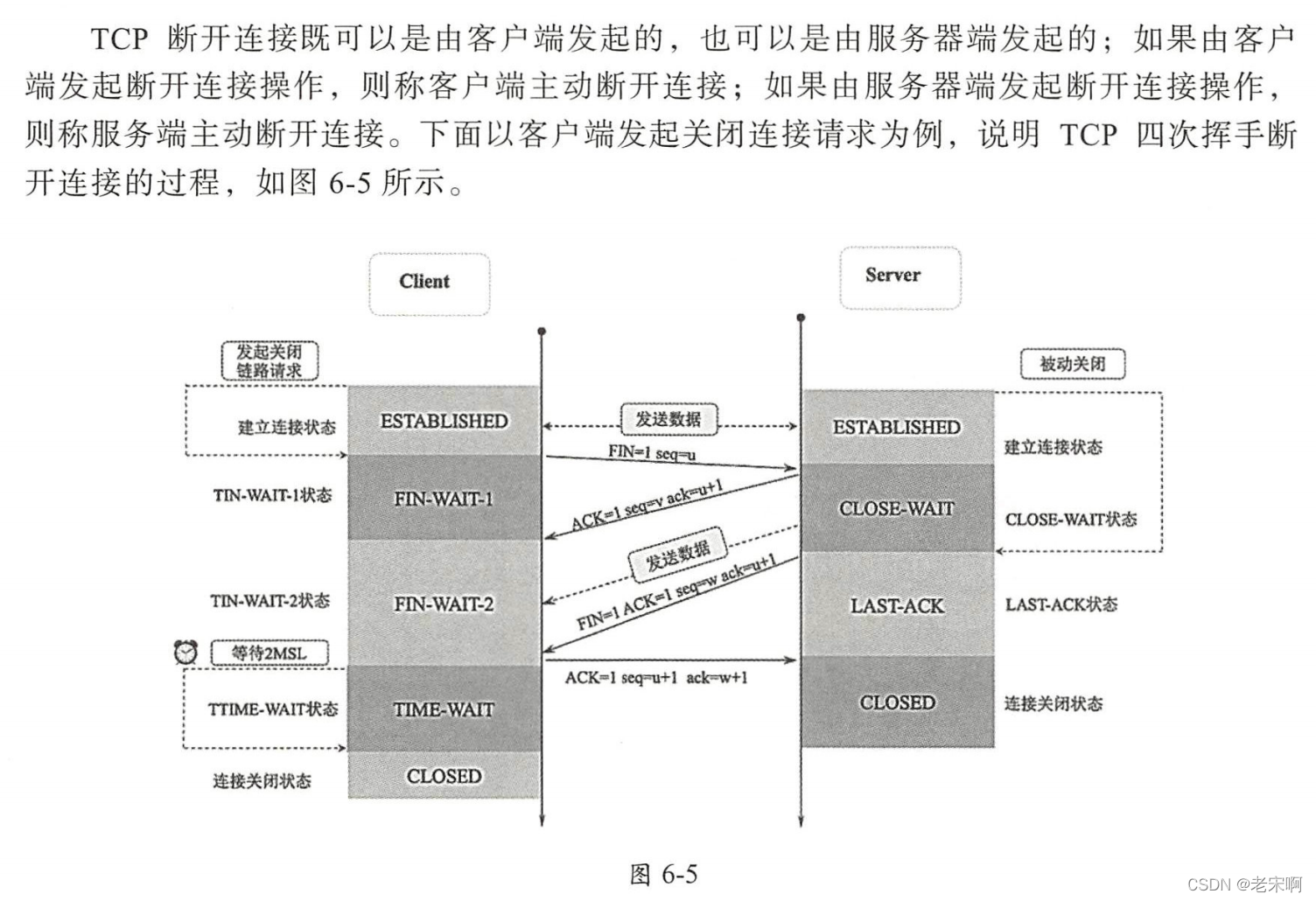
为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
TCP/UDP区别

HTTP传输流程
(1)地址解析:协议号+主机名+端口号+对象地址
(2)封装HTTP数据包:解析协议名、主机名、端口、对象路径等并结合本机自己的信息封装成一个HTTP请求数据包
(3)封装TCP包:将HTTP请求数据包进一步封装成TCP数据包
(4)简历TCP连接:基于TCP的三次握手机制建立TCP连接
(5)客户端发送请求:在简历连接后,客户端发送一个请求给服务器
(6)服务器响应:服务器在接受到请求后,结合业务逻辑进行数据处理,然后想客户端返回相应的响应信息。
(7)服务器关闭TCP连接:服务器在向浏览器发送请求响应数据后关闭TCP连接。
HTTP状态码



HTTP 和 HTTPS
| HTTP | HTTPS | |
|---|---|---|
| 端口 | 80 | 443 |
| 安全性 | HTTP运⾏在TCP之上,所有传输的内容都是明⽂,客户端和服务器端都⽆法验证对⽅的身份 | HTTPS是运⾏在SSL/TLS之上的HTTP协议,SSL/TLS 运⾏在TCP之上。所有传输的内容都经过加密。 |
| 资源消耗 | 小 | 大 |
WebeSocket
WebSocket协议是基于TCP的一种新的网络协议。它实现了浏览器与服务器全双工(full-duplex)通信——允许服务器主动发送信息给客户端。
初次接触 WebSocket 的人,都会问同样的问题:我们已经有了 HTTP 协议,为什么还需要另一个协议?它能带来什么好处?
答案很简单,因为 HTTP 协议有一个缺陷:通信只能由客户端发起,HTTP 协议做不到服务器主动向客户端推送信息。
Spring
Spring组成
发展历程
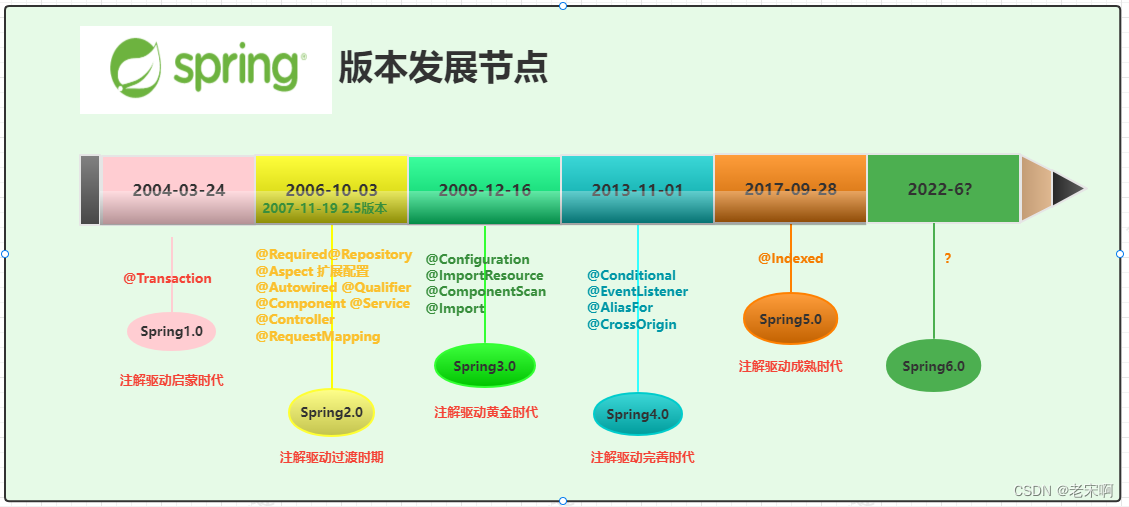
Spring组成
Spring是一个轻量级的IoC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。常见的配置方式有三种:基于XML的配置、基于注解的配置、基于Java的配置.
主要由以下几个模块组成:
Spring Core:核心类库,提供IOC服务;
Spring Context:提供框架式的Bean访问方式,以及企业级功能(JNDI、定时任务等);
Spring AOP:AOP服务;
Spring DAO:对JDBC的抽象,简化了数据访问异常的处理;
Spring ORM:对现有的ORM框架的支持;
Spring Web:提供了基本的面向Web的综合特性,例如多方文件上传;
Spring MVC:提供面向Web应用的Model-View-Controller实现。

Spring好处
序号 好处 说明
1 轻量:Spring 是轻量的,基本的版本大约2MB。
2 控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们。
3. 面向切面编程(AOP):Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开。
4 容器 :Spring 包含并管理应用中对象的生命周期和配置。
5 MVC框架: Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品。
6 事务管理:Spring 提供一个持续的事务管理接口,
7 异常处理:Spring 提供方便的API把具体技术相关的异常 ``(比如由JDBC,Hibernate or JDO抛出的)转化为一致的unchecked 异常。
8 最重要的:用的人多!!!
用到的设计模式
- 单例
- 原型
- 模版模式(JDBCTemplate)
- 观察者模式(监听器监听对象状态)
- 简单工厂模式(xml配置时,getBen通过id或者name获取实例)
- 适配器模式(AOP的Advice和interceptor之间的转换就是通过适配器模式实现的。)
- 代理模式(AOP的动静态代理)
循环依赖
什么是循环依赖?
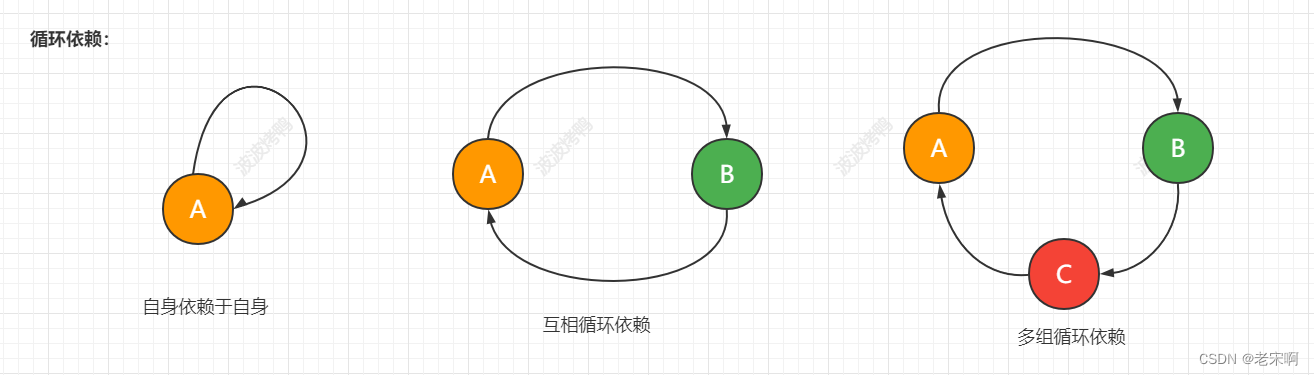
解决本质:
- 使用缓存提前暴露
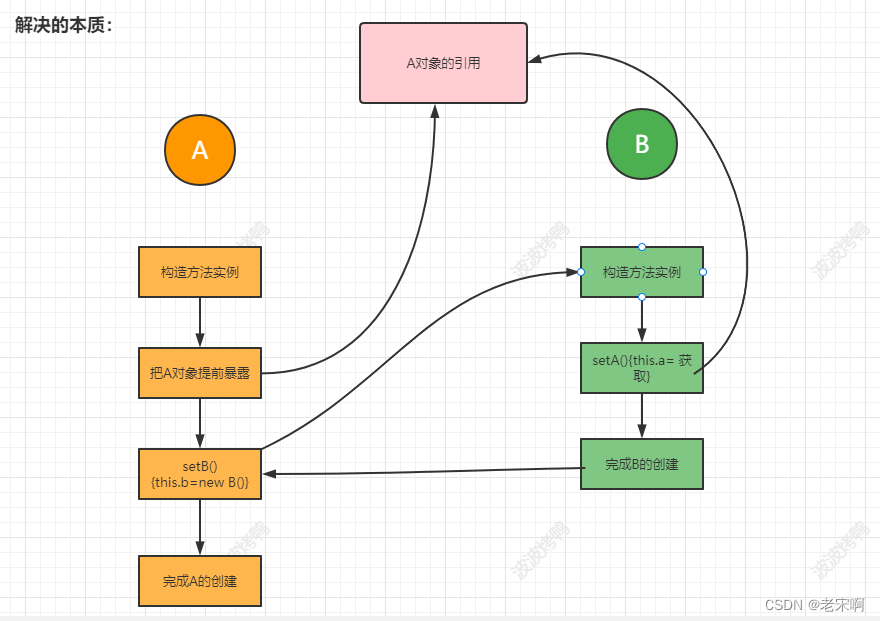
Spring循环依赖
声明周期的核心: 创建对象和属性填充
基于前面案例的了解,我们知道肯定需要在调用构造方法方法创建完成后再暴露对象,在Spring中提供了三级缓存来处理这个事情,对应的处理节点如下图:

