






yolo很多文章都是讲的似懂非懂,要么细节确实,要么概念有误。
要想把yolo全面搞清楚之前建议先看以下直观理解。
物体的边缘坐标是否可以被训练?
在vgg模型中我们可以发现,对不同种类的图片进行标记,然后训练,便有了图像检测器。可以识别出图片里是什么。例如猫,狗等。
如果我们的训练不局限于物体是什么类别,而是再加上物体边框的坐标是否可行?如图所示:
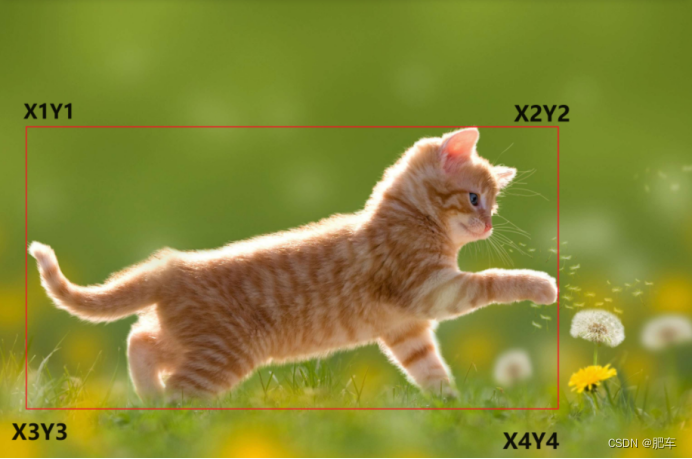
让物体四个角度坐标逼近真实值进行训练理论上完全没问题。但是过程可能极其困难和复杂,因为四个点连起来成的线怎么完美的包住物体,这个训练量是极其恐怖的。因为四个点比起他是猫着一个参数就多了8个标签(X1Y1...X4Y4)训练量会大增。另外四个点也不总是形成矩形如图所示:
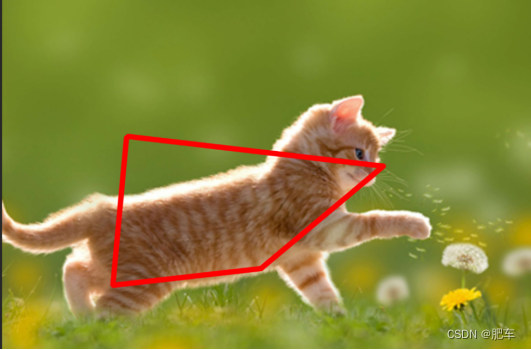


保证边框是矩形的方法
为了解决这个问题我们不直接训练四个角的坐标,而是训练中点和和的宽度和高度(如果不是矩形而是物体的真实边缘也是可以的,但这里只讨论yolo)。如此就可以保证时边框是一个矩行了。这既保证了形状,还减少了训练点,从9个(8个坐标参数,1个是分类)变为5个参数(中心点x和y2个,和宽高2个一个分类)

检测方法
即便使用了矩形坐标,但训练逼近还是太慢了。因为矩形的初始值可能会跑到图像的外面(左图所示),甚至很远的地方,这样逼近到正确的边框要很久。所以,需要把图像边框限定在图像范围之内,这样递归起来就会快不少。如图所示:
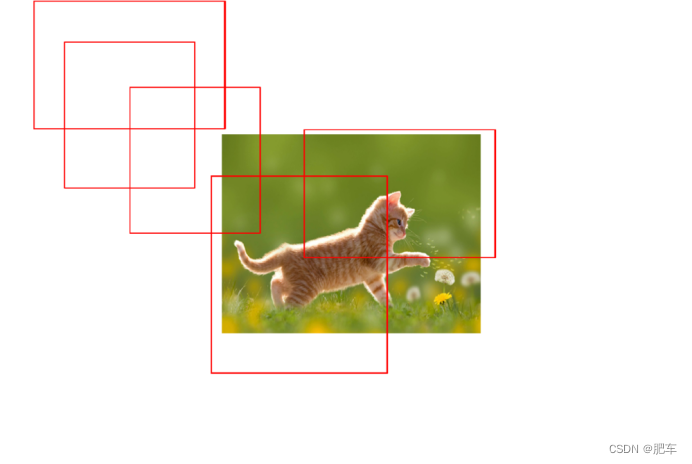

