







lg(M/N)=lg(M)-lg(N)
有序表:
- 按键检索
- 按键插入
插入排序:
每次迭代将第1个未排序的元素插入到有序部分的合适部分。
即将元素依次与有序部分的元素依次进行比较直到找到合适的位置
template<typename ListEntry>
void InsertSort(OrderList<ListEntry> &l1)
{
int size = l1.size();
if (size == 0) {
cout << "Error:" << __FILE__ << ": in function "
<< __func__ << " at line " << __LINE__ << endl
<< "OrderList is empty" << endl;
return;
}
int be_sort = 1;
ListEntry data, item;
for (int i = 1;i < size;++i) {
l1.retrieve(i, item);
int t = be_sort - 1;
l1.retrieve(t, data);
//需要移动
if (data > item) {
l1.remove(i);
//从后向前比较
int j;
for (j = t;j >0;j--) {
l1.retrieve(j - 1, data);
//继续向前寻找
if (data > item) continue;
//已经找到合适的位置
else break;
}
//防止元素无法移动到第1个前面
l1.insert(j, item);
}
++be_sort;
}
}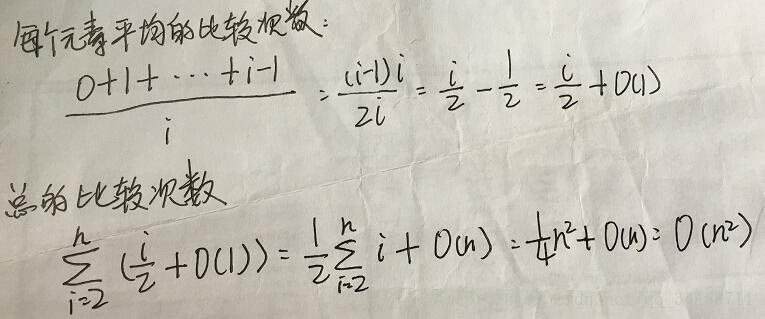
最佳情况:
表已经是有序的,所以每次循环只进行1次比较。所以n个元素一共进行n-1次比较。可得时间复杂度为O(n)
最差情况:
每个元素都要进行n-1次比较
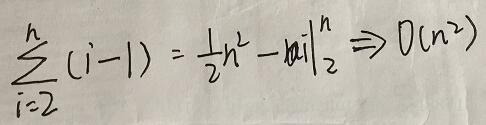
选择排序:
首先找出关键词最大的元素并与相应位置上的元素交换位置,在每次遍历未排序的部分,找出第n大的元素。
每次迭代都有元素放在最终的位置上。
在不同迭代的寻找最大元素的过程中可能会造成重复的判断。
template<typename Entry = int, int size>
void SelectSort(array<Entry, size> &a1)
{
int size = a1.size(), st = 0;
if (size <2) {
cout << "Error:" << __FILE__ << ": in function "
<< __func__ << " at line " << __LINE__ << endl
<< "array doesn't need to sort: size=" << size << endl;
return;
}
int end, max;
for (end = size;end >1;--end) {
max = a1[0];
//寻找未排序的最大值
for (int i = 1;i < end;++i) {
if (a1[i] > max) {
max = a1[i];
st = i;
