







 超级会员免费看
超级会员免费看
语音处理理论和应用
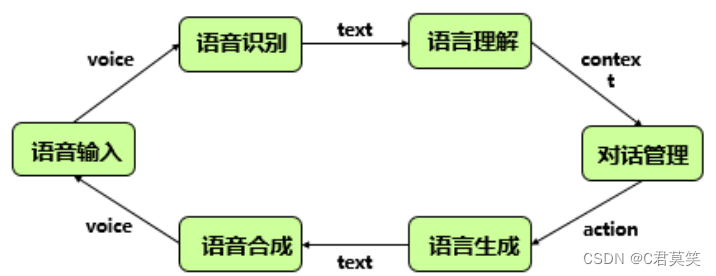
语音处理介绍
语音处理
语音信号处理(语音处理)
语音文件一般为wav格式。下图可视化的音频文件,横坐标为采样点数,纵坐标为幅度。
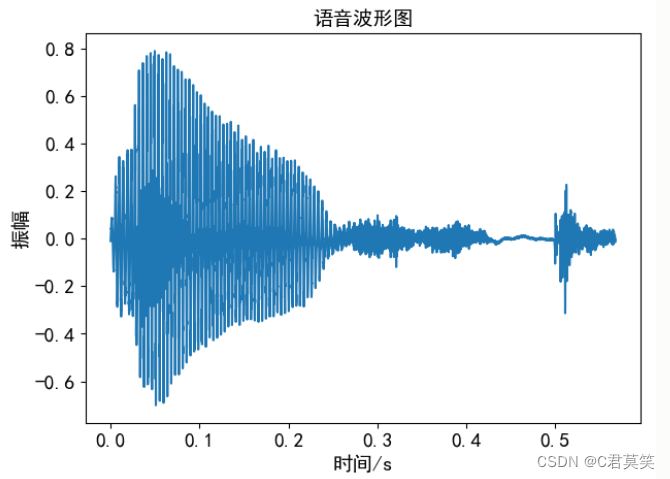
音频信号主要的问题
- 波形数据的分布非常不均匀。
- 开头和结尾的静音部分。
- 波形中含有噪音部分。
语音信号预处理步骤
- 数字化:将从传感器采集的模拟语音信号离散化为数字信号
- 预加重:预加重的目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率
- 端点检测:从语音信号中识别并消除长时间静音段,减少环境对信号的干扰
- 分帧:因为语音的短时平稳性,所以要进行“短时分析”,即将信号分段,每一段称为一帧(一般10-30ms
)–分帧虽然可以采用连续分段的方法,但一般要采用交叠分段的方法 - 加窗:语音信号的分帧是采用可移动的有限长度窗口进行加权的方法来实现的。加窗的目的是减少语音帧的截断效应。常见的窗有:矩形窗、汉宁窗和汉明窗等
语音信号分析和特征提取
语音特征
-
描述语音的

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