但依然还是不完美,假设目标猫咪在图像中很小,即便时把边框限定在图片中,进行打框也会非常的慢,因为逼近这个猫咪边框真实值要走的路还是太远了。

滑动窗口
设计滑动窗口去检测目标,如果滑动窗口中有目标则开始回归,没有则不用。其实就是限定了边框与检测窗口的位置关系。从而加快训练逼近的过程。
例如:左上角的检测滑动窗口(注意不是目标边框,很多人搞混了),是没有物体的,所以就不必去做回归。

然后滑动窗口到下一个位置。直到把所有图像的内容都遍历一遍。



之所以要把图片分为一个个小图的目的,就是为了把逼近限定正在小图之中。从而加快训练和检测的速度。
这样做需要再训练一个值,猫的中心点在不在检测窗口中,称为置信度。
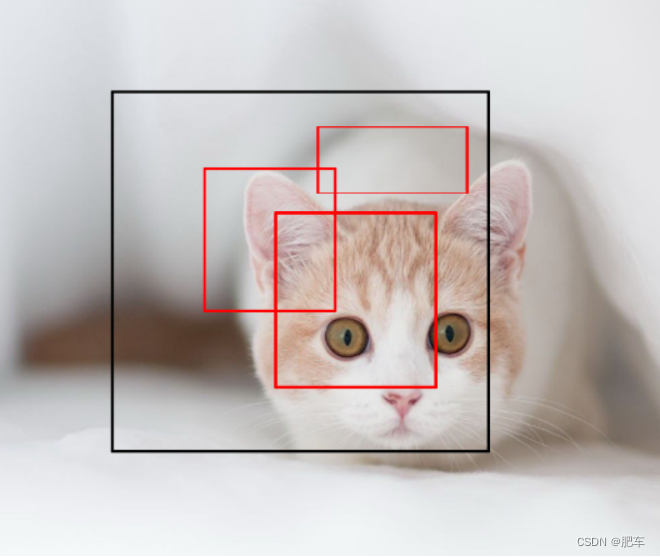
假设检测窗口框到如图所示的位置。这时候可以发现猫的大部分你内容在在检测窗口之中了,这时候就可以开始进行训练逼近了。

并且要限定中心点必须在检测窗口之中。这样有了支点再去逼近寻来你猫边框的就容易的多,西塔的初始值就不那么随机,离真相也越来越近。(黑色是检测框,红色我们要预测的边框)如图所示:
滑动检测窗口的优化
检测窗口不可能总是刚好框住并检测物体的(要是真能这样哪检测框就是物体边框本身了)
下两个图中猫咪的中点都在检测框中,选哪个好呢,两个其实都可以,但通常而言我们选个拿分哪个概率越高(置信度)就算选哪个。再次强调这里不是给物体打边框,而只是确认使用哪个滑动检测框来进行初始化逼近真实坐标。


先验框
下图中先从黑色的滑动检测框找到物体的中心,然后给出先蓝色验框,然后根据先验框的坐标去逼近真实的边框坐标,这样就比从从黑色的滑动检测框直接逼近真实框要快一些。

yolo的作者利用k均值算法在coco训练集中发现9个尺寸先验框更可能符合万物的形状。
所以有涉及有多个先验框的情况,如左图所示(蓝色是先验框),哪个先验框才是训练需要的呢?可以是使先验框与真实边框的iuo(交并比,用于确认两个框的重叠面积公式为:交集/并集)决定哪个先眼眶才是最佳的。
如图右所示,箭头处的先验框与真实框(红色)的iou更大,所以该先验框是我们需要使用的先验框。