对应源码的处理流程:
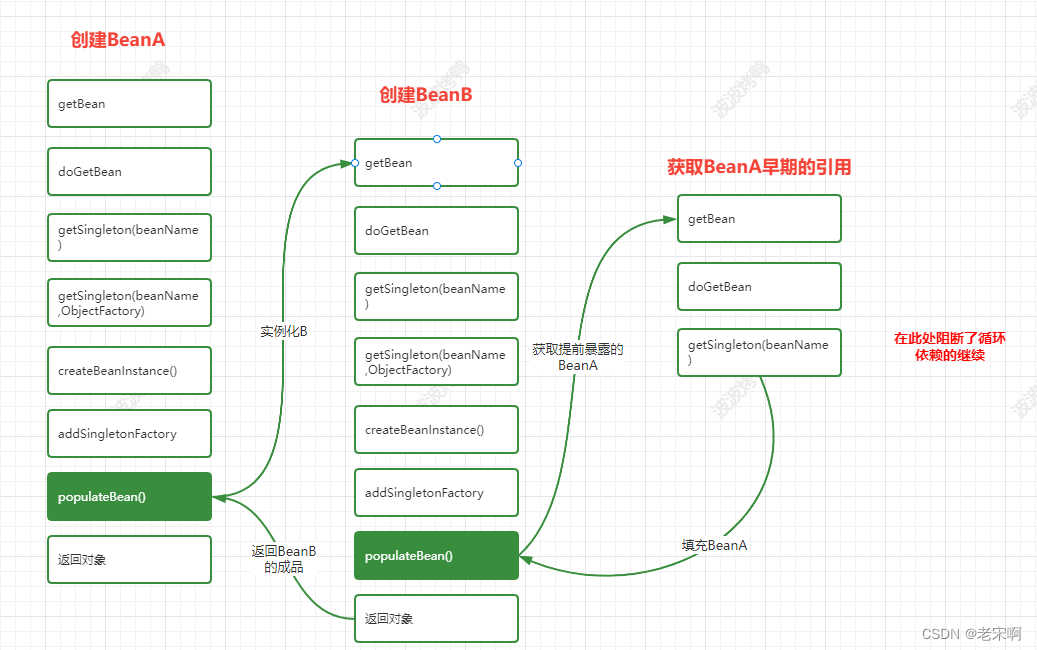
Spring生命周期
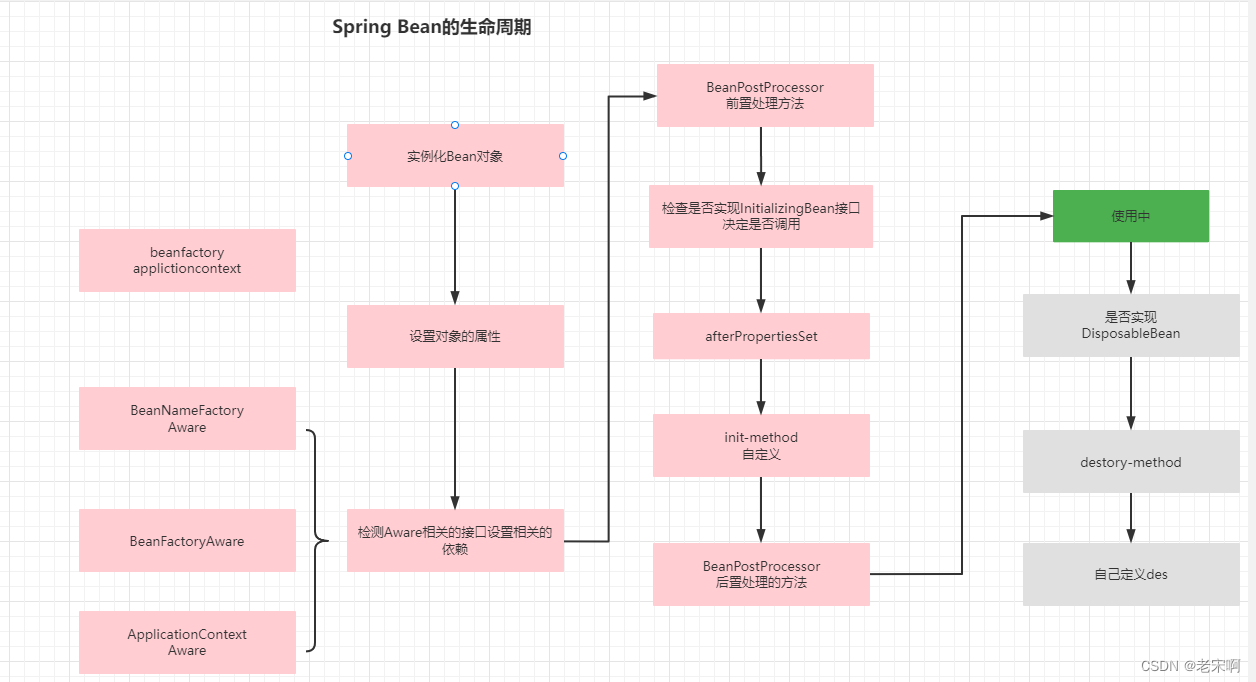
Spring的Bean的作用域
| 作用域 | 解释 |
|---|---|
| singleton | IOC容器只会创建一个共享Bean,无论有多少个Bean引用它,都始终只指向一个Bean对象 |
| prototype | IOC容器每次都会创建一个新的实例Bean |
| request | 同一次Http请求会返回同一个实例,不同的Http请求则会创建新的实例,请求结束后实例销毁 |
| session | 同一次Http Session中容器会返回同一个实例,不同的Session请求则会创建新的实例,请求结束实例销毁 |
| global-session | 一个全局的Http Session中容器会返回同一个实例,仅在使用Portlet Context时生效 |
Autowired、Resource
相同点:都是对象的依赖注入的注解,都可以用于成员变量和方法上
不同点:
- 默认方式不同:Autowired是基于bean的类型去查找的,Resources是基于bean的name去查找的
- 注解来源不同:Autowired是Spring带的注解,Resources是JDK自带的注解
- 指定不同场景:Resources(name=“指定名”)= Autowired+Qualified(value=“xxx”)
forward和Redirect
| 区别 | forward | redirect |
|---|---|---|
| 地址栏 | 服务端内部重定向 | 发送一个状态码到浏览器,浏览器再次访问这个新地址 |
| 数据共享 | 共享数据 | 不共享数据 |
| 应用场景 | 比如:用户登录 | 比如:用户注销放回主页面 |
| 效率 | 高 | 低 |
| 次数 | 一次 | 两次 |
| 本质 | 服务端的行为 | 客户端的行为 |
IOC
概念:IOC也叫控制反转,将对象间的依赖关系交给Spring容器,使用配置文件来创建所依赖的对象,由主动创建对象改为了被动方式,实现解耦合。
使用方式:可以通过注解**@Autowired和@Resource**来注入对象, **context:annotation-config/**元素开启注解。被注入的对象必须被下边的四个注解之一标注:@Controller
、@Service、@Repository、@Component
底层原理:反射
装配流程:

AOP
概念:AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性
底层原理:动态代理
AOP中有如下的操作术语:
- Joinpoint(连接点): 类里面可以被增强的方法,这些方法称为连接点
- **Pointcut(切入点):**所谓切入点是指我们要对哪些Joinpoint进行拦截的定义
- **Advice(通知/增强):**所谓通知是指拦截到Joinpoint之后所要做的事情就是通知。
- **Aspect(切面):**是切入点和通知(引介)的结合
- **Introduction(引介):**引介是一种特殊的通知在不修改类代码的前提下,Introduction可以在运行期为类动态地添加一些方法或属性
- **Target(目标对象):**代(dai)理的目标对象(要增强的类)
- **Weaving(织入):**是把增强应用到目标的过程,把advice 应用到 target的过程
- **Proxy(代(dai)理):**一个类被AOP织入增强后,就产生一个结果代(dai)理类
@Aspect
@Component
public class LogAspect {
private final static Logger LOG = LoggerFactory.getLogger(LogAspect.class);
/** 定义一个切点 */
@Pointcut("execution(public * com.jiawa.*.controller..*Controller.*(..))")
public void controllerPointcut() {}
@Resource
private SnowFlake snowFlake;
@Before("controllerPointcut()")
public void doBefore(JoinPoint joinPoint) {
// logback自带的日志流水号
MDC.put("LOG_ID", String.valueOf(snowFlake.nextId()));
// 开始打印请求日志
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
Signature signature = joinPoint.getSignature();
String name = signature.getName();
// 打印请求信息
LOG.info("------------- 开始 -------------");
LOG.info("请求地址: {} {}", request.getRequestURL().toString(), request.getMethod());
LOG.info("类名方法: {}.{}", signature.getDeclaringTypeName(), name);
LOG.info("远程地址: {}", request.getRemoteAddr());
RequestContext.setRemoteAddr(getRemoteIp(request));
// 打印请求参数:aop是通过连接点来拿到参数的
Object[] args = joinPoint.getArgs();
// LOG.info("请求参数: {}", JSONObject.toJSONString(args));
Object[] arguments = new Object[args.length];
for (int i = 0; i < args.length; i++) {
if (args[i] instanceof ServletRequest
|| args[i] instanceof ServletResponse
|| args[i] instanceof MultipartFile) {
continue;
}
arguments[i] = args[i];
}
// 排除一些字段不打印:排除字段,敏感字段或太长的字段不显示
String[] excludeProperties = {"password", "file"};
PropertyPreFilters filters = new PropertyPreFilters();
PropertyPreFilters.MySimplePropertyPreFilter excludefilter = filters.addFilter();
excludefilter.addExcludes(excludeProperties);
LOG.info("请求参数: {}", JSONObject.toJSONString(arguments, excludefilter));
}
@Around("controllerPointcut()")
public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
long startTime = System.currentTimeMillis();
Object result = proceedingJoinPoint.proceed();
// 排除字段,敏感字段或太长的字段不显示
String[] excludeProperties = {"password", "file"};
PropertyPreFilters filters = new PropertyPreFilters();
PropertyPreFilters.MySimplePropertyPreFilter excludefilter = filters.addFilter();
excludefilter.addExcludes(excludeProperties);
LOG.info("返回结果: {}", JSONObject.toJSONString(result, excludefilter));
LOG.info("------------- 结束 耗时:{} ms -------------", System.currentTimeMillis() - startTime);
return result;
}
/**
* 使用nginx做反向代理,需要用该方法才能取到真实的远程IP
* @param request
* @return
*/
public String getRemoteIp(HttpServletRequest request) {
String ip = request.getHeader("x-forwarded-for");
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("WL-Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
return ip;
}
}
动态代理
概念:程序运行时生成代理类
| 代理方式 | 实现 | 优点 | 缺点 | 特点 |
|---|---|---|---|---|
| JDK静态代理 | 代理类和委托类实现同一接口,代理类硬编码接口 | 简单 | 重复编码,不易修改 | 无 |
| JDK动态代理 | 继承InvoktionHandle接口,重写invoke方法 | 代码复用率高,不需重复编码 | 只能够代理实现了接口的委托类 | 底层使用反射 |
| Cglib动态代理 | 继承MethodInterceptor,重写intercept方法 | 可以对类/接口增强,且被代理类无需实现接口 | 不能对final类或方法代理 | 底层是字节码调用ASM框架生成新的类 |
JDK动态代理
- 被代理类和其接口
public interface UserManager {
void addUser(String username,String password);
}
public class UserManagerImpl implements UserManager {
@Override
public void addUser(String username, String password) {
System.out.println("UserName:" + username + " PassWord:" + password);
}
}
- 继承InvoktionHandle接口,重写invoke方法
- 重点学习JDK动态代理类的书写模版,即下面的序号处是通用模版
public class JDKProxy implements InvocationHandler {
// 代理类继承InvocationHandler,重写invoke方法
// 1.获取被代理对象
private Object target;
public JDKProxy(Object target) {
this.target = target;
}
// 2.代理类获取被代理角色
private Object getProxyInstance() {
// 返回给代理类和被代理增强的接口,并生成被代理对象实例
return Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),// 第二个参数说明JDK动态代理只针对接口增强
this);
}
// 3.代理类重写invoke方法
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 增强方法1
System.out.println("增强方法1:JDK动态代理开始");
// 被代理对象接口实现的的返回值 = 固定写法
Object result = method.invoke(target, args);
// 增强方法2
System.out.println("增强方法2:JDK动态代理结束");
return result;
}
// 4.测试线程
public static void main(String[] args) {
UserManagerImpl userManager = new UserManagerImpl();
JDKProxy jdkProxy = new JDKProxy(userManager);
UserManager user = (UserManager) jdkProxy.getProxyInstance();
user.addUser("张三", "123");
}
}
Cglib动态代理
- 被代理类
public class UserCglibServiceImpl {
public void hobby() {
System.out.println("跳舞");
}
}
- 继承MethodInterceptor,重写intercept方法
public class UserCglibServiceProxy implements MethodInterceptor {
// 1.设置被代理对象
private Object target;
public UserCglibServiceProxy(Object target) {
this.target = target;
}
// 2.创建被代理对象
public Object getProxyInstance() {
// 工具类
Enhancer en = new Enhancer();
// 设置被代理作为父类
en.setSuperclass(target.getClass());
// 将本类设置为回调函数
en.setCallback(this);
// 返回被代理对象
return en.create();
}
// 3.重写intercept方法,用法和JDK动态代理一样
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
System.out.println("增强方法1:cglib动态代理开始");
Object invoke = method.invoke(target, args);
System.out.println("增强方法2:cglib动态代理结束");
return invoke;
}
// 4.测试线程
public static void main(String[] args) {
UserCglibServiceImpl target1 = new UserCglibServiceImpl();
UserCglibServiceImpl target2 =(UserCglibServiceImpl) new UserCglibServiceProxy(target1).getProxyInstance();
target2.hobby();
}
}
Spring事务
- 编程式事务管理:使用TransactionTemplate实现。
- 声明式事务管理:建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。事务选择:
- 优点:非侵入式的开发方式,使业务代码不受污染,只要加上注解就可以获得完全的事务支持
- 缺点:最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。
Spring事务传播行为
| 事务传播行为 | 解释 |
|---|---|
| propagation_required | 有事务,就加入当前事务;没有事务,就创建新的事务(默认) |
| propagation_required_new | 无论有没有事务,都创建新的事务 |
| propagation_supports | 有事务,就加入当前事务;没有事务,就以非实物执行 |
| propagation_not_supported | 有事务,将当期事务挂起,以非事务执行;没有事务,以非实物执行 |
| propagation_mandatory | 有事务,就加入当前事务;没有事务,就抛出异常 |
| propagation_never | 有事务,抛出异常,以非事务执行;没有事务,以非事务执行 |
| propagation_nested | 有事务,则嵌套事务内执行;没有事务,就新建一个事务 |
Spring事务的隔离级别和MySQL事务的隔离级别类似,依然存在读未提交,读已提交,可重复读以及串行四种隔离级别。
| 隔离级别 | 脏读 | 不可重复度 | 幻读 |
|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read Commited) | 不可能 | 可能 | 可能 |
| 可重复读(默认级别,Repeatable Read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
| 事务并发问题 | 描述 |
|---|---|
| 更新丢失 | 最后的更新覆盖了其他事务所做的更新 |
| 脏读 | 事务A读取到了事务B修改但未提交的数据。此时,如果事务B回滚事务,事务A读取的数据就无效,不满足一致性要求。 |
| 不可重复读 | 事务A内部的相同查询语句在不同时刻读出的结果不一致,不符合隔离性。 |
| 幻读 | 事务A读取到了事务B提交的新增数据,不符合隔离性 |
SpringMVC的流程


