









《一》准备样本文件
1.样本文件
可使用系统画图工具绘制样本文件,数量越多越好,作为训练的数据,如图

注:样本图像文件保存格式必须为.tif结尾或.tiff结尾的格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 错误,如图

以下是绘制的样本文件
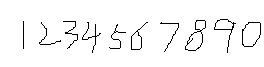
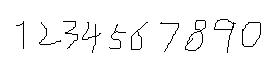
《二》Merge样本文件
1.在jTessBoxEditor目录,双击【train.bat】,打开 jTessBoxEditor,如图
点击菜单栏 【Tools 】->【Merge TIFF】,点击

2.在打开的文件选择器中找到将步骤《一》中制作的样本文件,按住Ctrl+鼠标点击选择所有样本图片,点击确定合成一个文件

3.去一个文件名,这个取名是有讲究的,必须是以下格式
格式:
[lang].[fontname].exp[num].tif
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
例:
number.font.exp0.tif
4.保存成功,弹窗,如图

《三》生成Box文件
1.进入num.font.exp0.tif 文件所在目录下,在目录导航栏键入cmd,点击Enter打开cmd命令窗口,输入如下格式命令
格式:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号
例:
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox2.看到目录下生成[lang].[fontname].exp[num].box文件,即代表操作成功
命令行中Page数量即代表合成文件中样本文件数量

《四》定义字符配置文件
在文件夹下新建一个文本文件,命名为font_properties,将.txt去掉,然后使用记事本打开文件,输入如下格式命令
格式:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称 italic 斜体 bold 黑体字 fixed 默认字体 serif 衬线字体 fraktur 德文黑字体
1代表是
0代表否
例:
font 0 0 0 0 0
《五》样本整合、矫正
1.将样本tif文件、num.font.exp0.tif文件、生成的num.font.exp0.box文件以及font_properties文件放在同一个目录下,如图

2.打开 jTessBoxEditor ->【BOX Editor】->【Open】,打开num.font.exp0.tif;矫正修改【Char】列上的字符,如图

注:修改为正确的字符后,点击Enter回车确定,否则不会生效
矫正后:

注:记得Page有好多页哦,每页都需要矫正
有可能生成的 box 文件后,会多一个盒子,它把7识别成了两个
处理策略:根据索引看到的数字修改char,如果不是完整字符就敲 空格,然后点击Enter回车确定,如图

3.几页都矫正处理完毕后点击【Merge】保存,替换原来的 box 文件
《六》批处理
1.在目录下,新建一个文本文件,将文本文件重命名为 run.bat,后缀.txt去掉,将以下代码段复制到文本中,根据自身文件名修改内容,保存
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause2.保存后,双击.bat执行,执行后会在文件夹生成很多文件,如图

3.将目录下的num.trainddata文件复制到Tesseract-OCR安装目录下的tessdata文件夹下,如图(如没有安装Tesseract-OCR,请参考上一篇Tesseract和jTessBoxEditor环境搭建)

《七》测试效果
在画图软件中随手再画一张图片,保存为.jpg/.png等正常图片格式,如图是我画的
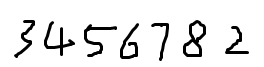
在待测试文件同目录下,打开cmd,输入tesseract命令
注:语言参数要设置成刚才拷贝的文件的名称前缀,如果没拷贝 xxx.trainddata,将无法识别
格式:
tesseract imagename resultfilename -l lang
imagename 待识别的文件名 resultfilename 识别结果的文件名 lang 语言
例:
tesseract num1.jpg num01 -l num识别结果如下

可以看到,由于训练样本较少,导致识别精度不高,只识别出来了3位数,故而,要实现识别的精确度,需要大量的样本
本章介绍到此结束。















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