}
}
//依次与最后的元素交换
swap(a1[end - 1], a1[st]);
}
}
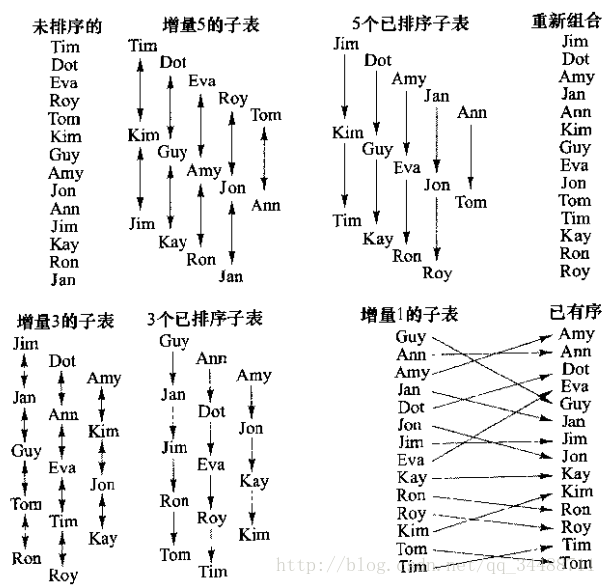
希尔排序:
对插入排序进行优化,提高增量。通过不同的迭代增量(尽量选择不是倍数的值,避免上一趟比较过的键在下一趟被重复比较)对表进行优化,最后增量为1进行检查。随机性较大,难以计算复杂度。
template<typename Entry = int, int size>
void ShellSort(array<Entry, size> &a)
{
int size = a.size();
if (size <2) {
cout << "Error:" << __FILE__ << ": in function "<< __func__ << " at line " << __LINE__ << endl<< "array doesn't need to sort: size=" << size << endl;
return;
}
int d = size;//子表中每2个元素的距离为d-1
do {
//使增量不互为倍数且最后为1
d = d / 3 + 1;
for (int i = 0;i<d;++i)
//对每个子表的元素进行比较
for (int j = i;j + d< size;j += d)
if (a[j] > a[j + d])
swap(a[j], a[j + d]);
} while (d > 1);//防止d走不出循环
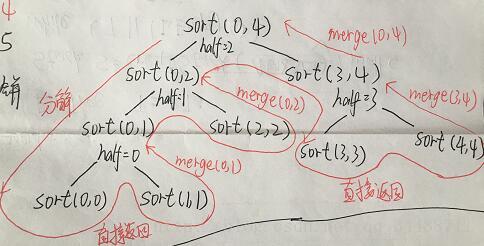
}归并排序:先逐次平分成不同的序列再排好序
随着递归平分,然后合并(开始比对)
template<typename Entry = int, int size>
void MergeSort(array<Entry, size> &a)
{
int size = a.size();
assist_mergesort(a, 0, size - 1);
}
template<typename Entry = int, int size>
void assist_mergesort(array<Entry, size> &a, int beg, int end)
{
//只有1个时直接返回
if (beg < end) {
//将序列平分成2半
int half = (beg + end) / 2;
assist_mergesort(a, beg, half);
assist_mergesort(a, half + 1, end);
//递归返回后按序合并
merge(a, beg, half, end);
}
}
//复制2个子表的元素至2个新数组,比较后将元素重新插入原表
template<typename Entry = int, int size>
void merge(array<Entry, size> &a, int beg, int half, int end)
{
//注意复制区间的起始位置
auto iter1 = a.begin();
iter1 += beg;
//创建2个新子表
int d1 = half - beg + 1, d2 = end - half;
