







希尔排序介绍
● 希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。 希尔排序是非稳定排序算法。
希尔排序的设计体现了计算机领域的“分治法”思想。在众多排序算法中,目前而言,希尔排序是唯一能在效率上与快速
排序一较高低的算法,目前只有这两种排序算法的时间复杂度突破O(n2)。值得一提的是,希尔排序与快速排序都基于“分治法”,从这里或许可以解释这两种排序算法在效率上的得天独厚。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位希尔排序的基本思想
算法描述
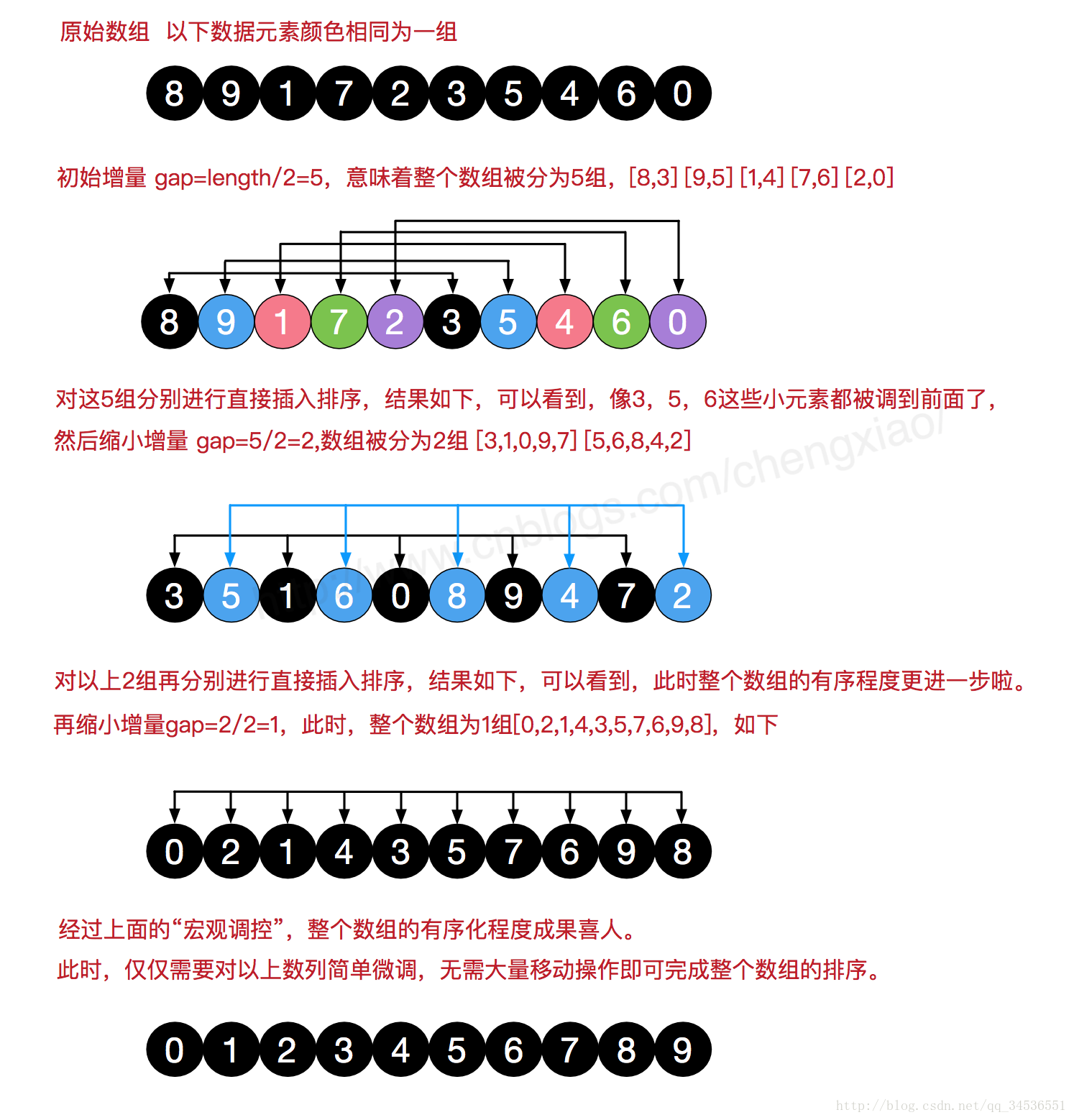
1、对于n个待排序的数列,取一个小于n的整数gap = n/2(gap被称为步长) 将待排序元素分成若干个组子序列,
2、所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组 的元素都是有序的。
3、然后减小gap = gap/2的值,并重复执行上述的分组和排序。
4、重复这样的操作,当gap=1时,整个数列就是有序的。
● 我们来看下希尔排序的基本步骤: 一开始我们选择增量gap=n/2,缩小增量继续以gap = gap/2的方式,这种增量选择我们可以用一个序列来表示,{n/2, (n/2)/2 , … ,1},称为增量序列。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
希尔排序算法介绍
①希尔排序又称缩小增量排序 ,它本质上是一个插入排序算法。为什么呢?