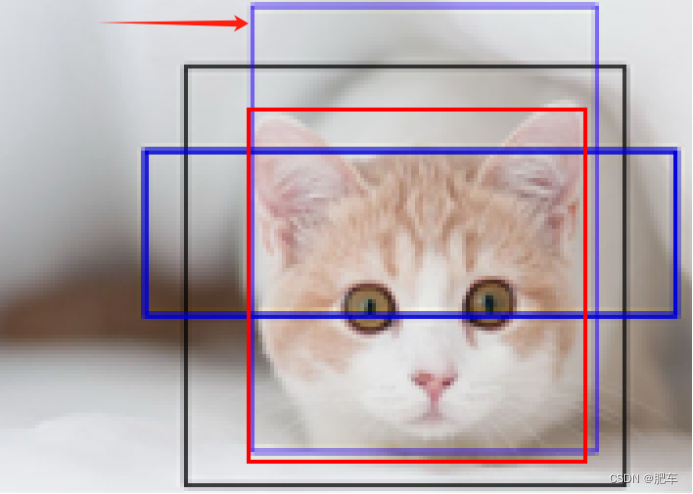
这时候再用该先验框去逼近真是框将极大极大的减少了递归的代数。大幅增加算法的训练的速度。
Yolo v2便是这样的思想。
有些人可能会意识到,按照检测窗口去检测目标,难道不是每次都要执行一次cnn吗速度岂不是更慢?
但是研究发现,cnn中滑动过滤器的过程刚好和我们检测图片滑动窗口的过程一致了,所以大部分计算共享!。如图所示:
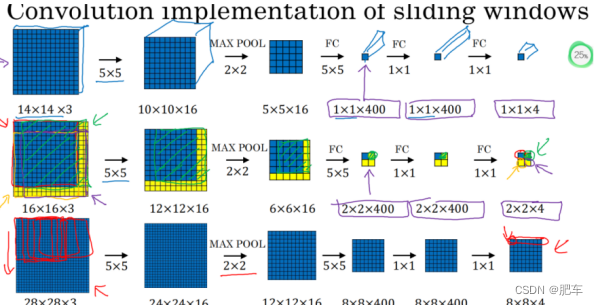
yoloV3思想:
假设物体很大,滑动检测窗口很小。那么要检测的内容那个太多,猫咪落在大部分网格上,这样就需要很多检测去识别。所以设计不同的网格大小跟适合检测大小不同的物体,可以更快更准确的检测到猫咪的中点。


检测更小的物体时则可以设计更密集的边框。

所以yolov3采用三个检测窗口的尺寸分别是13*13,26*26,52*52.
至此呢训练阶段就完成了。
需要注意的进行缩放后的图片打框需要偏移量进行还原。
预测阶段优化
预测阶段不外乎去掉标签,走一遍模型即可。

但会遇到如下问题,如果要检测图像中的人体,检测的结果可能是这样的。
因为预测过程中每个检测框的置信度不可能总是0,只要有概率就会打出边框,所以就造成这样很多边框的结果。

为了解决这个问题应该设一个置信度的阈值例如0.5
这样就会去掉置信度较低的边框如图所示。

有人可能会问为什么不直接保留置信度最高的边框呢?
如果只保留置信度最高的边框,左边人物的两个边框就会被去掉,因为他们都小于0.9,所以该办法不能对多目标打边框。
还有的人会说直接对照标签不就行了,但注意这里是预测阶段,没有任何标签。不然训练就无意义了。
正确的做法是。
首先找出最高置信度的边框,例如0.9的边框命名为A边框,然后查找A边框与他重合边框有哪些,这个过程直接计算IOU即可,凡是IOU大于某个阈值时,则说明该边框与A边框重叠过多,他们多半是同一个物体上的不同预测结果,则可以删除,例如图中设置iou为0.5,那么右边人体的边框把0.8与0.7置信度的边框就会去掉。而左侧任务的边框则不会被影响。后接着在寻找剩下的边框重复以上过程。最终找到最符合图像的边框
需要强调的是,此时的iou和训练的提到的iou完全不是一回事。
另外该IOU阈值不能太低,因为现实中确实存在着重叠的物体。
如图所示:

至此直观理解到此结束。
下一篇会会讲解算法模型。
转载请告知















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