auto iter2 = iter1 + d1;
auto iter3 = iter2 + d2;
//复制区间左闭右开
vector<int>a1(iter1, iter2);
vector<int>a2(iter2, iter3);
int i = beg,i1 = 0, i2 = 0;
//从2个子表中按大小顺序复制元素形成新的序列
while (i1 < d1&&i2 < d2)
if (a1[i1] > a2[i2])
a[i++] = a2[i2++];
else
a[i++] = a1[i1++];
//如果有子表存在剩余,直接插入
if (i1 < d1)
for (;i1<d1;++i1)
a[i++] = a1[i1];
if (i2 < d2)
for (;i2<d2;++i2)
a[i++] = a2[i2];
}链式
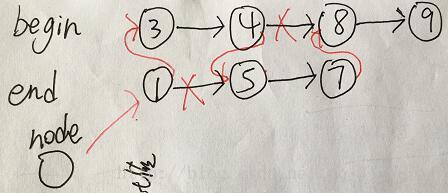
void MergeSort(OrderList* &l1)
{
if(l1!=nullptr&&l1->next!=nullptr){
auto half=divide_from(l1);
MergeSort(l1);
MergeSort(half);
l=merge(l1,half);
}
}
void MergeSort(OrderList* &begin,OrderList* &end)
{
OrderList node;
OrderList* pre=node;
while(begin!=nullptr&&end!=nullptr){
if(begin->entry<second->entry){
pre->next=begin;
pre=begin;
begin=begin->next;
}
else{
pre->next=end;
pre=end;
end=end->next;
}
if(begin==nullptr) pre->next=end;
else pre->next=begin;
return node.next;
}
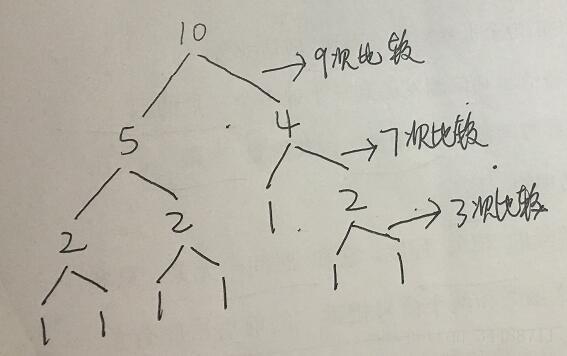
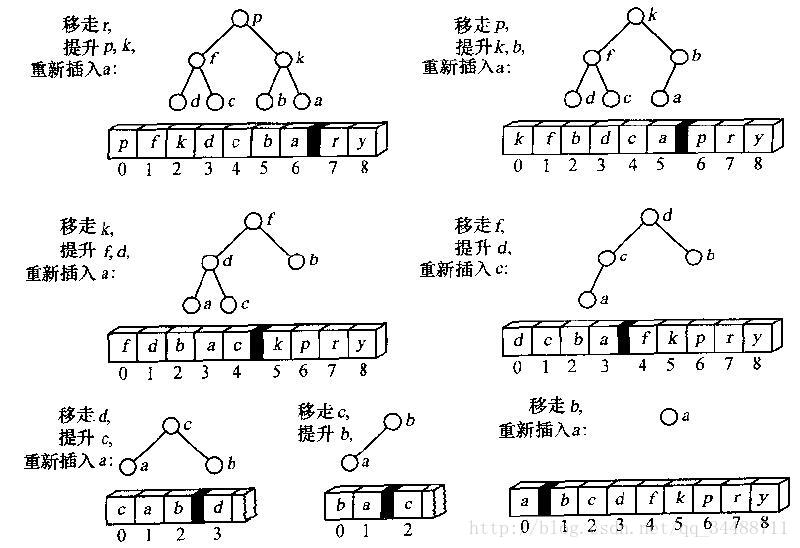
}由比较树可以看出,归并算法是从树叶向根节点进行排序。每一层的比较总次数最多为n-1,由于n可能为奇数,所以最多有lg(n)层。
例如2个子表分别为123和456,则只需要比较3次;135和246需要比较5次。
所以比较次数≤nlg(n)(每层的比较次数*层数)
快速排序:
- 每次分割根据某个键值分成小于和大于的2部分
- 随机选择1个元素作为比较对象并将其放在表的最后,比较完后放回中间。所以每次迭代完成后被用作比较的键会被放到正确的位置上。
- 小于该元素的放在前面;大于放在后面
元素小于时下标i和j向后移动来标记每个部分的最后1个元素
可以看做是升级版的选择排序,每次都有1个元素移动到正确的位置;但是在选择排序中其他剩余的元素依然是无序的,快速排序却初步将剩余的元素划分成大于和小于2个元素。
- 快速排序的缺点在于无法控制子表的长度
- 每次迭代比较n-1次。所以比较次数C(n)=n-1+C(r)+C(n-r-1)
