






之前讲了字典树的基本原理与代码实现,本文主要讲经典例题。
文章目录
LeetCode 208. 实现 Trie (前缀树)
解题思路:初始化、插入和查找都是基本的操作,StartWith操作没有见过。只需按查找的步骤来做StartWith, 不用判断最后一个字母是否独立成词,即可。
class Node {
public:
Node() {
flag = 0;
for (int i = 0; i < 26; i++) {
next[i] = nullptr;
}
}
int flag;
Node * next[26];
};
class Trie {
public:
Trie() {
root = new Node();
}
void insert(string word) {
Node *p = root;
for (auto x : word) {
int ind = x - 'a';
if (p->next[ind] == nullptr) p->next[ind] = new Node();
p = p->next[ind];
}
p->flag = true;
}
bool search(string word) {
Node *p = root;
for (auto x : word) {
int ind = x - 'a';
if (p->next[ind] == nullptr) return false;
p = p->next[ind];
}
return p->flag;
}
bool startsWith(string prefix) {
Node *p = root;
for (auto x : prefix) {
int ind = x - 'a';
if (p->next[ind] == nullptr) return false;
p = p->next[ind];
}
return true;
}
Node *root;
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/
提交结果:

总结:复习常规方法实现的字典树。
LeetCode 1268. 搜索推荐系统
题目分析:
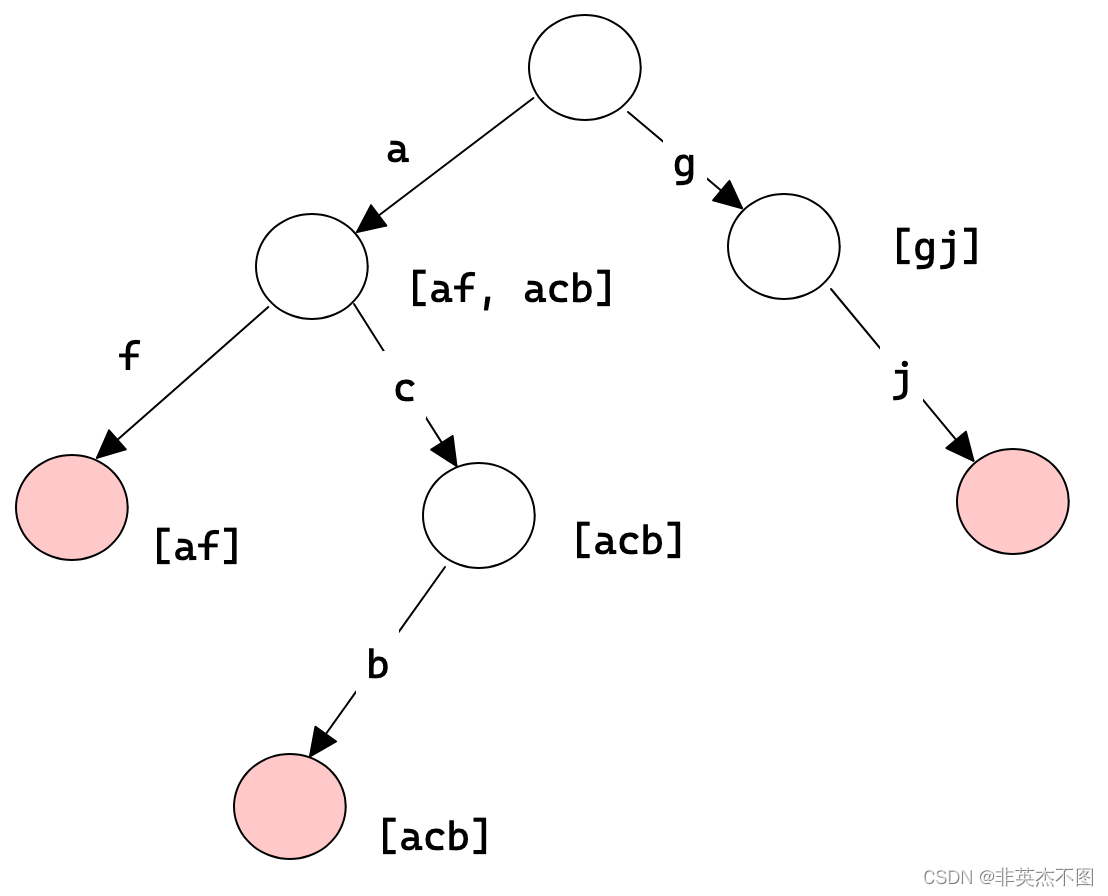
在常规字典树的实现中,每一个节点额外存一个字符串集合。
在插入单词的过程中,把当前单词插入到每一个节点的集合中去。当当前节点中的单词大于3个时,就删掉排名最大的那个单词。如下图:
如此将products中的单词都插入到字典树中后,再对searchWord 进行查找。
然后查找搜索的过程中,每次搜到一个节点,就把当前节点对应集合中的字符串都加到结果二维数组中。
class Node {
public:
Node() {
flag = 0;
for (int i = 0; i < 26; i++) {
next[i] = nullptr;