SpringBoot
自动装配过程
主要启动类中的@SpringBootApplication注解封装了@SpringBootConfiguration、@EnableAutoConfiguration
@SpringBootApplication// 点进去
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
// 四大元注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
// 以下是SpringbootApplication重要的3个注解
@SpringBootConfiguration
@EnableAutoConfiguration// 这个就是自动装配的灵魂注解
@ComponentScan
@SpringBootConfiguration
说明这是一个Springboot的配置文件,里面的 @Component ,说明启动类本身也是Spring中的一个组件而已,负责启动应用!
@EnableAutoConfiguration
自动装配的核心注解,点进去看的AutoConfigurationImportSelector是核心中的核心
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
@Import(AutoConfigurationImportSelector.class) ,找到getCandidateConfigurations方法
getCandidateConfigurations方法:获得候选的配置
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
找到SpringFactoriesLoader.loadFactoryNames,点进去,找到loadSpringFactories方法
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
//获得classLoader
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
...
}
org.springframework.boot.test.autoconfigure/META-INF/spring.factories:就是预存的配置文件

自动装配总结
-
自动配置真正实现是从classpath中搜寻所有的
META-INF/spring.factories配置文件 ,并将其中对应的org.springframework.boot.autoconfigure.包下的配置项,通过反射实例化为对应标注了 @Configuration的JavaConfig形式的IOC容器配置类 , 然后将这些都汇总成为一个实例并加载到IOC容器中。 -
用户如何书写yml配置,需要去查看
META-INF/spring.factories下的某自动配置,如HttpEncodingAutoConfigurationEnableConfigrutionProperties(xxx.class):表明这是一个自动配置类,加载某些配置XXXProperties.class:封装配置文件中的属性,yam中需要填入= 它指定的前缀+方法


数据库
MySQL基础架构
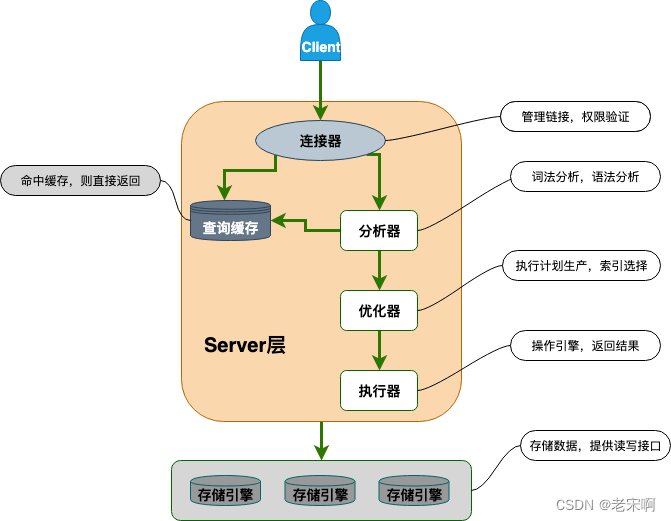
Redo log
写数据库时先做Redo log = 写前保存日志
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
BinLog
追加写的形式,保存所有的逻辑操作
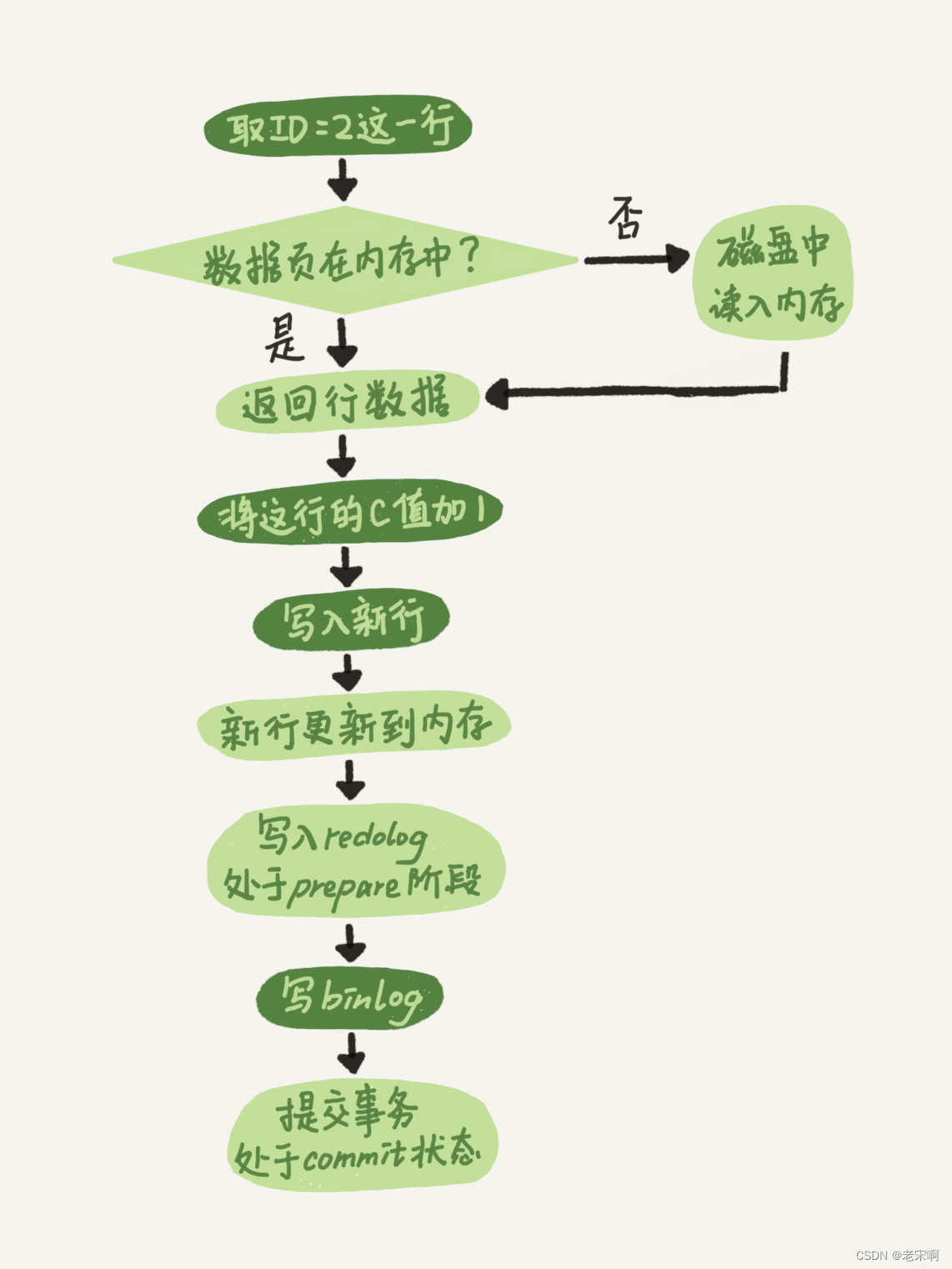
两阶段提交:redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
存储引擎
| 存储引擎 | 解释 |
|---|---|
| InnoDB | 支持事务、行级锁定和外键,Mysql5.5.5之后默认引擎 |
| MyISAM | 较高的插入、查询速度,但不支持事务。Mysql5.5.5之前的默认引擎 |
| Memory | 基于散列,存储在内存中,对临时表有用。常用于存放临时数据 |
| Archive | 支持高并发的插入操作,但是本身不是事务安全的。常用存储归档数据 |
MyISAM
MySQL5.5.5之前的默认引擎,不支持事务、行级锁和外键。
优点:查询快
缺点:更新慢且不支持事务处理
主键索引存储在.myi文件中,叶子节点存储的是主键在磁盘的内存地址,再去.myd文件查数据(与InnoDB的区别)
InnoDB
目前Mysql默认引擎,支持事务、回滚、崩溃修复、多版本并发控制、事务安全。
底层数据结构是B+树,B+树的每个节点都对应InnoDB的一个Page,Page大小是固定的,一般设定为16k。非叶子结点只有键值,叶子节点包含完整的数据
InnoDB和MyISAM区别
| InnoDB和MyISAM区别 | InnoDB | MyISAM |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 锁 | 行级锁和表锁 | 表级锁 |
| MVCC | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 行数 | 不保存 | 内置计数器,保存行数 |
| 概念 | 数据和索引都存储在.idb文件上 | 索引存在.myi上,数据存在.myd上 |
| 特性 | 支持事务、外键、恢复 | 优点是读取数据快,缺点是更新数据慢 |
三大范式
| 三大范式 | 解释 | 例子 |
|---|---|---|
| 第一范式 | 每列都是不可再分的原子操作 | 地址字段可以再细分为国家+省+市等,就不符合第一范式 |
| 第二范式 | 非主键字段不能对主键产生部分依赖 | 订单表中包含产品字段,就不符合第二范式 |
| 第三范式 | 非主键字段不能对非主键产生传递依赖 | 订单表中包含顾客表的主键和顾客表其他字段,就不符合第三范式 |



