







目录
在机器学习应用中,特征工程介于数据和算法之间,特征工程是将原始数据转化为特征,进而使我们能够从各种各样新的维度来对样本进行刻画。特征可以更好地向预测模型描述潜在的问题,从而提高模型对未见数据进行预测分析的准确性。高质量的特征有助于提高模型整体的泛化性能,特征在很大程度上与基本问题相关联。
特征工程主要分为数据预处理、特征变换、特征提取、特征选择这四个部分。
1. 数据预处理
数据质量直接决定了模型的准确性和泛化能力的高低,同时在构造特征时也会影响其顺畅性。因此,在竞赛提供的数据质量不高的情况下,就需要对数据进行预处理,对各种脏数据进行对应方式的处理,从而得到标准的、干净的、连续的数据,供数据统计、数据挖掘等使用。同时,我们也要视情况尝试对缺失值进行处理,比如是否需要进行填补,如果填补的话,是填补均值还是中位数等。此外,有些竞赛提供的数据以及对应的存储方式可能使得需要占用超过参赛者本⾝硬件条件的内存,因此有必要进行⼀定的内存优化,这也有助于在有限的内存空间中对更大的数据集进行操作。
1.1 缺失值处理
面对数据缺失问题,除了 XGBoost 和 LightGBM 等算法在训练时可以直接处理缺失值以外,其他很多算法(如 LR、DNN、CNN、RNN 等)并不能对缺失值进行直接处理。在数据准备阶段,要比构建算法阶段花费更多的时间,因为像填补缺失值这样的操作需要细致处理,以免在处理过程中出现错误并影响模型训练效果。
-
区分缺失值
首先,参赛者需要找到缺失值的表现形式。缺失值的表现除了 None、NA 和 NaN 这些,还包括其他用于表示数值缺失的特殊数值,例如使用 –1 或者 –999 来填充的缺失值。还有⼀种是看着像缺失值,却有实际意义的业务,这种情况就需要特殊对待。例如,没有填写 “婚姻状态” 这⼀项的用户可能对自己的隐私比较敏感,应为其单独设为⼀个分类,比如用值 1 表示已婚,值 0 表示未婚,值 –1 表示未填;没有填写 “驾龄” 这一项的用户可能是没有车,为其填充 0 比较合理。当找出缺失值后,就需要根据不同应用场景下缺失值可能包含的信息进行合理填充。 -
处理方法
数据缺失可以分为类别特征的缺失和数值特征的缺失两种,它们的填充方法存在很大的差异。对于类别特征,通常会填充⼀个新类别,可以是 0、–1、负无穷等。对于数值特征,最基本的方法是均值填充,不过这个方法对异常值比较敏感,所以可以选择中位数进行填充,这个方法对异常值不敏感。另外,就是在进行数据填充的时候,⼀定要考虑所选择的填充方法会不会影响数据的准确性。对填充方法的总结如下:- 对于类别特征:可以选择最常见的⼀类填充方法,即填充众数;或者直接填充一个新类别,比如 0、–1、负无穷。
- 对于数值特征:可以填充平均数、中位数、众数、最大值、最小值等。具体选择哪种统计值,需要具体问题具体分析。
- 对于有序数据(比如时间序列):可以填充相邻值 next 或者 previous。
- 模型预测填充:普通的填充只是⼀个结果的常态,并未考虑其他特征之间相互作用的影响,可以对含有缺失值的那⼀列进行建模并预测其中缺失值的结果。虽然这种方法比较复杂,但是最后得到的结果直觉上比直接填充要好,不过在实际竞赛中的效果则需要具体检验。
1.2 异常值处理
在实际数据中,常常会发现某个或某些字段(特征)根据某个变量(比如时间序列问题中的时间)排序后,经观察发现存在⼀些数值远远高于或低于其⼀定范围内的其他数值。还有⼀些不符合常态的存在,例如广告点击⽤户中出现年龄为 0 或超过 100 的情况。这些我们都可以当作异常值,它们的存在可能会给算法性能带来负作用。
- 寻找异常值
在处理异常值之前,首先需要找出异常值,这里我们针对数值特征的异常值总结了两种常用的方法:- 第一种是通过可视化分析的方法来发现异常值。简单使用散点图,我们能很清晰地观察到异常值的存在,严重偏离密集区域的点都可以当作异常值来处理。