}
s = set<string> ();
}
~Node() {}
int flag;
Node * next[26];
set<string> s;
};
class Trie {
public:
Trie() {
root = new Node();
}
void clearTrie(Node *root) {
if (root == nullptr) return;
for (int i = 0; i < 26; i++) {
clearTrie(root->next[i]);
}
return;
}
~Trie() {
clearTrie(root);
}
void insert(string word) {
Node *p = root;
for (auto x : word) {
int ind = x - 'a';
if (p->next[ind] == nullptr) p->next[ind] = new Node();
p = p->next[ind];
p->s.insert(word);
if (p->s.size() > 3) {
auto iter = p->s.end();
iter--;
p->s.erase(iter);
}
}
p->flag = true;
}
vector<vector<string>> search(string word) {
Node *p = root;
vector<vector<string>> ret;
for (auto x : word) {
int ind = x - 'a';
if (p == nullptr) {
//上一个遍历到的节点为空
ret.push_back(vector<string>() );
continue;
};
p = p->next[ind];
vector<string> temp;
if (p != nullptr) {
//当前遍历到的节点不为空
for (auto x : p->s) {
temp.push_back(x);
}
}
ret.push_back(temp);
}
return ret;
}
Node *root;
};
class Solution {
public:
vector<vector<string>> suggestedProducts(vector<string>& products, string searchWord) {
Trie root;
for (auto x : products) root.insert(x);
return root.search(searchWord);
}
};
代码提交结果:

总结:在常规字典树实现的基础上进行了一些改动,从而实现题目要求的结果。字典树的实现是采用了最基础的版本,未做优化。
也可以看出,字典树很难进行统一的一个封装,因为一般是需要根据实际业务场景,进行统一的一个封装和优化改动。