因为,对于插入排序而言,插入排序是将当前待排序的元素与前面所有的元素比较,而希尔排序是将当前元素
与前面增量位置上的元素进行比较,然后,再将该元素插入到合适位置。当一趟希尔排序完成后,处于增量位置上的元素是有序的。
②希尔排序算法的效率依赖于增量的选取
假设增量序列为 h(1),h(2)...h(k),其中h(1)必须为gap=n/2,且 h(1) < h(2) <...h(k) 。
第一趟排序时在增量为 gap=n/2 的各个元素上进行比较
第二趟排序在增量为 gap = gap/2 的各个元素上进行比较
最后一趟在增量 gap=1 上进行比较。由此可以看出,每进行一趟排序,增量是一个不断减少的过程,因此称之为缩小增量。
当增量减少到 gap=1 时,这里完全就是插入排序了,而在此时,整个元素经过前面的几趟排序后,已经变
得基本有序了,而我们知道,对于插入排序而言,当待排序的数组基本有序时,插入排序的效率是非常高
的。因此,希尔排序就是利用“增量”技巧将插入排序的平均时间复杂度O(N^2)降低为亚二次方。
● 这里有几种图的演示,供大家熟悉
(1) 我们来通过演示图,更深入的理解一下这个过程:
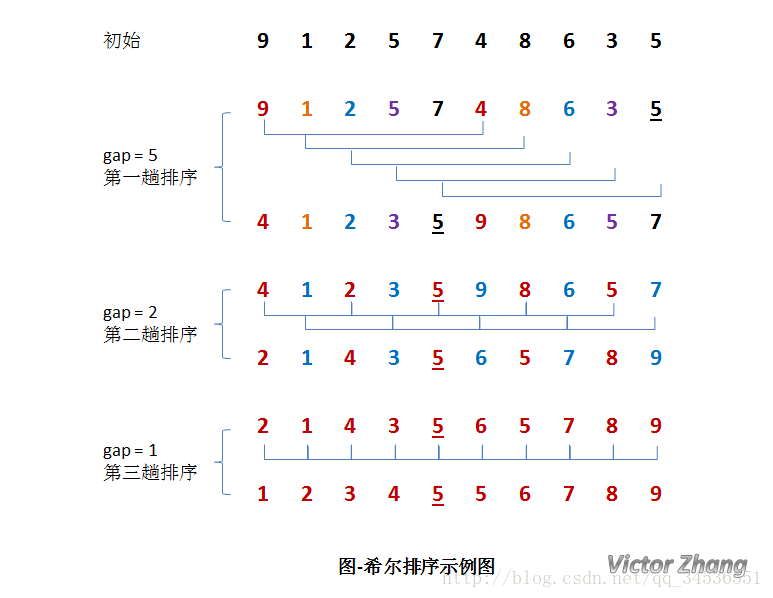
在上面这幅图中:
初始时,有一个大小为 10 的无序序列。
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
按照直接插入排序的方法对每个组进行排序。
在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。
按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
需要注意一下的是,图中有两个相等数值的元素 5 和 5 。我们可以清楚的看到,在排序过程中,两个元素位置交换了。
所以,希尔排序是不稳定的算法。
(3)下面以数列 {80, 30, 60, 40, 20, 10, 50, 70} 为例,演示它的希尔排序过程。