- 最坏情况:每次选择的键为最值,会导致1个子表为0,所以C(n)max=n-1+n-2+ ……+1=n^2/2+n/2=O(n^2)
- 平均性能:
设每次partition函数返回的左边分布的长度为p,
C(n,p)为第一次返回p后总的比较次数
有C(n,p)=n-1+C(p-1)+C(n-p)
- 最佳性能:
为了让总的比较次数越小,则需要层数越小。递归的结束条件为范围中只有1个元素,所以每条路径的叶节点都是1。所以为了减少层数,最理想的情况为每个子问题的划分为n/2,使每条路径最快的减小到1。
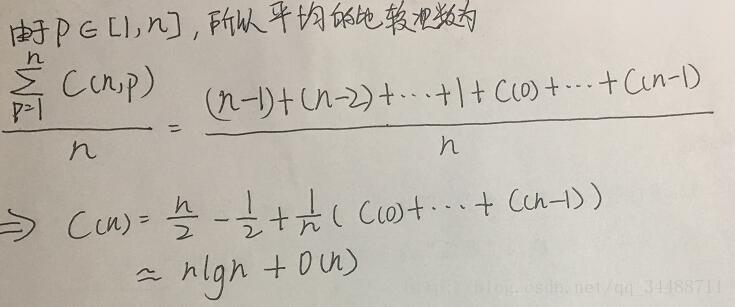
template<typename Entry = int, int size>
void QuickSort(array<Entry, size> &a)
{
int size = a.size();
assist_quicksort(a, 0, size - 1);
}
template<typename Entry = int, int size>
void assist_quicksort(array<Entry, size> &a, int beg, int end)
{
if (beg < end) {
int half = parttition(a, beg, end);
//中位数无需排序
assist_quicksort(a, beg, half - 1);
assist_quicksort(a, half + 1, end);
}
}
template<typename Entry = int, int size>
int parttition(array<Entry, size> &a, int beg, int end)
{
int t = a[end];//将最后1个元素作为划分的依据
int end1 = beg - 1;//同时作为第1段的终止位置和第2段的起始位置
int i = beg;
for (;i < end;++i)
if (a[i]< t) {
++end1;
swap(a[i], a[end1]);
}
//将作为比较的数放回中间
swap(a[end1 + 1], a[end]);
return end1 + 1;
}
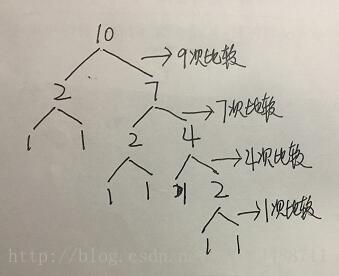
最大堆:
- 父节点大于子节点
- 同一父节点之间没有强制的大小顺序关系
- 不需要使用树的结构,只是为了表达更为直观
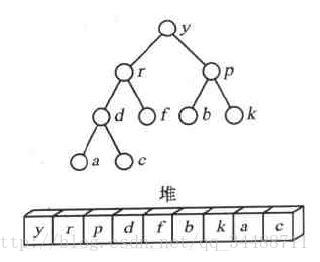
应用:
堆排序:
- 提出末尾的元素,将头结点放到末尾
- 依次找出子节点中的最大值向上移动
- 将末尾元素放在堆的最后
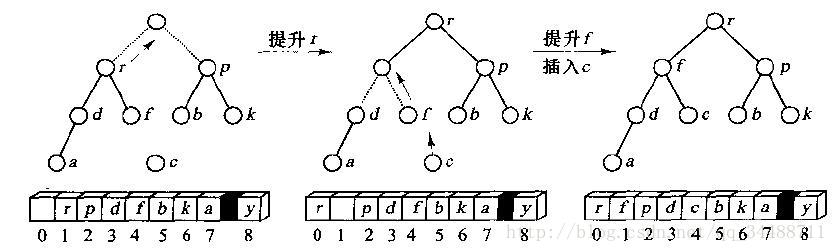
堆的建立:
- 先将表中的元素放到堆中。由后向前遍历表的前半部分(最后一层的节点个数乘2减1等于总个数父),用父节点与其子节点相比对,将大的放在前面。
- 将堆的顶点取出并放到表的末尾,通过比较移动其子节点。
先比较空位的所有2个子节点找出最大值,如果被替换的节点大于等于该值,停止遍历。否则向下1层继续遍历。
template<typename T>