剑指 Offer II 067. 最大的异或
题目分析:
-
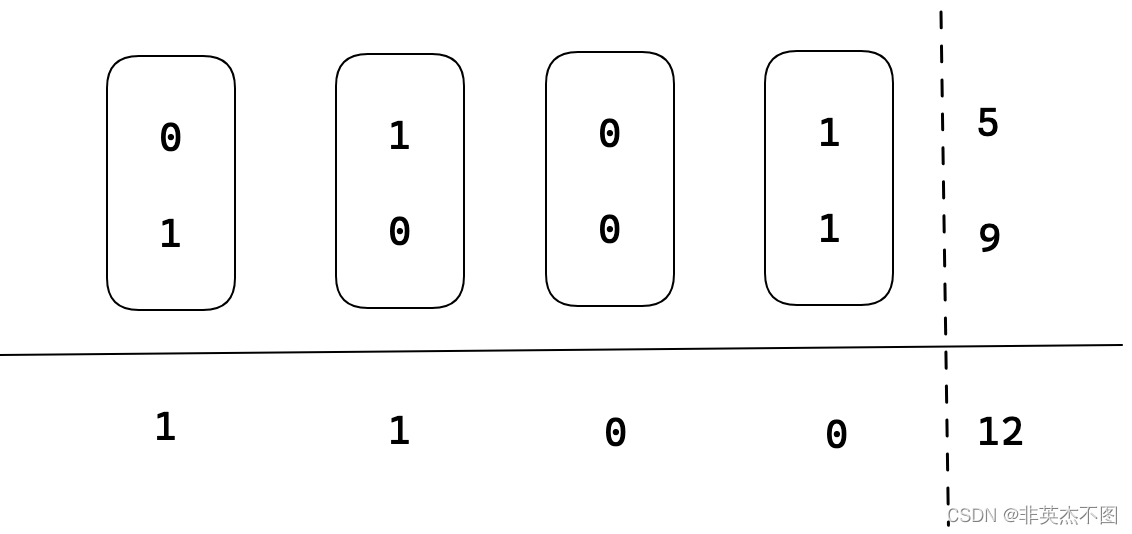
什么是异或 XOR? 逐位比较两个二进制数,相同,则结果位为0,不相同则结果位为1。
如下图,5和9的结果经过二进制逐位计算后,结果为12:
-
本题如果用常规方法,暴力遍历,会超时。
-
异或运算的升华理解:
异或运算本质上是二进制中1的个数的奇偶性,如果1的个数为奇数个,结果就是1;1的个数为偶数个,结果就是0. -
那么怎么样才能让异或的结果最大呢?就是让从高位到低位,结果所包含的0和1尽可能的不一样。
-
如此就可以将问题转化为,当我们拿到一个数字a的时候,找到另一个数字b,使得b和a从高位到低位,尽可能得不一样。 转化成了这样一个等价问题。
比如当前数字a为“1001”, 那么目标数字b的最高位尽可能为0, 然后第二位尽可能是1, 第三位和第四位尽可能是1,0,也就是说b尽可能是“0110”。
-
所以可以把每个数字转换为二进制,分别插入字典树中去(对于本题需要一个二叉字典树,每个节点下面有两条边,一条代表0, 一条代表1)。
接下来就是拿着每个数字,在字典树中查找和当前数字“尽可能不一样的那个数字”。查找的过程中,就可以把结果算出来。
举例:
假设现在有三个数字,0110,1010,1100。构建二叉树以及查找“0110”对应的最大疑惑数字过程如下:
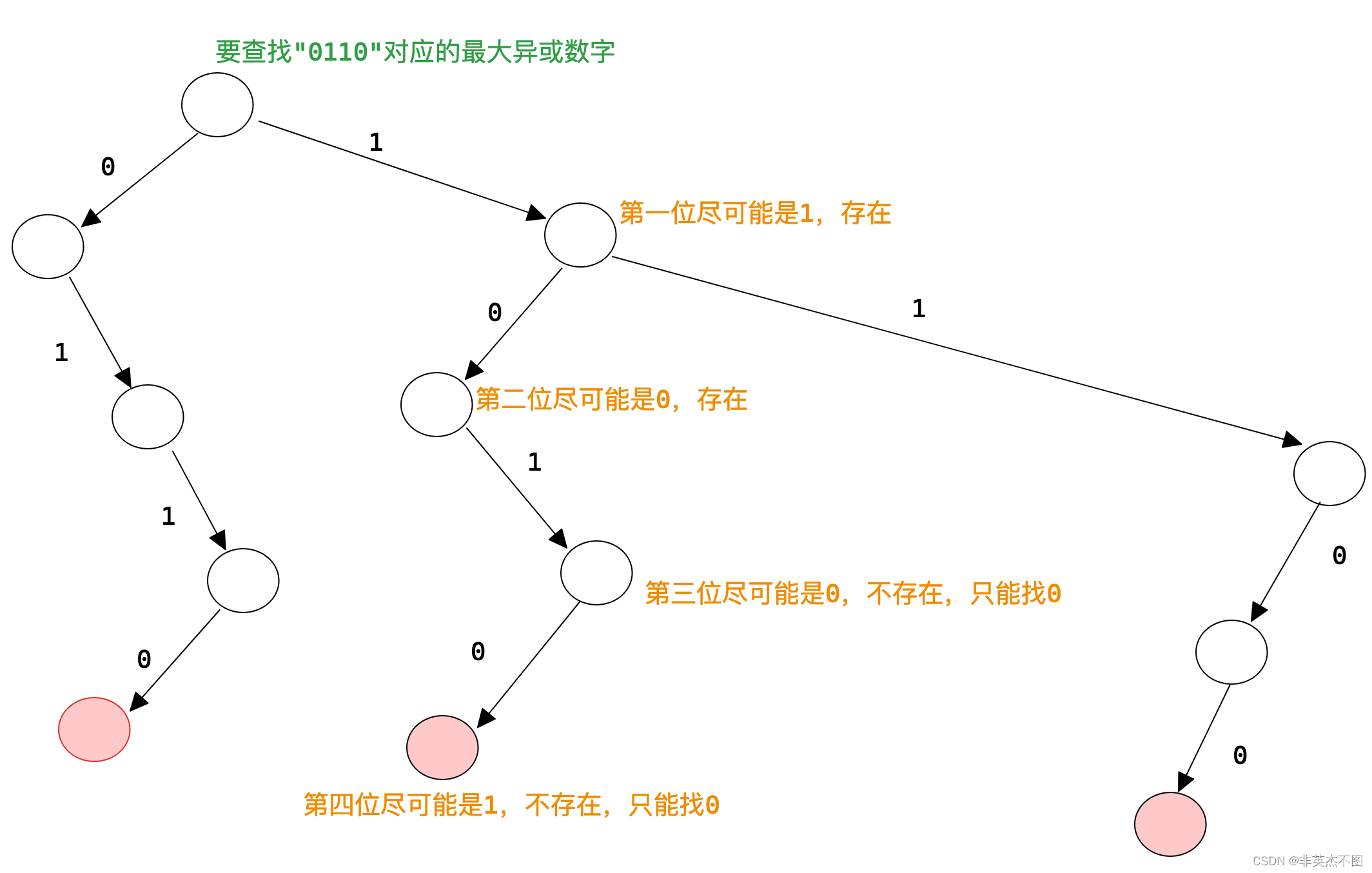
所以在这三个数字中,找到关于“0110”的最大异或数字就是“1010”。
代码演示:
class Node {
public:
Node() {
flag = 0;
for (int i = 0; i < 2; i++) {
next[i] = nullptr;
}
}
int flag;
Node * next[2]; //二叉字典树
};
class Trie {
public:
Trie() {
root = new Node();
}
void insert(int num) {
Node *p = root;
for (int i = 31; i >= 0; i--) {
//从高位到低位插入
int ind = (num & (1 << i)) > 0 ? 1 : 0;
//(也可以写作 !!(num & (1 << i))),c++中的归一化技巧
//num的第i位二进制
if (p->next[ind] == nullptr) p->next[ind] = new Node();
p = p->next[ind];
}
p->flag = true;
//在这种插入方式下,字典树的深度一定是32,
//而且一定是最后一层的所有节点flag均为true, 其余节点的flag都不是true
}
int search(int num) {
//返回当前字典树中和num形成的最大异或值是多少