ACID原则
| ACID原则 | 解释 |
|---|---|
| 原子性(A) | 事务是一个完整操作,参与事务的逻辑单元要么都执行,要么都不执行 |
| 一致性 (B) | 在事务执行完毕后,数据都必须处于一致的状态 |
| 隔离性 (C) | 对数据进行修改的所有并发实发都会彼此隔离的,它不应以任何方式依赖或影响其他事务 |
| 持久性 (D) | 在事务操作完成后,对数据的修改将持久化到永久存储中 |
Mysql底层数据结构
Mysql底层使用B+树,原因如下:
(1)减少IO操作:索引文件很大,不能全部存储在内存中,只能存储到磁盘上,因此索引的数据结构要尽量减少查找过程中磁盘 I/O 的存取次数;
(2)降低检索次数:数据库系统利用了磁盘预读原理和磁盘预读,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。而 B + 树的高度是 2~4,检索一次最多只需要访问 4 个节点(4 次,即树的高度)。
为什么不用B树作为底层数据结构:
| 名称 | B+树 | B树 |
|---|---|---|
| 非叶子结点 | 只存索引 | 索引+数据,查找效率较低 |
| 叶子节点 | 索引+数据;并且可以向后遍历 | 索引+数据;不能向后遍历 |
索引类型
| Mysql索引类型 | 解释 |
|---|---|
| 普通索引 | 表中普通列构成的索引,没有任何限制 |
| 唯一索引 | 必须唯一,允许有空值。如果是组合索引,列值的组合必须唯一 |
| 主键索引 | 特殊的唯一索引,根据主键建立索引,不能为空和重复 |
| 全文索引 | =倒排索引,快速匹配文档的方式 |
| 组合索引 | 多个列建立的索引,这多个列中的值不允许有空值 |
注意:聚簇索引和非聚簇索引不是索引类型,是一种存储数据的方式!
最左前缀原则
概念:组合索引使用原则
存储原则:最左前缀原理(左到右,依次大小比较)
非常重要:查询时,是怎样使用到了该联合主键?
- 必须先定位最左字段,才能是正确使用了联合索引,比如联合主键如下图所示,只能是
where name =XX开头才能走联合索引,否则会失效。
总结:判断是否使用联合索引,联想下面这张图是否能走!


事务隔离级别
事务个隔离级别越高,并发问题越少,但是付出的代价也越大
show variables like 'tx_isolation';# 查看隔离级别
set tx_isolation = 'REPEATABLE-READ';# 默认隔离级别就是可重复读,Spring框架如果没有指定也是可重复读
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read Commited) | 不可能 | 可能 | 可能 |
| 可重复读(默认级别,Repeatable Read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
| 事务并发问题 | 描述 |
|---|---|
| 更新丢失 | 最后的更新覆盖了其他事务所做的更新 |
| 脏读 | 事务A读取到了事务B修改但未提交的数据。此时,如果事务B回滚事务,事务A读取的数据就无效,不满足一致性 |
| 不可重复读 | 事务A内部的相同查询语句在不同时刻读出的结果不一致,不符合隔离性。 |
| 幻读 | 事务A读取到了事务B提交的新增数据,不符合隔离性 |
事务7大传播行为
| 事务传播行为 | 解释 |
|---|---|
| propagation_required | 有事务,就加入当前事务;没有事务,就创建新的事务(默认) |
| propagation_required_new | 无论有没有事务,都创建新的事务 |
| propagation_supports | 有事务,就加入当前事务;没有事务,就以非实物执行 |
| propagation_not_supported | 有事务,将当期事务挂起,以非事务执行;没有事务,以非实物执行 |
| propagation_mandatory | 有事务,就加入当前事务;没有事务,就抛出异常 |
| propagation_never | 有事务,抛出异常,以非事务执行;没有事务,以非事务执行 |
| propagation_nested | 有事务,则嵌套事务内执行;没有事务,就新建一个事务 |
数据库优化
-
应用层架构优化。核心是减少对数据库的调用次数,本质上是从业务应用层来审视流程是否合理,常用的方案有:
- 引入缓存,虚拟一层中间层,减少对数据库的读写;
- 将多次单个调用改为批量调用,比如说循环十次主键 select * FROM t where id = 'xx’改为使用 IN 一性次读取 select * FROM t where id IN (‘xx’,‘xx’,…);
- 使用搜索引擎。
-
数据库架构优化。核心是优化各种配置,提升数据库的性能,可分为:
- 优化 SQL 及索引,以达到减少数据访问、返回更少数据、减少交互次数等目标。常用的手段包括:创建并正确地使用索引(比如说减少回表查询)、优化执行计划、数据分页处理、只取需要的字段、慢查询优化、使用搜索引擎等;
- 优化数据库表结构。常用的的手段包括:使用占用空间最小的数据类型、使用简单的数据类型、尽可能地使用 NOT NULL 定义字段、尽量少使用 text 字段、分库分表等;
- 优化系统配置。包括操作系统的配置优化和数据库的配置优化。
- 操作系统优化。数据库是基于操作系统(多为 Linux 系统)的,所以对于合理使用操作系统也会影响到数据库的性能。比如将数据库服务器应和业务服务器隔离、或者设置 net.ipv4.tcp_max_syn_backlog = 65535 以增加 tcp 支持的队列数等等;
- 数据库配置文件优化,以 MySQL 配置为例,可以修改 innodb_buffer_pool_size(设置数据和索引缓存的缓冲池)、max_connections 等参数。
- 优化硬件配置。比如说使用更好的服务器、更快的硬盘、更大的内存等等。
Myql优化-索引失效
- 条件中有 or;
- like 查询(以 % 开头);
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引;
- 对列进行函数运算(如 where md5 (password) = “xxxx”);
- 负向查询条件会导致无法使用索引,比如 NOT IN,NOT LIKE,!= 等;
- 对于联合索引,不是使用的第一部分 (第一个),则不会使用索引(最左匹配);
- 如果 mysql 评估使用全表扫描要比使用索引快,则不使用索引
- 工作我遇到的慢查询:1. Mybatis 表和字段是否取别名。2. 数据同步,或者迁移时候,max(lastId)是更好的方式。
Redis
答:redis(Remote Dictionary Server远程字典服务),是一款高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库。因为数据都在内存中,所以运行速度快。redis支持丰富的数据类型并且支持事务,事务中的所有命令会被序列化、按顺序执行,在执行的过程中不会被其他客户端发送来的命令打断。
数据类型
5种基本类型:String、Hash、List、Set、ZSet、
3种特殊类型:BitMap、HyperLogLog和Geospatial这8种数据类型。
以下为前5种常见的类型使用场景、底层原理
| 名称 | 解释 | 场景 | 底层 |
|---|---|---|---|
| String | 最常用 | 计数功能,比如微博数等 | 动态字符串(SDS) |
| Hash | value也是一个键值对 | 用于存储对象。比如我们可以 hash 数据结构来存储用户信息,商品信息等等 | 字典、压缩列表 |
| list | 一个链表集合,可以重复元素 | 可以做简单的消息队列的功能,比如论坛点赞人列表、微博粉丝列表等;另外还可以利用 lrange 命令,可以从某个元素开始读取多少个元素,实现简单的高性能分页,类似微博那种下拉不断分页的东西,性能极佳,用户体验好 | 压缩列表、双端链表 |
| set | 一个无序集合,且其中的元素不重复 | 全局去重的功能,比如说是否给帖子点赞数;也可以判断某个元素是否在 set,比如说判断是否给某个回复点赞。另外还可以利用交集、并集、差集等操作来支撑更多的业务场景,比如说找出两个微博 ID 的共同好友等; | 字典、整数集合 |
| zset | 相比 set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列 | 可以用于取排行榜 top N 的用户 | 压缩列表、跳跃表和字典 |

Redis单线程什么这么快?
Redis 通过IO 多路复用程序 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
这样的好处非常明显: I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)。
在分布式环境下,Redis性能瓶颈主要体现在网络延迟上。Redis请求响应模型如下
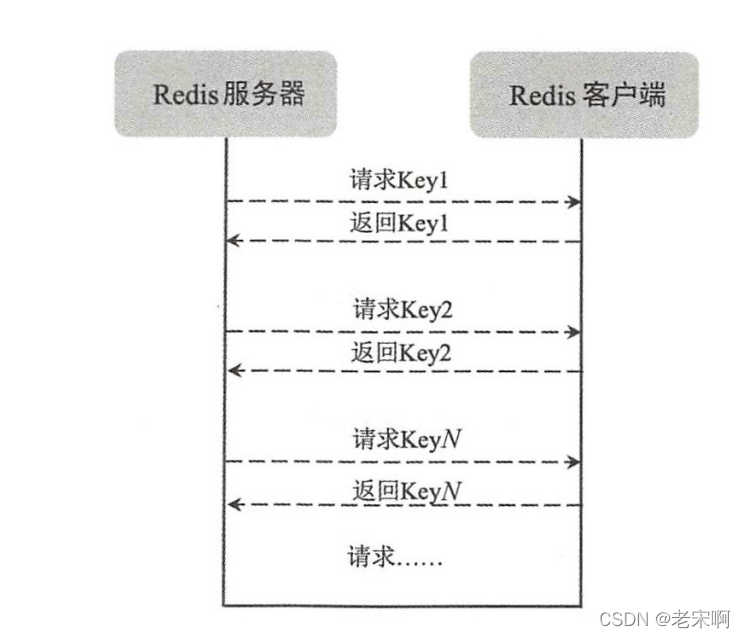