- 第二种是通过简单的统计分析来发现异常值,即根据基本的统计方法来判断数据是否存在异常。例如,四分位数间距(箱线图)、极差、均差、标准差等,这种方法适合于挖掘单变量的数值型数据,离散型异常值(离散属性定义范围以外的所有值均为异常值)、知识型异常值(比如身高 10 米)等,都可以当作类别缺失值来处理。
- 处理异常值
- 删除含有异常值的记录。这种办法的优点是可以消除含有异常值的样本带来的不确定性,缺点是减少了样本量。
- 视为缺失值。将异常值视为缺失值,利用缺失值处理的方法进行处理。这种办法的优点是将异常值集中化为一类,增加了数据的可用性;缺点是将异常值和缺失值混为一谈,会影响数据的准确性。
- 平均值(中位数)修正。可用对应同类别的数值使用平均值修正该异常值,优缺点同 “视为缺失值”。
- 不处理。直接在具有异常值的数据集上进行数据挖掘。这种办法的效果好坏取决于异常值的来源,若异常值是录入错误造成的,则对数据挖掘的效果会产生负面影响;若异常值只是对真实情况的记录,则直接进行数据挖掘能够保留最真实可信的信息。
1.3 优化内存
在参加机器学习相关竞赛时,赛题涉及的数据往往较大,并且参赛者自身的计算机硬件条件有限,所以常常会因为内存不够导致代码出现 memory error,给参赛者带来困扰。因此,有必要介绍一些有助于优化内存的方法,最大限度地运行代码。这里我们将介绍 Python 的内存回收机制和数值类型优化这两种常见方法。
- 内存回收机制。在 Python 的内存回收机制中,gc 模块主要运用 “引用计数” 来跟踪和回收垃圾。在引用计数的基础上,还可以通过 “标记清除” 解决容器对象可能产生的循环引用问题,通过 “隔代回收” 以空间换取时间来进⼀步提高垃圾回收的效率。一般来说,在我们删除一些变量时,使用 gc.collect() 来释放内存。
- 数值类型优化。竞赛中常用的数据保存格式是 csv 以及 txt,在进行处理时,需要将其读取为表格型数据,即 DataFrame 格式。这就需要利用 pandas 工具包进行操作,pandas 可以在底层将数值型数据表示成 NumPy 数组,并使之在内存中连续存储。这种存储方式不仅消耗的空间较少,并且允许我们快速访问数据。由于 pandas 使用相同数量的字节来表示同一类型的每一个值,并且 NumPy 数组存储着这些值的数量,所以 pandas 能够快速、准确地返回数值型列消耗的字节量。
pandas 中的许多数据类型具有多个子类型,它们可以使用较少的字节表示不同数据。比如,float 类型有 float16、float32 和 float64 这些子类型。这些类型名称的数字部分表明了这种类型使用多少比特来表示数据。⼀个 int8 类型的数据使用 1B(8bit)存储⼀个值,可以表示 256( 2 8 2^8 28)个二进制数值,这意味着我们可以用这种子类型去表示 –128 和 127(包括 0)之间的数值。
我们可以用 np.iinfo 类来确认每⼀个 int 型子类型的最小值和最大值,代码如下:
import numpy as np
np.iinfo(np.int8).min
np.iinfo(np.int8).max
然后,我们可以通过选择某列特征的最小值和最大值来判断特征所属的子类型,代码如下:
c_min = df[col].min()
c_max = df[col].max()
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
此外,在不影响模型泛化性能的情况下,对于类别型的变量,若其编码 ID 的数字较大、极不连续而且种类较少,则可以重新从 0 开始编码(自然数编码),这样也能减少变量的内存占用。而对于数值型的变量,常常由于存在浮点数使得内存占用过多,可以考虑先将其最小值和最大值归一化,然后乘以 100、1000 等,之后取整,这样不仅可以保留同⼀变量之间的大小关系,还极大地减少了内存占用。
2. 特征变换