Node *p = root;
int ret = 0;
int target = 0;
for (int i = 31; i >= 0; i--) {
int ind = (num & (1 << i)) > 0 ? 1 : 0; //与num的第i位二进制相同
//(也可以写作 !!(num & (1 << i)))
int ind_diff = 1 - ind; //与num的第i位二进制不同
if (p->next[ind_diff] != nullptr) { //首先查找i位二进制不同的
p = p->next[ind_diff];
if (ind_diff == 1) target |= (1 << i);
}else if (p->next[ind] != nullptr) { //再查找i位二进制相同的
p = p->next[ind];
if (ind == 1) target |= (1 << i);
}
}
return target ^ num; //查到了最后一层,最后一层的flag一定是true
}
Node *root;
};
class Solution {
public:
int findMaximumXOR(vector<int>& nums) {
Trie trie;
for (auto x : nums) trie.insert(x);
int ret = 0;
for (auto x : nums) {
int temp = trie.search(x);
if (temp > ret) ret = temp;
}
return ret;
}
};
代码提交结果:

总结:异或的深化理解,用二叉字典树解决问题,查找时有目的的查找,而不是像普通字典树那样查找相同的。
241. 为运算表达式设计优先级
题目解析:
要给出一个表达式所有的可能结果,表达式的结果和运算符的运算顺序有关系。
给一个表达式加不同的括号,所影响的也就是表达式的运算顺序。
所以问题就是如何枚举表达式运算符的顺序。
把表达式看成一棵树,树的根节点就是表达式中最后一个需要计算的运算符。
例如“2 - 1 - 1”,有以下两种可能的运算顺序:
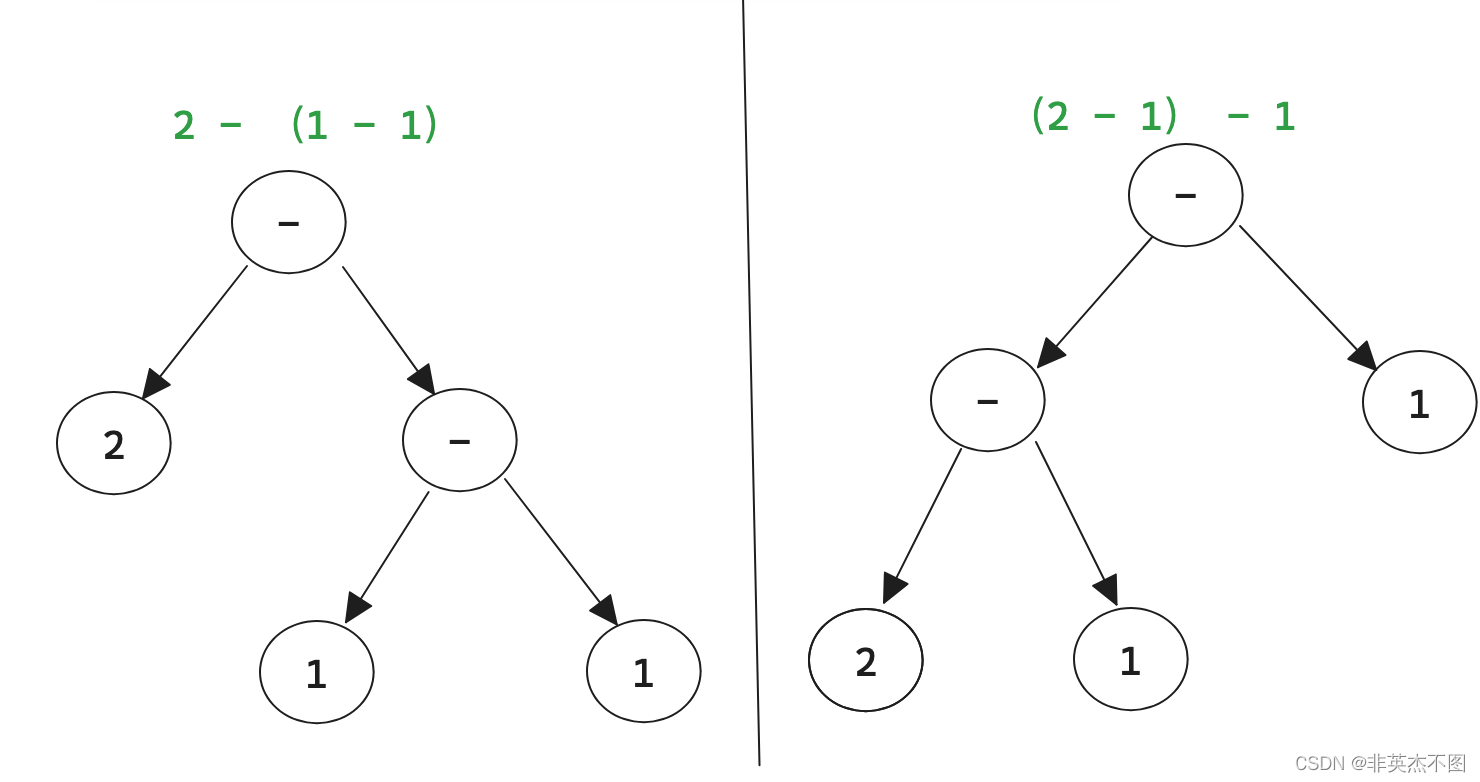
递归问题,枚举表达式根节点的问题,将当前表达式中所有运算符都当做根节点,去计算一遍,获得当前运算符 左边所有的可能结果,和右边所有的可能结果,左右两边所有的可能结果之间做个组合,然后就可以得到当前运算符作为根节点时,所有的可能结果。
例如最后一个运算符时“+”,此时左边所有可能结果是【2,3,9】,右边所有可能的结果是【5,7】,那么最终结果就有六种可能(2+5, 2+7, 3+5, 3+7, 9+5, 9+7)。
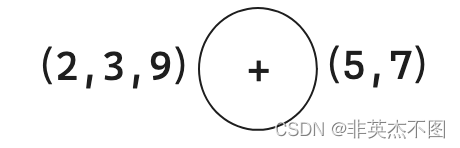
class Solution {