AOF
宕机了,为了避免数据丢失。提出了写后日志AOF,默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启。
写后日志:保证数据丢失后,通过写后日志恢复数据。
三种写回策略: Always、Everysec 和 No,这三种策略在可靠性上是从高到低,而在性能上则是从低到高。
日志过大:会重写AOF,方法是多条命令会优化成一条。
AOF重写会阻塞吗?:不会,一处拷贝,两处日志(正在操作的记录缓存日志,正在拷贝新AOF的缓存日志)
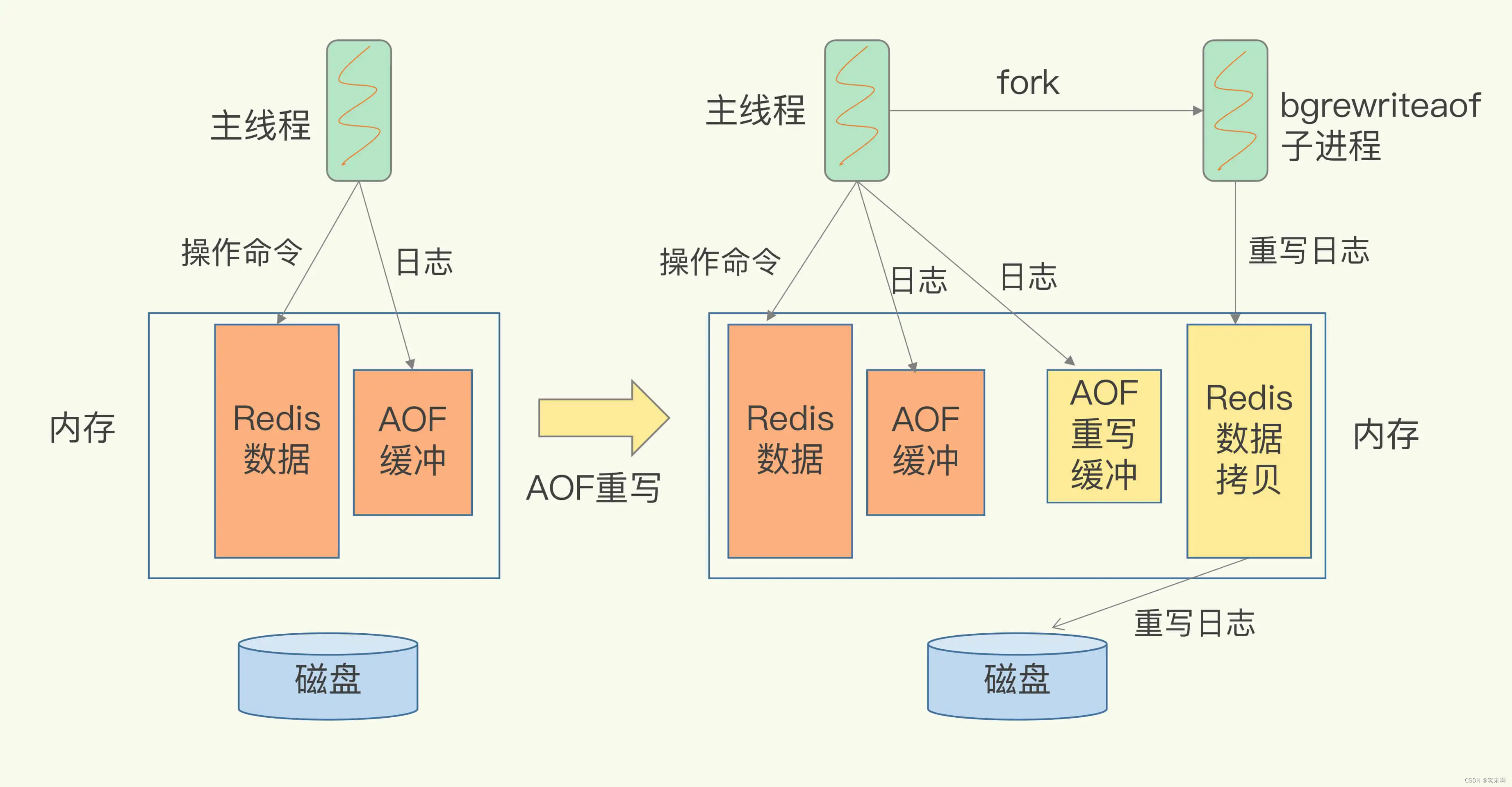
RDB
宕机时,快速恢复:RDB日志(默认方法)
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。save:在主线程中执行,会导致阻塞;bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
正常写数据与写RDB会阻塞吗?
答:为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
RDB和AOF区别
| 持久化方式 | RDB(Redis DataBase) | AOF(Append Of File) |
|---|---|---|
| 概念 | 在指定时间间隔内对数据进行快照存储。 | AOF记录对服务器的每次写操作,在Redis重启时会重放这些命令来恢复原数据。AOF命令以Redis协议追加和保持每次写操作到文件末尾,Redis还能对AOF文件进行后台重写 |
| 特点 | 优点是文件格式紧凑,方便进行数据传输和数据恢复,适合存储大量数据,性能最好;缺点是安全性低 | 优点是数据安全,同时AOF文件是日志格式,更容易被操作;缺点是速度慢,AOF文件较大 |
Redis三种集群模式