数据预处理结束之后,有时参赛者还需要对特征进行一些数值变换,且在实际竞赛中,很多原始特征并不能直接使用,这时就需要进行一定的调整,以帮助参赛者更好地构造特征。
2.1 连续变量无量纲化
无量纲化指的是将不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,特征值服从标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特定的范围,例如 [0, 1]。
单特征转换是构建一些模型(如线性回归、KNN、神经网络)的关键,对决策树相关模型没有影响,这也是决策树及其所有衍生算法(随机森林、梯度提升)日益流行的原因之⼀。还有一些纯粹的工程原因,即在进行回归预测时,对目标取对数处理,不仅可以缩小数据范围,而且压缩变量尺度使数据更平稳。这种转换方式仅是⼀个特殊情况,通常由使数据集适应算法要求的愿望驱动。
然而,数据要求不仅是通过参数化方法施加的。如果特征没有被规范化,例如当⼀个特征的分布位于 0 附近且范围不超过 (–1, 1),而另⼀个特征的分布范围在数十万数量级时,会导致分布位于 0 附近的特征变得完全无用。
举一个简单的例子:假设任务是根据房间数量和到市中心的距离这两个变量来预测公寓的成本。公寓房间数量⼀般很少超过 5 间,而到市中心的距离很容易达到几千米。此刻,使用线性回归或者 KNN 这类模型是不可以的,需要对这两个变量进行归一化处理。
- 标准化。最简单的转换是标准化(或零一均值规范化)。标准化需要计算特征的均值和标准差,其公式表达如式: x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ其中 μ \mu μ 表示均值, σ \sigma σ 表示方差。
- 区间缩放。区间缩放的思路有多种,常见的一种是利用两个最值进行缩放,可使所有点都缩放在预定的范围内,即 [0, 1]。区间缩放的公式表达如式: X n o r m = X − X m i n X m a x − X m i n X_{norm} = \frac{X - X_{min}}{X_{max} - X_{min}} Xnorm=Xmax−XminX−Xmin
2.2 连续变量数据变换
- log 变换
进行 log 变换可以将倾斜数据变得接近正态分布,这是因为大多数机器学习模型不能很好地处理非正态分布的数据,比如右倾数据。可以应用 l o g ( x + 1 ) log(x+1) log(x+1) 变换来修正倾斜,其中加 1 的目的是防止数据等于 0,同时保证 x x x 都是正的。取对数不会改变数据的性质和相关关系,但是压缩了变量的尺度,不仅数据更加平稳,还削弱了模型的共线性、异方差性等。 - 连续变量离散化
离散化后的特征对异常数据有很强的健壮性,更便于探索数据的相关性。例如,把年龄特征离散化后的结果是:如果年龄大于 30,则为 1,否则为 0。如果此特征没有离散化,那么一个异常数据 “年龄 300 岁”会给模型造成很大的干扰。离散化后,我们也能对特征进行交叉组合。常用的离散化分为无监督和有监督两种。- 无监督的离散化
分桶操作可以将连续变量离散化,同时使数据平滑,即降低噪声的影响。一般分为等频和等距两种分桶⽅式。- 等频。区间的边界值要经过选择,使得每个区间包含数量大致相等的变量实例。比如分成 10 个区间,那么每个区间应该包含大约 10% 的实例。这种分桶方式可以将数据变换成均匀分布。
- 等距。将实例从最小值到最大值,均分为 N N N 等份,每份的间距是相等的。这里只考虑边界,每等份的实例数量可能不等。等距可以保持数据原有的分布,并且区间越多对数据原貌保持得越好。
- 有监督的离散化
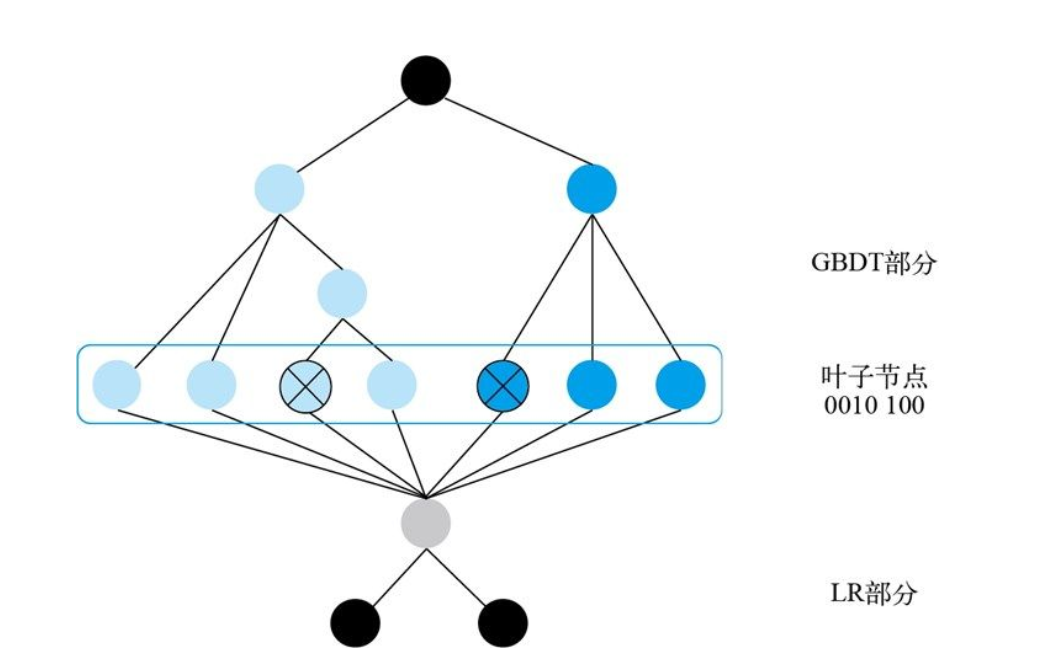
这类方法对目标有很好的区分能力,常用的是使用树模型返回叶子节点来进行离散化。在下图所示的 GBDT + LR 经典模型中,就是先使用 GDBT 来将连续值转化为离散值。