public:
vector<int> diffWaysToCompute(string expression) {
vector<int> ret;
for (int i = 0; expression[i]; i++) {
char op = expression[i];
if (op != '+' && op != '-' && op != '*') {
continue;
}
string a_str = expression.substr(0, i);
string b_str = expression.substr(i + 1, expression.size());
vector<int> a = diffWaysToCompute(a_str);
vector<int> b = diffWaysToCompute(b_str);
for (auto x : a){
for (auto y : b) {
switch (op) {
case '+' : ret.push_back(x + y); break;
case '-' : ret.push_back(x - y); break;
case '*' : ret.push_back(x * y); break;
}
}
}
}
if (ret.size() == 0) {
int num = 0;
for (auto x : expression) {
num = num * 10 + (x - '0');
}
ret.push_back(num);
}
return ret;
}
};
提交结果:

总结:整体思路较为清晰,就是需要把一个表达式看成一棵二叉树。
LeetCode 133. 克隆图


题目解析:可以在深度遍历的过程中克隆,遍历的过程中某些节点可能遍历过,此时可以用一个哈希表来记录克隆的节点。
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
unordered_map<Node *, Node *> h;
Node* cloneGraph(Node* node) {
if (node == nullptr) return nullptr;
Node *node1 = new Node(node->val);
if (h[node]) return h[node]; //之前克隆过
h[node] = node1;
for (int i = 0; i < node->neighbors.size(); i++) {
node1->neighbors.push_back(cloneGraph(node->neighbors[i]));
}
// printf("node val : %d ", node1->val);
// for (int i = 0; i < node1->neighbors.size(); i++) {