缓存雪崩
缓存雪崩:同一时刻,缓存大量失效,导致大量原本应该走缓存的请求去查询数据库,给数据库造成大量压力,容易使其宕机
- 原因:过期失效的话
- 设置不同的过期时间:将缓存过期时间分散开,比如说设置过期时间时再加上一个较小的随机值时间,使得每个 key 的过期时间,不会集中在同一时刻失效。
- 服务降级:非核心数据返回null。核心数据查缓存
- 原因:Redis宕机的话
- 服务熔断:业务应用调用缓存接口时,缓存客户端并不把请求发给 Redis 缓存实例,而是直接返回,等到 Redis 缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。
- 请求限流: 业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。
- 事前预防:以上2种是事后诸葛亮,Redis可以采用主从/哨兵等集群模式监听状态,如果发生宕机,立马切换。
缓存击穿
缓存击穿:针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求 。
解决办法:不设置过期时间,Redis 数万级别的高吞吐量可以很好地应对大量的并发请求访问
缓存穿透
缓存穿透:缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时,应用也无法从数据库中读取数据再写入缓存,来服务后续请求,这样一来,缓存也就成了“摆设”,如果应用持续有大量请求访问数据,就会同时给缓存和数据库带来巨大压力
解决办法:
- 布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,在查询的时候先去布隆过滤器去查询 key 是否存在,不存在的 key 就直接返回;
- 缓存空值:如果一个查询结果为null,仍然把该null作为value存到缓存层中,但设置它的过期时间很短,当用户再次请求相同key时,缓存层直接返回该null不走数据库查询,减轻数据库压力
- 前段校验合法性:前端防止恶意请求。
布隆过滤器
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
可以用guvua包自带的布隆过滤器,引入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
示例伪代码:
import com.google.common.hash.BloomFilter;
//初始化布隆过滤器
//1000:期望存入的数据个数,0.001:期望的误差率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000, 0.001);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.mightContain(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
设计一个RPC
- 注册中心:注册中心负责服务地址的注册与查找,相当于目录服务
- 网络传输:既然我们要调用远程的方法,就要发送网络请求来传递目标和方法的信息的参数等数据到服务提供端。
- 序列化与反序化:要在网络传输数据,设计序列化
- 动态代理:屏蔽远程方法的调用细节。
- 负载均衡:避免单个服务器响应在同一请求,容易造成服务器宕机、崩溃等问题
- 传输协议:这个协议是客户端(服务消费方)和服务端(服务提供方)交流的基础,私有。
常考算法
排序算法
归并排序
- 原地排序:空间复杂度为O(n)
- 稳定性:稳定的
- 时间复杂度:O(nlogn)Ï
public class Solution {
private int res;
/**
* 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
* 归并排序法,原理是利用nums[i]>nums[j],那么[i,mid]中都是逆序对个数
*/
public int reversePairs(int[] nums) {
int[] temp = new int[nums.length];
res = 0;
mergeSort(nums, 0, nums.length - 1, temp);
return res;
}
private void mergeSort(int[] nums, int l, int r, int[] temp) {
if (l >= r) {
return;
}
int mid = l + (r - l) / 2;
mergeSort(nums, l, mid, temp);
mergeSort(nums, mid + 1, r, temp);
if (nums[mid] > nums[mid + 1]) {
merge(nums, l, mid, r, temp);
}
}
private void merge(int[] nums, int l, int mid, int r, int[] temp) {
System.arraycopy(nums, l, temp, l, r - l + 1);
int p = l, q = mid + 1;
for (int i = l; i <= r; i++) {
if (p > mid) {
nums[i] = temp[q++];
} else if (q > r) {
nums[i] = temp[p++];
} else if (temp[p] <= temp[q]) {
// <=区域不会形成逆序对,所以和归并排序过程一样
nums[i] = temp[p++];
} else {
// 3,4,1,2
// p到mid中间元素的个数,与q构成逆序对
res += mid - p + 1;
nums[i] = temp[q++];
}
}
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] arr = {3, 4, 1, 2};
System.out.println(solution.reversePairs(arr));
}
}
快速排序
- 原地排序:空间复杂度为O(logn)
- 稳定性:不稳定的
- 时间复杂度:O(nlogn)
public class QuickSort {
/**
* 快速排序
* 与寻找第k大的数做比较
*/
public static void quickSort(int[] arr) {
// random作为参数一致传递下去
Random random = new Random();
quickSort(arr, 0, arr.length - 1, random);
}
private static void quickSort(int[] arr, int l, int r, Random random) {
// 递归结束条件:显然只剩一个数时,递归结束
if (l >= r) {
return;
}
// 先划分区间
int p = partition(arr, l, r, random);
// 左边递归排序
quickSort(arr, l, p - 1, random);
// 右边递归排序
quickSort(arr, p + 1, r, random);
}
/**
* 原地分区函数
*/
private static int partition(int[] arr, int l, int r, Random random) {
int p = l + random.nextInt(r - l + 1);
// p位置元数移动到l位置,让交换后的arr[l]作为基准,划分数组
swap(arr, l, p);
int i = l + 1, j = r;
while (true) {
while (i <= j && arr[i] < arr[l]) {
i++;
}
while (i <= j && arr[j] > arr[l]) {
j--;
}
if (i >= j) {
break;
}
swap(arr, i, j);
i++;
j--;
}
// 由于i++,j--操作,j指向<=arr[p]的最后一个位置,交换j和l位置元素
swap(arr, l, j);
return j;
}
private static void swap(int[] arr, int i, int j) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
比较学习:查找数组中第k大的数
public class Solution {
/**
* 查找数组中第k大的数
*/
public int findKth(int[] a, int n, int K) {
if (a == null || a.length == 0 || a.length < K) {
return -1;
}
return quickSortK(a, n, K, 0, n - 1);
}
private int quickSortK(int[] arr, int n, int k, int l, int r) {
int i = l;
int j = r;
while (i < j) {
// 这里以arr[l]为基准,必须先走j,因为j先走一步的话,会先来到<arr[l]的最后一个数,此时交换i,j位置就不会出错
// 如果以arr[r]为基准,必须先走i,因为i先走一步的话,会先来到>arr[l]的最后一个数,此时交换i,j位置就不会出错
while (i < j && arr[j] >= arr[l]) {
j--;
}
while (i < j && arr[i] <= arr[l]) {
i++;
}
swap(arr, i, j);
}
swap(arr, i, l);
// 快排使得数组从小到大排序
// 第1大的数 = 第n-1洗标的数
// 第k大的数 = 第n-k下标的数
if (i == n - k) {
return arr[i];
} else if (i < n - k) {// <,左边界前进
return quickSortK(arr, n, k, i + 1, r);
} else {// >,右边界后退
return quickSortK(arr, n, k, l, i - 1);
}
}
private void swap(int[] arr, int i, int j) {
if (i == j) {
return;
}
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] arr = {10, 10, 9, 9, 8, 7, 5, 6, 4, 3, 4, 2};
int n = arr.length;
int k = 3;
int res = solution.findKth(arr, n, k);
System.out.println(res);
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
堆排序
- 建立大根堆
public class MaxHeapSort {
// 大根堆
public static void heapSort(int[] arr) {
if (arr.length < 2) {
return;
}
// 从最右子树开始建立大根堆,堆顶保持最小值
for (int parent = (arr.length - 2) / 2; parent >= 0; parent--) {
heapify(arr, parent, arr.length);
}
// 大根堆依次将堆顶元素放回数组末尾
for (int i = arr.length - 1; i >= 0; i--) {
swap(arr, 0, i);
heapify(arr, 0, i);
}
}
// 大根堆,堆化操作
private static void heapify(int[] arr, int parent, int n) {
while (2 * parent + 1 < n) {
int left = 2 * parent + 1;
if (left + 1 < n && arr[left + 1] < arr[left]) {
left++;
}
if (arr[parent] <= arr[left]) {
break;
}
swap(arr, parent, left);
parent = left;
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
int[] arr = {4, 5, 1, 6, 6};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
}
- 建立小根堆
public class MinHeapSort {
// 小根堆
public static void heapSort(int[] arr) {
if (arr.length < 2) {
return;
}
// 小根堆,堆顶保持最大值
for (int parent = (arr.length - 2) / 2; parent >= 0; parent--) {
heapify(arr, parent, arr.length);
}
// 将堆顶最大值依次放回数组末尾
for (int i = arr.length - 1; i >= 0; i--) {
swap(arr, 0, i);
heapify(arr, 0, i);
}
}
private static void heapify(int[] arr, int parent, int n) {
while (2 * parent + 1 < n) {
int left = 2 * parent + 1;
if (left + 1 < n && arr[left + 1] > arr[left]) {
left++;
}
if (arr[parent] >= arr[left]) {
break;
}
swap(arr, parent, left);
parent = left;
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
int[] arr = {4, 5, 1, 6, 6};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
}
数组
LC88_合并两个有序数组
public class Solution1 {
/**
* 合并两个有序数组
* 不需要辅助数组,原地修改,因为nums1足够长
*/
public void merge(int[] nums1, int m, int[] nums2, int n) {
int p = m - 1;
int q = n - 1;
int index = m + n - 1;
while (p >= 0 && q >= 0) {
nums1[index--] = nums1[p] < nums2[q] ? nums2[q--] : nums1[p--];
}
while (q >= 0) {
nums1[index--] = nums2[q--];
}
}
}
LC69_x的平方根
public class Solution {
/**
* x的平方根
* 输入:x = 8
* 输出:2
* 解释:8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
*/
public int mySqrt(int x) {
// base case:x是 0 or 1 时特殊判断
if (x <= 1) {
return x;
}
// 一个数的平方根:[1,x/2]
int left = 1;
int right = x / 2;
int res = 0;
while (left <= right) {
int mid = left + (right - left) / 2;
// mid*mid会越界,但是/mid,mid不能为0,所以left从1开始,right不会超过x/2
if (mid <= (x / mid)) {
res = mid;
left = mid + 1;
} else {
right = mid - 1;
}
}
return res;
}
public static void main(String[] args) {
Solution so = new Solution();
int x = 2;
System.out.println(so.mySqrt(x));
System.out.println((int) Math.sqrt(x));
}
}
补充:平方根精确到小数点后6位
public class CalSqrt {
/**
* 补充:平方根精确到小数点后6位
* 不同:LC69x的平方根,返回整数即可
*/
private final double ACCURACY = 0.000001;
/**
* 求一个数x的平方根,精确到小数点后6位
*/
public float calSqrt(int x) {
// 所有类型都为浮点型
float left = 0;
float right = x;
while (Math.abs(right - left) >= ACCURACY) {
float mid = left + (right - left) / 2;
float mid2 = mid * mid;
if (mid2 - x > ACCURACY) {
right = mid;
} else if (x - mid2 > ACCURACY) {
left = mid;
} else {
return mid;
}
}
return -1;
}
}
LC15_三数之和
public class Solution {
/**
* 三数之和
* 输入:nums = [-1,0,1,2,-1,-4]
* 输出:[[-1,-1,2],[-1,0,1]]
*/
public List<List<Integer>> threeSum(int[] nums) {
// sort + find:将数组排序后查找
if (nums == null || nums.length < 3) {
return new ArrayList<>();
}
List<List<Integer>> res = new ArrayList<>();
Arrays.sort(nums);
int n = nums.length;
// 三数之和,需要两重循环
// 第一重循环:固定数nums[i]
for (int i = 0; i < n - 2; i++) {
// 三数之和=0,如果排序后第一个数>0,必不存在
if (nums[i] > 0) {
return res;
}
// 排序后,i之前相同的数无需重复判断,需要去重
// 注意:不能是i之后的相同的数去重,因为i之后的数可以相同判断三数之和
// [-4,-1,-1,0,1,2]
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
// 优化1
if ((long) nums[i] + nums[i + 1] + nums[i + 2] > 0) {
break;
}
// 优化2
if ((long) nums[i] + nums[n - 2] + nums[n - 1] < 0) {
continue;
}
int left = i + 1;
int right = n - 1;
// 第二重循环:找两个数
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
if (sum < 0) {
left++;
} else if (sum > 0) {
right--;
} else {
res.add(Arrays.asList(nums[i], nums[left], nums[right]));
// 去重
while (left < right && nums[left] == nums[left + 1]) {
left++;
}
while (left < right && nums[right] == nums[right - 1]) {
right--;
}
left++;
right--;
}
}
}
return res;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {-1, 0, 1, 2, -1, -4};
System.out.println(solution.threeSum(nums));
}
}
字符串
LC3_最长无重复子串
public class Solution {
/**
* 无重复字符的最长子串
* 输入: s = "abcabcbb"
* 输出: 3
* 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
*/
public int lengthOfLongestSubstring(String s) {
if (s.length() < 1) {
return 0;
}
char[] cs = s.toCharArray();
// preMap:key=该字符,value=该字符串上一次出现的下标
int[] preMap = new int[256];
// 初始化map,每个字符上一次出现的下标为-1
for (int i = 0; i < 256; i++) {
preMap[i] = -1;
}
// cs[i-1]的最长无重复开始位置的前一个位置
int pre = -1;
// 当前位置的最长无重复长度
int curLen = 0;
int res = 0;
// 遍历cs
for (int i = 0; i < cs.length; i++) {
// pre始终指向最右边的位置,因为离i位置最近且中间没有重复元素
pre = Math.max(pre, preMap[cs[i]]);
curLen = i - pre;
res = Math.max(res, curLen);
preMap[cs[i]] = i;
}
return res;
}
public static void main(String[] args) {
Solution solution = new Solution();
String s = "abcabcbb";
System.out.println(solution.lengthOfLongestSubstring(s));
}
}
LC5_最长回文子串
public class Solution3 {
/**
* 最长回文子串
* 动态规划法:面试选这个解法
* 输入:s = "babad"
* 输出:"bab"
* 解释:"aba" 同样是符合题意的答案。
*/
public String longestPalindrome(String s) {
if (s.length() < 2) {
return s;
}
int n = s.length();
boolean[][] dp = new boolean[n][n];
for (int i = 0; i < n; i++) {
dp[i][i] = true;
}
int maxLen = 1;
int begin = 0;
// [j...i]
for (int i = 0; i < n; i++) {
for (int j = 0; j < i; j++) {
if (s.charAt(i) == s.charAt(j)) {
dp[j][i] = i - j + 1 <= 3 || dp[j + 1][i - 1];
} else {
dp[j][i] = false;
}
if (dp[j][i] && i - j + 1 > maxLen) {
maxLen = i - j + 1;
// 内层循环时j,初始位置是j
begin = j;
}
}
}
// substring第二个参数是begin+len;不是len
return s.substring(begin, begin + maxLen);
}
public static void main(String[] args) {
Solution3 solution3 = new Solution3();
String s = "babad";
System.out.println(solution3.longestPalindrome(s));
}
}
LC20_有效的括号
public class Solution {
/**
* 有效的括号
* 输入:s = "{[]}"
* 输出:true
*/
public boolean isValid(String s) {
if (s == null || s.length() <= 1) {
return false;
}
// 创建左右括号对应的map
Map<Character, Character> map = new HashMap<>(3) {{
put('{', '}');
put('[', ']');
put('(', ')');
}};
LinkedList<Character> stack = new LinkedList<>();
for (char c : s.toCharArray()) {
// 栈中只存左括号
if (map.containsKey(c)) {
stack.push(c);
} else {
// 匹配到右括号,就比对栈顶和当前右括号
if (stack.isEmpty() || map.get(stack.peek()) != c) {
return false;
}
stack.pop();
}
}
// 结果:判断栈是否为空
return stack.isEmpty();
}
}
LC22_括号生成
public class Solution {
/**
* 题目:数字n代表生成括号的对数,生成所有可能的并且有效的括号组合。
* 输入:n = 3
* 输出:["((()))","(()())","(())()","()(())","()()()"]
*/
public List<String> generateParenthesis(int n) {
List<String> res = new ArrayList<>();
// n对括号=会生成2n长的字符串,需要左括号数=右括号数=n
recursion(n, n, "", res);
return res;
}
private void recursion(int leftNeed, int rightNeed, String sub, List<String> res) {
if (leftNeed == 0 && rightNeed == 0) {
res.add(sub);
return;
}
// 还需要添加左括号
if (leftNeed > 0) {
recursion(leftNeed - 1, rightNeed, sub + "(", res);
}
// 还需要添加右括号:还需要左括号<还需要的右括号 = 已经生成的左括号>已经生成的右括号
if (leftNeed < rightNeed) {
recursion(leftNeed, rightNeed - 1, sub + ")", res);
}
}
}
LC647_回文子串
public class Solution {
/**
* 回文子串
* 回文字符串 是正着读和倒过来读一样的字符串。
* 子字符串 是字符串中的由连续字符组成的一个序列。
* 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
* 输入:s = "aaa"
* 输出:6
* 解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
*/
public int countSubstrings(String s) {
if (s == null || s.length() == 0) {
return 0;
}
int n = s.length();
// dp[i][j]:表示s[i,j]上是否是回文串
boolean[][] dp = new boolean[n][n];
int res = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j <= i; j++) {
// 只有一个字符
// 首位字符相同,长度<=3 || s[i+1,j-1]也是回文串
if (s.charAt(j) == s.charAt(i) && (i - j + 1 <= 3 || dp[j + 1][i - 1])) {
dp[j][i] = true;
res++;
}
}
}
return res;
}
public static void main(String[] args) {
Solution soltion = new Solution();
String s = "aaa";
System.out.println(soltion.countSubstrings(s));
}
}
栈和队列
LC232_用栈实现队列
public class MyQueue {
/**
* 用栈实现队列,一定是使用两个栈:stack1正常压入,stack2维持stack1的栈底到stack2的栈顶
*/
private LinkedList<Integer> stack1;
private LinkedList<Integer> stack2;
public MyQueue() {
stack1 = new LinkedList<>();
stack2 = new LinkedList<>();
}
public void push(int x) {
stack1.push(x);
}
public int pop() {
if (empty()) {
return -1;
}
// 栈1非空,栈2为空,往栈2压入数据
if (stack2.isEmpty()) {
pushStack2();
}
return stack2.pop();
}
public int peek() {
if (empty()) {
return -1;
}
// 栈1非空,栈2为空,往栈2压入数据
if (stack2.isEmpty()) {
pushStack2();
}
return stack2.peek();
}
public boolean empty() {
return stack1.isEmpty() && stack2.isEmpty();
}
/**
* 摊还时间复杂度
*/
private void pushStack2() {
while (!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
}
}
LC225_队列实现栈
public class MyStack {
/**
* 队列实现栈:可以用一个队列,模拟一个栈
*/
private Queue<Integer> queue;
public MyStack() {
queue = new LinkedList<>();
}
public void push(int x) {
// 保证后进的元素,维持在队列头部,便于出去
// 所以先记录之前队列的长度
int size = queue.size();
queue.add(x);
// 之前长度内的元素重新进入队列,让x保持在队头
for (int i = 0; i < size; i++) {
queue.add(queue.poll());
}
}
public int pop() {
return queue.poll();
}
public int top() {
return queue.peek();
}
public boolean empty() {
return queue.isEmpty();
}
}
LC150_逆波兰表达式求值
public class Solution {
/**
* tokens = ["2","1","+","3","*"],输出9
*/
public int evalRPN(String[] tokens) {
int[] stack = new int[tokens.length];
int index = -1;
for (String str : tokens) {
if (!"+-*/".contains(str)) {// 这里是contains,不是equals
stack[++index] = Integer.parseInt(str);
} else {
int b = stack[index--];// 先出栈的是b
int a = stack[index--];// 后出栈的是a,顺序一定不能错
int num = cal(a, b, str);
stack[++index] = num;
}
}
return stack[index];
}
private int cal(int a, int b, String op) {
if ("+".equals(op)) {
return a + b;
} else if ("-".equals(op)) {
return a - b;
} else if ("*".equals(op)) {
return a * b;
} else if ("/".equals(op)) {
return a / b;
}
return -1;
}
public static void main(String[] args) {
String[] tokens = {"2", "1", "+", "3", "*"};
Solution solution = new Solution();
System.out.println(solution.evalRPN(tokens));
}
}
链表
LC206_反转单链表
public class Solution {
/**
* 反转单链表
*/
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
}
LC142_环形链表
public class Solution {
/**
* LC142_判断环形链表II:
* 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回null
*/
public ListNode detectCycle(ListNode head) {
if (head == null || head.next == null || head.next.next == null) {
return null;
}
ListNode slow = head.next;
ListNode fast = head.next.next;
// 快指针走2步,慢指针走1步
while (fast != slow) {
if (fast.next == null || fast.next.next == null) {
return null;
}
fast = fast.next.next;
slow = slow.next;
}
// 以上代码=判断链表是否有环,快指针一旦遇到慢指针,说明肯定有环,让快指针重新指向头结点
fast = head;
// 快指针走1步,慢指针走1步
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
// 快慢指针一定会在第一个入环结点相遇,证明找wolai笔记
return fast;
}
}
NC3_链表的入环结点
public class Solution {
/**
* 返回单链表的入环结点
* 假设环前面有a个节点,环中有b个节点,快指针走f步,慢指针走s步
* 证明,为什么快指针第一次相遇慢指针后,要重回头结点,并且再次相遇慢指针后,必为入环结点
* 快指针一次走2步,慢指针一次走1步,必有 f = 2s,以及f = s + nb(n>=0,n是环中循环的次数)
* 则推出,s=nb,等式两边加上a则有 a+s = a+nb = 从头结点重新遍历到入环结点
*/
public ListNode EntryNodeOfLoop(ListNode pHead) {
if (pHead == null || pHead.next == null || pHead.next.next == null) {
return null;
}
ListNode fast = pHead.next.next;
ListNode slow = pHead.next;
// 快指针走2步,慢指针走1步
while (fast != slow) {
if (fast.next == null || fast.next.next == null) {
return null;
}
fast = fast.next.next;
slow = slow.next;
}
// fast重新指向头结点
fast = pHead;
// 快指针走1步,慢指针走1步
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}
}
二叉树
LC144_二叉树前序遍历
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
if (root == null) {
return new LinkedList<>();
}
LinkedList<TreeNode> stack = new LinkedList<>();
List<Integer> res = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
root = stack.pop();
res.add(root.val);
// 先序:先压右孩子,再压左孩子
if (root.right != null) {
stack.push(root.right);
}
if (root.left != null) {
stack.push(root.left);
}
}
return res;
}
}
LC145_二叉树后序遍历
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
if (root == null) {
return new LinkedList<>();
}
LinkedList<TreeNode> stack = new LinkedList<>();
LinkedList<TreeNode> temp = new LinkedList<>();
List<Integer> res = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
// 后续每次出栈,将结果进辅助栈,实现头右左倒序
temp.push(node);
// 要实现出栈是头右左,收集栈就要左右入栈
if (node.left != null) {
stack.push(node.left);
}
if (node.right != null) {
stack.push(node.right);
}
}
// 辅助栈出栈,头右左变成左右头
while (!temp.isEmpty()) {
res.add(temp.pop().val);
}
return res;
}
}
LC102_二叉树层次遍历
public class Solution {
/**
* 二叉树的层次遍历
*/
public List<List<Integer>> levelOrder(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
List<List<Integer>> res = new ArrayList<>();
while (!queue.isEmpty()) {
List<Integer> temp = new ArrayList<>();
// 难点:一层 一层的打印,需要从size--开始遍历队列
for (int i = queue.size(); i > 0; i--) {
TreeNode node = queue.poll();
temp.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
res.add(temp);
}
return res;
}
}
LC662_二叉树的最大宽度
public class Solution {
private int maxWidth;// 记录最大宽度
private Map<Integer, Integer> map;// 记录每一层的第一个结点(深度,0)
// 深度优先遍历
public int widthOfBinaryTree(TreeNode root) {
maxWidth = 0;
map = new HashMap<>();
// 根节点起始下标i,左孩子2*i+1,右孩子2*i+2
dfs(root, 0, 0);
return maxWidth;
}
private void dfs(TreeNode root, int depth, int pos) {
if (root == null) return;
// putIfAbsent():如果key是新key,就记录新key和新value
// 如果是老key,替换老key,但value还是沿用之前的老value
map.putIfAbsent(depth, pos);
// 最大宽度长度:当前节点下标-这一层第一个结点的下标+1
maxWidth = Math.max(maxWidth, pos - map.get(depth) + 1);
// 先遍历左子树,每一层的第一个结点都保存起始下标(深度,0)
dfs(root.left, depth + 1, 2 * pos + 1);
// 从叶子节点第一个开始算宽度
dfs(root.right, depth + 1, 2 * pos + 2);
}
}
LC98_验证二叉搜索树
public class Solution {
/**
* pre是会超过int类型的边界值,所以使用Long的边界值
*/
private long pre = Long.MIN_VALUE;
/**
* 验证是否是BST
* 中序递归法
*/
public boolean isValidBST(TreeNode root) {
// 空节点,是BST,返回true
if (root == null) {
return true;
}
// 左子树不是BST
if (!isValidBST(root.left)) {
return false;
}
// BST的中序遍历,当前节点的值必须>pre,否则为false
if (root.val <= pre) {
return false;
}
// 右子树是否是BST
return isValidBST(root.right);
}
/**
* 验证是否是BST
* 中序非递归
*/
public boolean isValidBST1(TreeNode root) {
if (root == null) {
return true;
}
LinkedList<TreeNode> stack = new LinkedList<>();
long pre = Long.MIN_VALUE;
while (!stack.isEmpty() || root != null) {
// 中序非递归遍历先把所有左子树入栈
if (root != null) {
stack.push(root);
root = root.left;
} else {
// 左子树到null就出栈,操作+入右子树
root = stack.pop();
if (root.val <= pre) {
return false;
} else {
pre = root.val;
}
root = root.right;
}
}
return true;
}
}
LC235_二叉搜索树的最近公共祖先
public class Solution1 {
/**
* 二叉搜索树的最近公共祖先
*/
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// 不改变原树结构
TreeNode cur = root;
while (true) {
if (cur.val < p.val && cur.val < q.val) {
cur = cur.right;
} else if (cur.val > p.val && cur.val > q.val) {
cur = cur.left;
} else {
break;
}
}
return cur;
}
}
LC236_二叉树的最近公共祖先
public class Solution {
/**
* 二叉树的最近公共祖先
*/
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) {
return root;
}
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 成功的base case:最近公共祖先,两者都不为空
if (left != null && right != null) {
return root;
}
return left != null ? left : right;
}
}
经典题
生成者消费者
- ReenTrantLock版
class MyResources2 {
private int num = 0;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
// 方式二:lock/condition+await+signalAll
//生产者,规定:生产一个,消费一个
public void productor() {
lock.lock();
try {
//1 判断,生产者等待的条件:产品数量等待消费,num>0
while (num != 0) {
condition.await();
}
//2 干活
num++;
System.out.println(Thread.currentThread().getName() + "\tnum值:" + num);
//3 通知唤醒
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
//消费者
public void consumer() {
lock.lock();
try {
//1 判断 多线程是while判断
while (num == 0) {
condition.await();
}
//2 干活:消费
num--;
System.out.println(Thread.currentThread().getName() + "\tnum值:" + num);
//3 通知唤醒
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
public class ProductorAndConsumerDemo {
public static void main(String[] args) {
//MyResources1 myResources = new MyResources1();
MyResources2 myResources = new MyResources2();
for (int i = 1; i <= 5; i++) {
new Thread(() -> {
try {
myResources.productor();
} catch (Exception e) {
e.printStackTrace();
}
}, "线程1").start();
}
for (int i = 1; i <= 5; i++) {
new Thread(() -> {
try {
myResources.consumer();
} catch (Exception e) {
e.printStackTrace();
}
}, "线程2").start();
}
}
}
线程1 num值:1
线程2 num值:0
线程1 num值:1
线程2 num值:0
线程1 num值:1
线程2 num值:0
线程1 num值:1
线程2 num值:0
线程1 num值:1
线程2 num值:0
LC41_接雨水
public class Solution {
/**
* 接雨水
* 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
* 输出:6
*/
public int trap(int[] arr) {
// 双指针
int left = 0, right = arr.length - 1;
// 桶高
int height = 0;
// 如果返回值是long,那么雨水量类型就是long
int water = 0;
while (left < right) {
// 更新当前桶高:左右指针对应的数组元素取最小
height = Math.max(height, Math.min(arr[left], arr[right]));
// 雨水量 += 当前桶高-当前左右最矮
water += arr[left] <= arr[right] ? (height - arr[left++]) : (height - arr[right--]);
}
return water;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1};
System.out.println(solution.trap(nums));
}
}
LC46_全排列
public class Solution {
/**
* 给定一个不含重复数字的数组 nums ,返回其所有可能的全排列 。
* 你可以 按任意顺序 返回答案。
* 输入:nums = [1,2,3]
* 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
*/
public List<List<Integer>> permute(int[] nums) {
if (nums == null || nums.length == 0) {
return new ArrayList<>();
}
List<List<Integer>> res = new ArrayList<>();
process(nums, 0, res);
return res;
}
private void process(int[] nums, int i, List<List<Integer>> res) {
if (i == nums.length) {
List<Integer> temp = new ArrayList<>();
for (int num : nums) {
temp.add(num);
}
res.add(temp);
// 由于是if+else形式,这里可以不用return返回
} else {
// 从i位置往后面临多个选择
for (int j = i; j < nums.length; j++) {
// 交换i,j位置
swap(nums, i, j);
process(nums, i + 1, res);
// 回溯:i,j位置归位
swap(nums, i, j);
}
}
}
private void swap(int[] nums, int i, int j) {
if (i == j) {
return;
}
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {1, 2, 3};
List<List<Integer>> permute = solution.permute(nums);
System.out.println(permute);
}
}
LC31_下一个排列
public class Solution {
/**
* 下一个排列
* 输入:nums = [4,5,2,6,3,1]
* 变化:nums->[4,5,3,6,2,1]
* 变化:nums->[4,5,3,1,2,6]
* 输出:[4,5,3,1,2,6]
*/
public void nextPermutation(int[] nums) {
if (nums.length < 2) {
return;
}
// 从后往前跳过降序,找到i位置使得nums[i]<nums[i+1]
int i = nums.length - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
// 如果i>=0存在,往后找第一个比它大的数交换
if (i >= 0) {
int j = nums.length - 1;
while (j >= i && nums[j] <= nums[i]) {
j--;
}
swap(nums, i, j);
}
// 逆置[i+1,n-1]的数,保证最靠近是最靠近原始数组的下一个排列数
reverseAfterI(nums, i + 1, nums.length - 1);
}
private void swap(int[] nums, int i, int j) {
if (i == j) {
return;
}
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
private void reverseAfterI(int[] nums, int start, int end) {
while (start < end) {
swap(nums, start, end);
start++;
end--;
}
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {4, 5, 2, 6, 3, 1};
solution.nextPermutation(nums);
System.out.println(Arrays.toString(nums));
}
}
LC200_岛屿数量
public class Solution {
/**
* 岛屿数量
* 输入:grid = [
* ["1","1","0","0","0"],
* ["1","1","0","0","0"],
* ["0","0","1","0","0"],
* ["0","0","0","1","1"]
* ]
* 输出:3
*/
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0) {
return 0;
}
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
// 遇到1,就将四周的岛屿染色为0;计数+1
if (grid[i][j] == '1') {
dfs(grid, i, j);
count++;
}
}
}
return count;
}
private void dfs(char[][] grid, int i, int j) {
if (i < 0 || i > grid.length - 1 || j < 0 || j > grid[0].length - 1 || grid[i][j] != '1') {
return;
}
// 染色,成0
grid[i][j] = '0';
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
}
public static void main(String[] args) {
Solution solution = new Solution();
char[][] grid = {{'1', '1', '0', '0', '0'}, {'1', '1', '0', '0', '0'}, {'0', '0', '1', '0', '0'}, {'0', '0', '0', '1', '1'},};
System.out.println(solution.numIslands(grid));
}
}
打家劫舍问题
LC198_打家劫舍
public class Solution {
/**
* 打家劫舍
* 输入:[2,7,9,3,1]
* 输出:12
* 解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
* 偷窃到的最高金额 = 2 + 9 + 1 = 12 。
*/
public int rob(int[] nums) {
if (nums == null || nums.length == 0) {
return -1;
}
// dp[i]:表示从0到i号房间能偷盗的最大值
int[] dp = new int[nums.length];
dp[0] = nums[0];
if (nums.length > 1) {
dp[1] = Math.max(nums[0], nums[1]);
}
for (int i = 2; i < nums.length; i++) {
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[nums.length - 1];
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {2, 7, 9, 3, 1};
System.out.println(solution.rob(nums));
}
}
LC337_打家劫舍III
public class Solution {
/**
* 打家劫舍III
* 补充:连续相连的两个节点被盗,房屋报警
* 输入: root = [3,2,3,null,3,null,1]
* 输出: 7
* 解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
*/
public int rob(TreeNode root) {
if (root == null) {
return 0;
}
// dfs返回一个2个数的一维数组
// res[0]=选择当前节点盗窃获取的最大值
// res[1]=不选择当前节点盗窃获取的最大值
int[] rootResult = dfs(root);
return Math.max(rootResult[0], rootResult[1]);
}
private int[] dfs(TreeNode node) {
if (node == null) {
return new int[]{0, 0};
}
int[] leftResult = dfs(node.left);
int[] rightResult = dfs(node.right);
// 选择当前节点盗窃:它的子节点不能盗窃
int selectedNode = node.val + leftResult[1] + rightResult[1];
// 不选择当前节点盗窃:它的左孩子盗窃最大值+它的右孩子盗窃最大值
int notSelectedNode = Math.max(leftResult[0], leftResult[1]) + Math.max(rightResult[0], rightResult[1]);
return new int[]{selectedNode, notSelectedNode};
}
}
买卖股票问题
LC121_买卖股票最佳时机I
public class Solution {
/**
* LC122_买卖股票最佳时机I
* 输入:[7,1,5,3,6,4]
* 输出:5
* 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
* 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
*/
public int maxProfit(int[] prices) {
// 找出买卖一只股票获得最大利润
int min = prices[0];
int profit = 0;
for (int i = 1; i < prices.length; i++) {
min = Math.min(min, prices[i]);
profit = Math.max(profit, prices[i] - min);
}
return profit;
}
}
LC122_买卖股票最佳时机II
- 贪心
public class Solution {
/**
* LC122_买卖股票最佳时机II
* 输入: prices = [7,1,5,3,6,4]
* 输出: 7
* 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
* 在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
*/
public int maxProfit(int[] prices) {
if (prices.length < 2) {
return 0;
}
int profit = 0;
// 贪心:只要后一天价格>前一天价格,就前一天买入,后一天卖出
for (int i = 0; i < prices.length - 1; i++) {
if (prices[i] < prices[i + 1]) {
profit += prices[i + 1] - prices[i];
}
}
return profit;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {7, 1, 5, 3, 6, 4};
System.out.println(solution.maxProfit(nums));
}
}
- 动态规划
public class Solution1 {
/**
* LC122_买卖股票最佳时机II
* 输入: prices = [7,1,5,3,6,4]
* 输出: 7
* 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
* 在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
*/
public int maxProfit(int[] prices) {
if (prices.length < 2) {
return 0;
}
// 动态规划:dp[i][j]表示第i天买还是不买股票
int[][] dp = new int[prices.length][2];
dp[0][0] = 0;
dp[0][1] = -prices[0];
for (int i = 1; i < prices.length; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
}
return dp[prices.length - 1][0];
}
public static void main(String[] args) {
Solution1 solution = new Solution1();
int[] nums = {7, 1, 5, 3, 6, 4};
System.out.println(solution.maxProfit(nums));
}
}
LC188_买卖股票最佳时机IV
public class Solution {
/**
* 买卖股票的最佳时机IV
* 注意:'最多'可以完成k笔交易
* 输入:k = 2, prices = [2,4,1]
* 输出:2
* 解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
*/
public int maxProfit(int k, int[] prices) {
if (prices == null || prices.length == 0) {
return 0;
}
int n = prices.length;
// n天最多进行n/2笔交易
// k取交易数最小值即可
k = Math.min(k, n / 2);
// buy[i][j]:持有股票下,到第i天交易j次的最大利润
int[][] buy = new int[n][k + 1];
// sell[i][j]:不持有股票下,到第i天交易j次的最大利润
int[][] sell = new int[n][k + 1];
// 初始化
buy[0][0] = -prices[0];
sell[0][0] = 0;
for (int i = 1; i <= k; i++) {
// /2防止Integer.Min减数时越界
buy[0][i] = sell[0][i] = Integer.MIN_VALUE / 2;
}
// 动态转移
for (int i = 1; i < n; i++) {
// 更新第i天,进行0次交易的最大利润
buy[i][0] = Math.max(buy[i - 1][0], sell[i - 1][0] - prices[i]);
for (int j = 1; j <= k; j++) {
buy[i][j] = Math.max(buy[i - 1][j], sell[i - 1][j] - prices[i]);
// buy[i - 1][j - 1]
sell[i][j] = Math.max(sell[i - 1][j], buy[i - 1][j - 1] + prices[i]);
}
}
// 最大利润一定是sell中的最大值
return Arrays.stream(sell[n - 1]).max().getAsInt();
}
public static void main(String[] args) {
Solution solution = new Solution();
int k = 2;
int[] nums = {3, 2, 6, 5, 0, 3};
System.out.println(solution.maxProfit(k, nums));
}
}
LC309_最佳买卖股票时机含冷冻期
public class Solution {
/**
* 最佳买卖股票时机含冷冻期
* 输入: prices = [1,2,3,0,2]
* 输出: 3
* 解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
*/
public int maxProfit(int[] prices) {
if (prices == null || prices.length == 0) {
return 0;
}
int n = prices.length;
// dp[i][j]:第i天最大利润
// 当来到新的一天,会有以下3种状态,所以是二维数组
// j=0说明第i天持有股票
// j=1说明第i天不持有股票,处于冷冻期
// j=2说明第i天不持有股票,不处于冷冻期
int[][] dp = new int[n][3];
// 初始化
// 第0天持有股票:属于买股票
dp[0][0] = -prices[0];
// 第0天不持有股票,处于冷冻期,不存在,假设为0
dp[0][1] = 0;
// 第0天不持有股票,不处于冷冻期,不存在,假设为0
dp[0][2] = 0;
for (int i = 1; i < n; i++) {
// 第i天持有股票:前一天不处于冷冻期+今天买股票;前一天持有股票不操作
dp[i][0] = Math.max(dp[i - 1][2] - prices[i], dp[i - 1][0]);
// 第i天不持有股票,处于冷冻期:只能是前一天持有股票,今天卖出获得收益
dp[i][1] = dp[i - 1][0] + prices[i];
// 第i天不持有股票,不处于冷冻期:今天没有任何操作,取前一天不持有股票两种状态最大值
dp[i][2] = Math.max(dp[i - 1][1], dp[i - 1][2]);
}
return Math.max(dp[n - 1][1], dp[n - 1][2]);
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {2, 1};
System.out.println(solution.maxProfit(nums));
}
}
LC156_LRU缓存
题目:实现一个LRU
示例:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
解答:

public class LRUCache {
private int size;
private int capacity;
private Map<Integer, DLinkedNode> cache;
private DLinkedNode head;
private DLinkedNode tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
this.cache = new HashMap<>(capacity);
// 题目规定key、value>=0,这里可以传-1表示头尾结点
this.head = new DLinkedNode(-1, -1);
this.tail = new DLinkedNode(-1, -1);
this.head.next = tail;
this.tail.pre = head;
}
public int get(int key) {
if (size == 0) {
return -1;
}
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
deleteNode(node);
removeToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node != null) {
node.value = value;
deleteNode(node);
removeToHead(node);
return;
}
if (size == capacity) {
// 细节:容量满了,先清理缓存,再删除末尾结点
cache.remove(tail.pre.key);
deleteNode(tail.pre);
size--;
}
node = new DLinkedNode(key, value);
cache.put(key, node);
// 更新缓存
removeToHead(node);
size++;
}
private void deleteNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
private void removeToHead(DLinkedNode node) {
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
}
/**
* 定义双向链表结点数据结构
*/
private class DLinkedNode {
int key;
int value;
DLinkedNode pre;
DLinkedNode next;
public DLinkedNode(int key, int value) {
this.key = key;
this.value = value;
}
public DLinkedNode() {
}
}
}
LC460_LFU缓存
题目:实现一个LFU缓存
- LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象
- int get(int key) - 如果键 key 存在于缓存中,则获取键的值,否则返回 -1 。
- void put(int key, int value) - 如果键 key 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 capacity 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。
示例:
输入:
["LFUCache", "put", "put", "get", "put", "get", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [3], [4, 4], [1], [3], [4]]
输出:
[null, null, null, 1, null, -1, 3, null, -1, 3, 4]
解释:
// cnt(x) = 键 x 的使用计数
// cache=[] 将显示最后一次使用的顺序(最左边的元素是最近的)
LFUCache lfu = new LFUCache(2);
lfu.put(1, 1); // cache=[1,_], cnt(1)=1
lfu.put(2, 2); // cache=[2,1], cnt(2)=1, cnt(1)=1
lfu.get(1); // 返回 1
// cache=[1,2], cnt(2)=1, cnt(1)=2
lfu.put(3, 3); // 去除键 2 ,因为 cnt(2)=1 ,使用计数最小
// cache=[3,1], cnt(3)=1, cnt(1)=2
lfu.get(2); // 返回 -1(未找到)
lfu.get(3); // 返回 3
// cache=[3,1], cnt(3)=2, cnt(1)=2
lfu.put(4, 4); // 去除键 1 ,1 和 3 的 cnt 相同,但 1 最久未使用
// cache=[4,3], cnt(4)=1, cnt(3)=2
lfu.get(1); // 返回 -1(未找到)
lfu.get(3); // 返回 3
// cache=[3,4], cnt(4)=1, cnt(3)=3
lfu.get(4); // 返回 4
// cache=[3,4], cnt(4)=2, cnt(3)=3
解答:

class LFUCache {
private int size;
private int capacity;
private Map<Integer, Node> cache;
/**
* 频次对应的双向链表
*/
private Map<Integer, DoubleLinkedList> freqMap;
/**
* 当前最小值
*/
private int min;
public LFUCache(int capacity) {
this.cache = new HashMap<>(capacity);
this.freqMap = new HashMap<>();
this.capacity = capacity;
}
public int get(int key) {
Node node = cache.get(key);
if (node == null) {
return -1;
}
// node增加频次
addFreq(node);
return node.value;
}
public void put(int key, int value) {
if (capacity == 0) {
return;
}
Node node = cache.get(key);
// node存在就更新频次
if (node != null) {
node.value = value;
addFreq(node);
} else {
// node不存在
// 链表满啦,移除最不经常使用的=移除min对应的链表
if (size == capacity) {
DoubleLinkedList minList = freqMap.get(min);
cache.remove(minList.tail.pre.key);
minList.removeNode(minList.tail.pre);
size--;
}
node = new Node(key, value);
cache.put(key, node);
// 获取频次为1的链表
DoubleLinkedList linkedList = freqMap.get(1);
if (linkedList == null) {
linkedList = new DoubleLinkedList();
freqMap.put(1, linkedList);
}
linkedList.addNode(node);
size++;
// node不存在,更新最不长使用频次=1
min = 1;
}
}
private void addFreq(Node node) {
// 从原freq对应的链表里移除, 并更新min
int freq = node.freq;
DoubleLinkedList linkedList = freqMap.get(freq);
linkedList.removeNode(node);
// freq = min 且 原freq对应的链表为空
if (freq == min && linkedList.head.next == linkedList.tail) {
min = freq + 1;
}
// 更新freq
node.freq++;
linkedList = freqMap.get(freq + 1);
if (linkedList == null) {
linkedList = new DoubleLinkedList();
freqMap.put(freq + 1, linkedList);
}
linkedList.addNode(node);
}
class DoubleLinkedList {
Node head;
Node tail;
public DoubleLinkedList() {
head = new Node();
tail = new Node();
head.next = tail;
tail.pre = head;
}
void removeNode(Node node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
void addNode(Node node) {
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
}
}
/**
* 结点
*/
class Node {
int key;
int value;
int freq = 1;
Node pre;
Node next;
public Node() {
}
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
}














 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