第1趟:(gap=4)
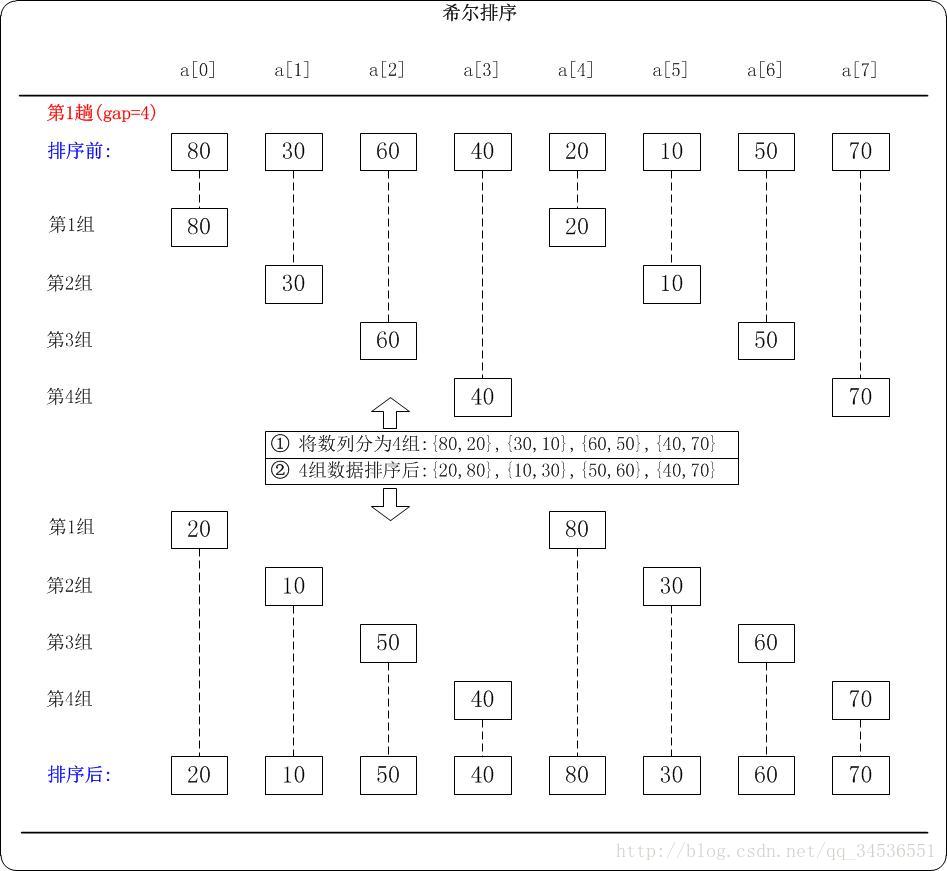
当gap=4时,意味着将数列分为4个组: {80,20}, {30,10}, {60,50}, {40,70}。 对应数列: {80, 30, 60, 40, 20,10, 50, 70}
对这4个组分别进行排序,排序结果: {20,80}, {10,30}, {50,60}, {40,70}。 对应数列: {20, 10, 50, 40, 80, 30, 60, 70}
第2趟:(gap=2)
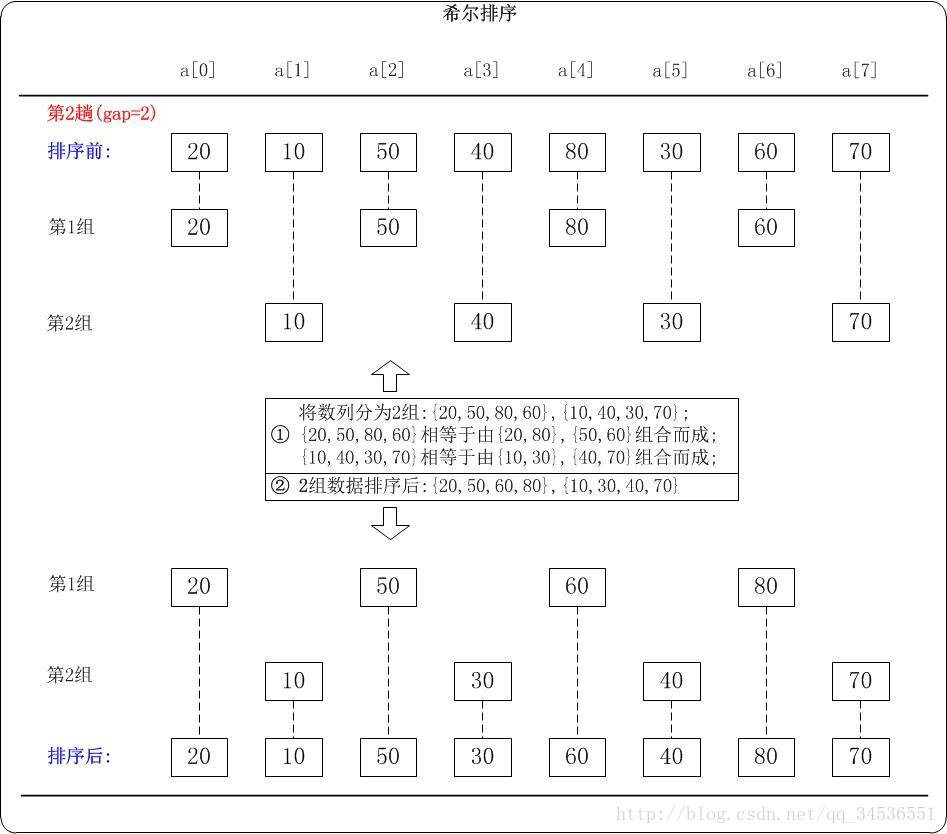
当gap=2时,意味着将数列分为2个组:{20,50,80,60}, {10,40,30,70}。 对应数列: {20, 10, 50, 40, 80, 30, 60, 70}
注意:{20,50,80,60} 实际上有两个有序的数列 {20,80} 和 {50,60} 组成。
{10,40,30,70} 实际上有两个有序的数列 {10,30} 和 {40,70} 组成。
对这2个组分别进行排序,排序结果:{20,50,60,80}, {10,30,40,70}。 对应数列: {20, 10, 50, 30, 60, 40, 80, 70}
第3趟:(gap=1)
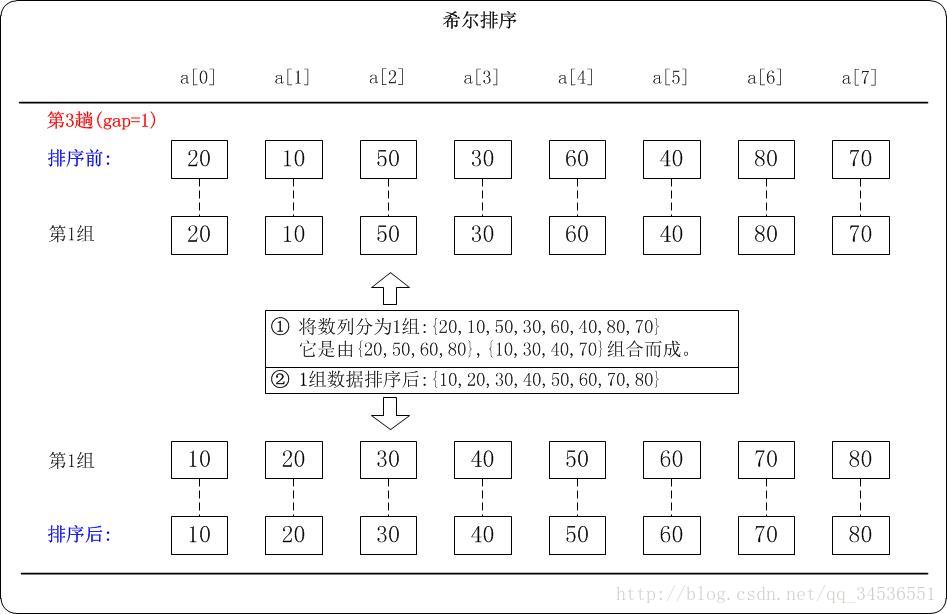
当gap=1时, 意味着将数列分为1个组: { 20, 10, 50, 30, 60, 40, 80, 70 }
注意:{20,10,50,30,60,40,80,70}实际上有两个有序的数列{20,50,60,80}和 {10,30,40,70}组成。
对这1个组分别进行排序,排序结果:{ 10, 20, 30, 40, 50, 60, 70, 80 }
算法分析

不过在某些序列中复杂度可以为O(n1.3);
时间复杂度
希尔排序的时间复杂度与增量(即,步长gap)的选取有关。例如,当增量为1时,希尔排序退化成了直接插入排序,此时的时间复杂度为O(N²), 而Hibbard增量的希尔排序的时间复杂度为O(N3/2)。
● 步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。
算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为N/2并且对步长取半直到步长达到1。虽然这样取可以比O(N2)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序
后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就
不会以如此短的时间完成排序了。

已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…),该序列的项来自
这两个算式。
这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
算法稳定性
希尔排序是不稳定的算法,它满足稳定算法的定义。对于相同的两个数,可能由于分在不同的组中而导致它们的顺序发生变化。
算法稳定性 – 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
空间复杂度:
希尔排序的空间复杂度显然为O(1),仅仅需要一个交换变量。相比快速排序递归调用产生的巨大栈消耗,希尔排序O(1)的空间消耗显得十分让人惊喜。
直接插入排序和希尔排序的比较
直接插入排序是稳定的;而希尔排序是不稳定的。
直接插入排序更适合于原始记录基本有序的集合。
希尔排序的比较次数和移动次数都要比直接插入排序少,当N越大时,效果越明显。
在希尔排序中,增量序列gap的取法必须满足:最后一个步长必须是 1 。
直接插入排序也适用于链式存储结构;希尔排序不适用于链式结构。















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