// printf("i : %d , nei[i]: %d ", i, node1->neighbors[i]->val);
// }
// printf("\n");
return node1;
}
};
代码提交结果:

总结:图的深度遍历,用哈希表记录是否遍历过。
LeetCode 987. 二叉树的垂序遍历
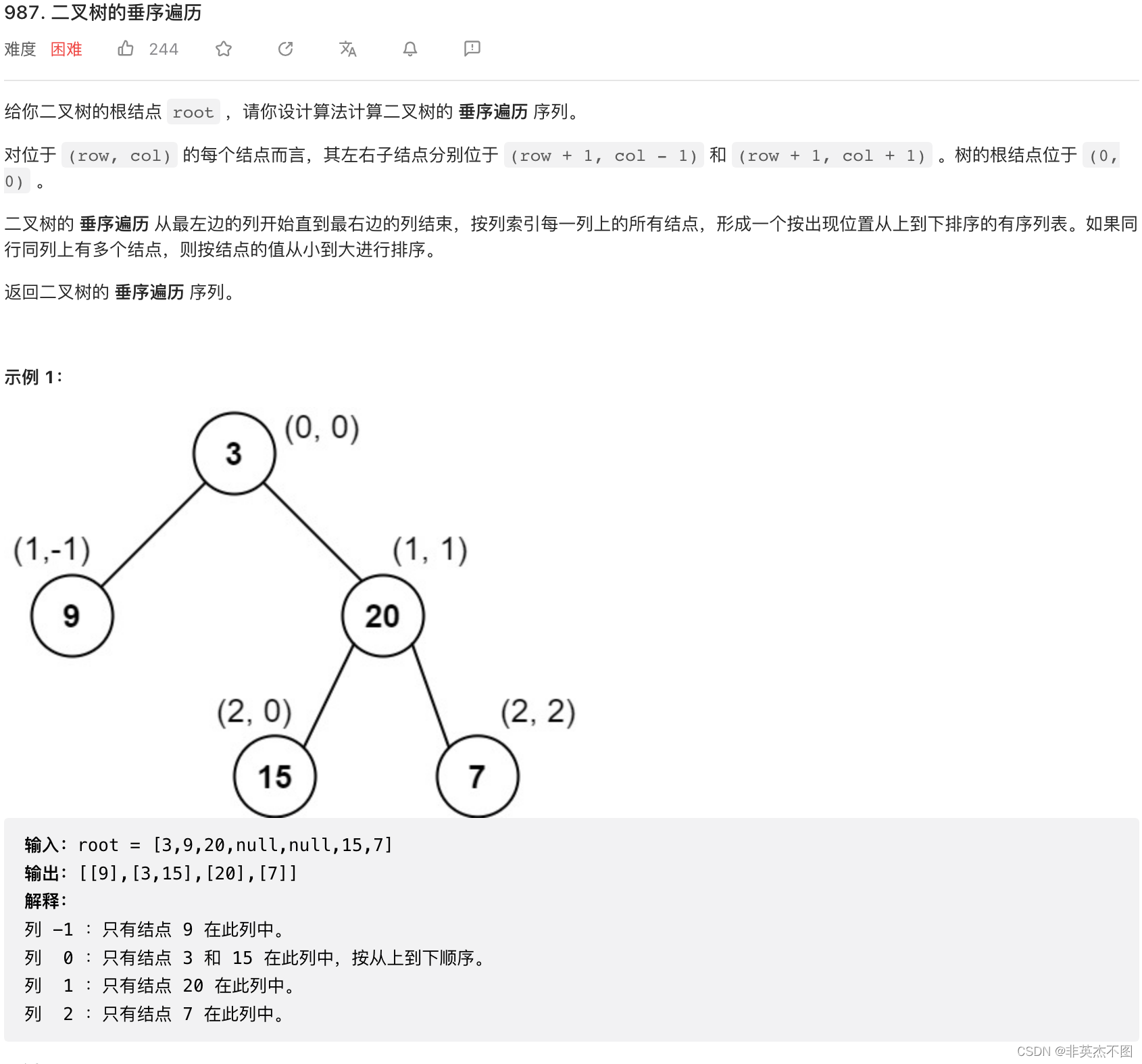
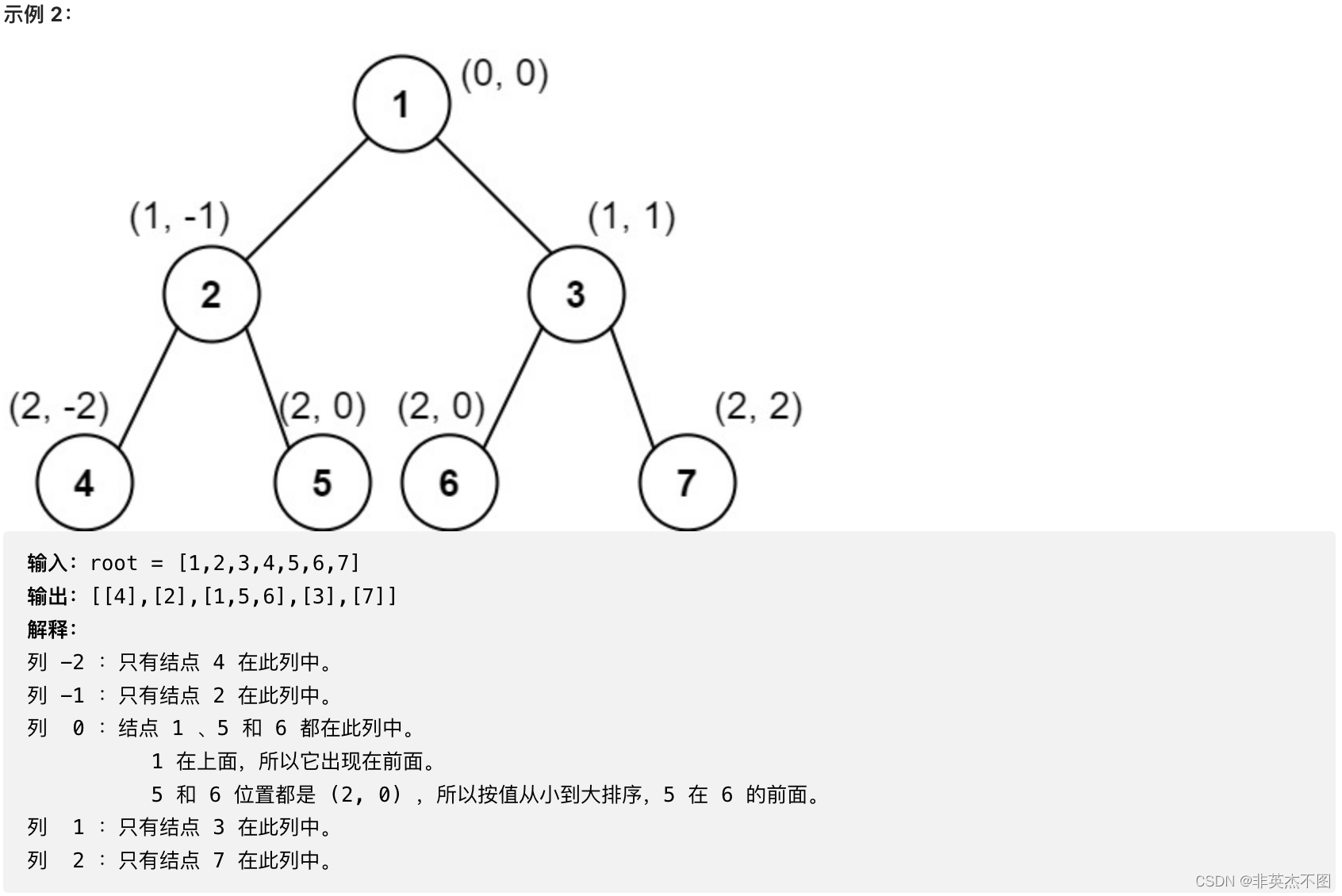
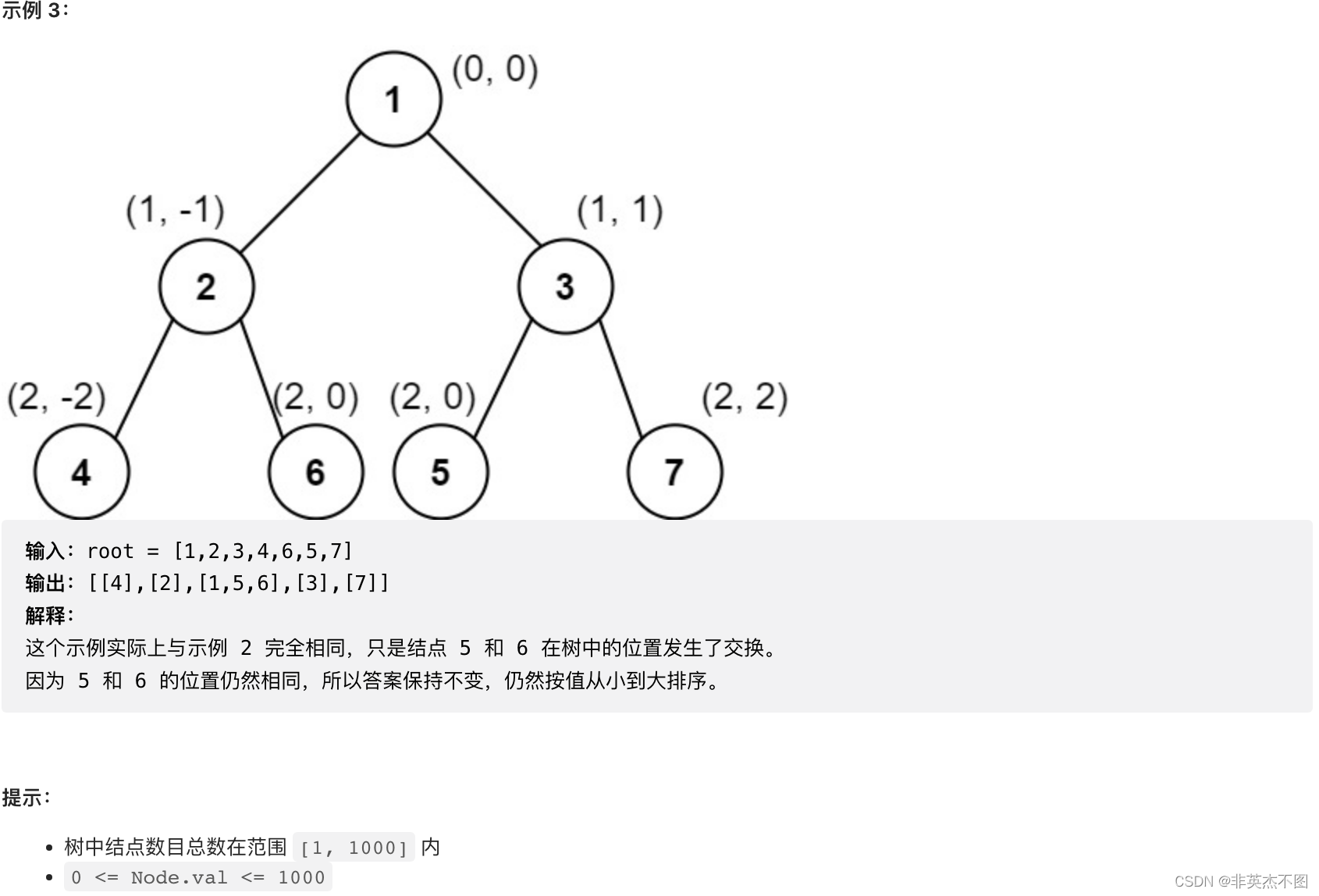
解题思路:
可以首先遍历这棵树,然后把这棵树种的每个节点,和节点相应的坐标,打包到一块儿,最后把打包的信息,按照题目要求,整理成题目需要的样子。
在这个处理过程中,涉及到了信息转换的问题,所以本题主要考察信息转换的能力。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
typedef pair<int, int> PII;
map<int, vector<PII>> h; //j, [<i, val>] //哈希表用红黑树实现,遍历时key是有序的
void getResult(TreeNode *root, int i, int j) { //深度遍历
if (root == nullptr) return;
int val = root->val;
h[j].push_back(PII(i, val));
getResult(root->left, i + 1, j - 1);
getResult(root->right, i + 1, j + 1);
return;
}
vector<vector<int>> verticalTraversal(TreeNode* root) {
getResult(root, 0, 0); //信息转换存储到哈希表中
vector<vector<int>> ret;
for (auto item : h) {
// cout << item.first << endl;
// item.first代表k, item.second代表value
vector<PII> &arr = item.second;
sort(arr.begin(), arr.end()); //题目中要求的比较规则,正好就是c++中PII默认的比较规则
vector<int> temp;
for (auto x : arr) temp.push_back(x.second);
ret.push_back(temp);
}
return ret;
}
};
代码提交结果:

总结:将一个大问题转换为两个小问题,先把信息转换成哈希表的另一种形式,然后遍历哈希表,按照要求的格式来排序,给出结果。
LeetCode 611. 有效三角形的个数