void build_heap(vector<T>& v)
{
int count=v.size();
for(int i=count/2-1;i>=0;--i)
heap_insert(v,i,count-1);
}
//heap_insert还需要继续用于堆排序中堆的维护,
//所以在参数中需要加入e标识未排序的末尾
template<typename T>
void heap_insert(vector<T>& v,int i,int e)
{
int j=2*i+1;//左子节点
while(j<=e)
{
//找出左右子节点的最大值
if( j<(v.size()-1) && v[j]<v[j+1] ) ++j;
//是否需要调整
if(v[i]<v[j])
{
swap(v[i],v[j]);
i=j;
j=2*j+1;
}
//由于调整后可能会导致子树违背最大堆的性质
//所以需要继续向下进行检查
else break;
}
}
template<typename T>
void heap_sort(vector<T>& v)
{
build_heap(v);
for(int unsort=v.size()-1;unsort>0;--unsort)
{
swap(v[0],v[unsort]);
heap_insert(v,0,unsort-1);
}
}性能分析:
在第一阶段:调用n次heap_insert,复杂度为O(n)
在第二阶段:进行交换后,v[0]的值都要被交换到未排序的最后面。
当树的节点总个数为n时
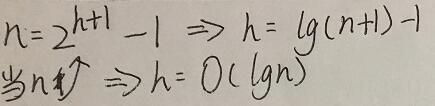
每个被遍历的元素的比较次数为:
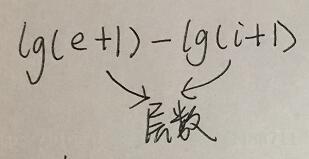
每次循环比较2次,所有元素的循环次数为:
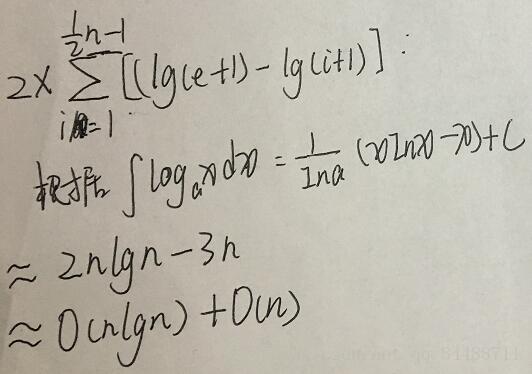
优先队列:(参考STL的priority_queue,包装了Heap)
- 插入:放到堆的最后面
- 取出:使用pop_back()后再进行调整
二叉比较树:
- 高度:最大次数
- 外部路径/叶节点:平均次数
- 外部路径长度E:
遍历从根到树中每个树叶所经历的分支数(不是节点数) - 内部路径长度I:
遍历从根到树中每个非树叶所经历的分支数(不是节点数) - E=I+2q(非树叶的顶点数目)
- 由于树每层的最大结点数是其上一层的2倍。所以第t层(t>=0)的最大节点数为2^t。所以当第t层有k个节点,t≥lg k。
排序算法的下限:
由于不同的排列顺序有n!种。——》树叶数至少为n!——》h至少为lg(n!)=Ω(nlgn)——》使用键比较的排序至少进行Ω(nlgn)次比较
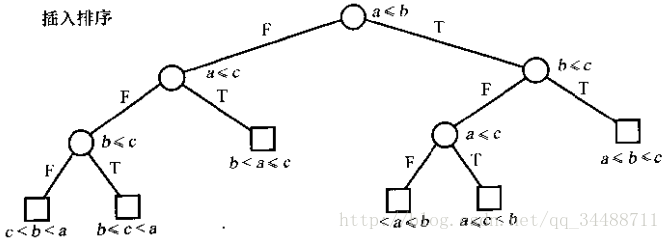
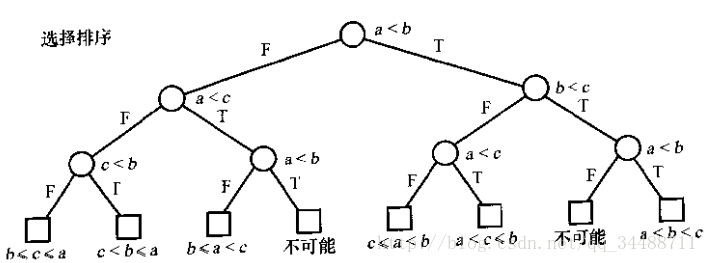
选择排序的特点:
- 移动高效
比较冗余
插入排序:
- 牺牲移动效率减少比较次数(树的分支树更少,虽然复杂度都是O(n))















 58万+
58万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