题目分析:可以将数组排序后,依次遍历三角形的前两个边长,然后通过二分查找第三条边的边长,第三条边需满足:小于前两条边长之和即可。
所以二分查找相当于前面在给定范围的有序数组中查找第一个大于等于某个target的数,即前面一堆0,后面一堆1, 找第一个1;0代表小于某个target, 1代表大于等于这个target。
class Solution {
public:
int triangleNumber(vector<int>& nums) {
int n = nums.size();
if (n < 3) return 0;
int ret = 0;
sort(nums.begin(), nums.end());
for (int i = 0; i <= n - 3; i++) {
for (int j = i + 1; j <= n - 2; j++) {
// j + 1, n - 1, 000,111 找到第一个大于等于 ni + nj的下标
int l = j + 1, r = n; //r的选择假设数组的最后一位存在一个虚拟的数,这个数一定大于target。
int target = nums[i] + nums[j];
while (l < r) {
int mid = (l + r) / 2;
if (nums[mid] < target) {
l = mid + 1;
}else {
r = mid;
}
}
//l或r就是找到的下标
// printf("%d %d %d \n", i,j,l);
ret += (r - j - 1);
}
}
return ret;
}
};
代码提交结果:

总结:排序与巧用二分法。
LeetCode 440. 字典序的第K小数字

解析:可以将数字构造成一个字典树,即十叉树,然后前序遍历这个字典树,当遍历到第k个数的时候就找到了要求的数,但是这样构建字典树,再遍历的方法会超时。
但是本题中的字典树一定是一个完全树,即除了最后一层外其他层一定是满的,最后一层的节点都是靠左边的。因为1-n的数字是连续的。
所以给定一个节点值后,其实可以通过计算得到以这个节点为根节点时,字典树一共有多少个节点。
知道每个节点的节点值如何计算以后,就可以从“1”节点入手,去看每个节点下面有多少个节点,根据节点的个数和k的大小关系,判断下一步应该向子节点中去找,还是去下一棵树中去找。
而计算某个节点下面有多少个子节点,可以通过逐层计算的方式,第一层一定是一个节点(num),第二层一定是10个(num * 10,num * 10 + 1, …,num + 10 + 9),第三层100个,以此类推。如果某一层的最后一个数都小于等于n,那这层一定是满的,反之如果某一层的最后一个数(比如 num * 10000 + 9999)大于了n,这层就没有满,可以通过n和这层的第一个数的差得到这层的节点数量。
class Solution {
public:
int calNodeNum(int num, int n) {
int ret = 0;
int x = num, base = 1;
int thresh = 1e9; //thresh防止计算某一层节点的最后一个数的时候超过整数范围,如果num是个位数,thresh就是1e9,如果num是十位数,thresh就是1e8,以此类推。
while (x >= 10) {
x /= 10;
thresh /= 10;
}
//base代表这一层的节点个数
while (num * base + base - 1 <= n) {
ret += base;
base *= 10;
if (base == thresh) break; //因为while循环中num * base + base - 1 可能会超过整数的范围,所以提前判断一下,如果base的值到了一定阈值,那就直接不从一层去找了,因为一定不存在。
}
if ((base < thresh) && (num * base <= n)){
ret += (n - num * base + 1); //最后一层没满,base >= thresh的时候一定不存在最后一层
}
// printf("num %d, n %d, ret %d\n", num, n, ret);
return ret;
// 10 11 12 13 14
}
int findFromNumber(int num, int n, int k) {
if (k == 1) return num; //前序遍历num节点的第一个数就是num
int nodeNum = calNodeNum(num, n); //num节点为根节点时一共有多少个节点
// printf("num %d, n %d, k %d, nodeNum %d \n", num, n, k, nodeNum);
if (nodeNum < k) return findFromNumber(num + 1, n, k - nodeNum); //当前根节点的节点个数太少,从下一个节点去找
if (nodeNum >= k) return findFromNumber(num * 10, n, k - 1);
//当前树的节点的个数较多,从第一个子节点树中去找。
return 0;
}
int findKthNumber(int n, int k) {
return findFromNumber(1, n, k);
}
};
代码提交结果:
总结:也是字典树的思想,前序遍历。相当于构建了一棵字典树,而且构建的时候记录了每个节点下方的总节点个数。但是由于本题数据的特殊性质,不需要真正构建一棵树,每个节点下方的节点个数也可以通过计算来得到。















 3709
3709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