具体方法:用训练集中的所有连续值和标签输出来训练 LightGBM,共训练两棵决策树,第一棵树有 4 个叶⼦节点,第二棵树有 3 个叶子节点。如果某一个样本落在第一棵树的第三个叶⼦节点上,落在第二棵树的第一个叶子节点上,那么它的编码就是 0010 100,⼀共 7 个离散特征,其中会有两个取值为 1 的位置,分别对应每棵树中样本落点的位置。最终我们会获得 num_trees*num_leaves 维特征。
- 无监督的离散化
2.3 类别特征转换
在实际数据中,特征并不总是数值,还有可能是类别。对于离散型的类别特征进行编码,一般分为两种情况:自然数编码(特征有意义)和独热编码(特征没有意义)。
- 自然数编码。
一列有意义的类别特征(即有顺序关系)可以用自然数进行编码,利用自然数的大小关系可以保留其顺序关系。此外,当特征不是用数字而是用字母或符号等表示时,是无法直接被 “喂” 到模型里作为训练标签的,比如年龄段、学历等,这时候就需要先把特征取值转换成数字。如果一列类别特征里有 K K K 个取值,那么经过自然数编码后,可以得到取值为 { 0 , 1 , 2 , ⋯ , K − 1 } \{0, 1, 2, \cdots, K-1 \} {0,1,2,⋯,K−1} 的数字,即给每⼀个类别分别分配⼀个编号。这样做的优点是内存消耗小、训练时间快,缺点是可能会丢失部分特征信息。下⾯将给出两种自然数编码的常用方式:- 调用 sklearn 中的函数:
from sklearn import preprocessing for f in columns: le = preprocessing.LabelEncoder() le.fit(data[f])- 自定义实现(速度快):
for f in columns: data[f] = data[f].fillna(-999) data[f] = data[f].map(dict(zip(data[f].unique(), range(0, data[f].nunique())))) - 独热编码
当类别特征没有意义(即没有顺序关系)时,需要使用独热编码。例如,红色>蓝色>绿色 不代表任何东西,进行独热编码后,每个特征的取值对应一维特征,最后得到的是一个 样本数 × 类别数大小 的 0-1 矩阵。可以直接调用 sklearn 中的 API。
2.4 不规则特征变换
除了数值特征与类别特征之外,还有一类不规则特征可能包含样本的很多信息,比如身份证号。由百度百科查得,根据《中华人民共和国国家标准GB 11643—1999》中有关公民身份号码的规定,公民身份号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为:六位数字地址码、八位数字出生日期码、三位数字顺序码和⼀位数字校验码。其中顺序码的奇数分给男性,偶数分给女性。校验码是根据前面十七位数字码,按照 ISO 7064:1983.MOD 11-2 校验码计算出来的检验码。因此,我们可以从身份证号获得用户的出生地、年龄、性别等信息。当然,身份证号涉及用户隐私,在竞赛中主办方不可能提供这个信息,在此仅作为举例。
3. 特征提取
下⾯我们将介绍结构化数据的特征提取方式。(结构化数据由明确定义的数据类型组成,非结构化数据由音频、视频和图片等不容易搜索的数据组成。)
3.1 类别相关的统计特征
类别特征又可以称为离散特征,除了每个类别属性的特定含义外,还可以构造连续型的统计特征,以挖掘更多有价值的信息,比如构造目标编码、count、nunique 和 ratio 等特征。另外,也可以通过类别特征间的交叉组合构造更加细粒度的特征。
-
目标编码
目标编码可以理解为用目标变量(标签)的统计量对类别特征进行编码,即根据目标变量进行有监督的特征构造。如果是分类问题,可以统计正样本个数、负样本个数或者正负样本的比例;如果是回归问题,则可以统计目标均值、中位数和最值。目标编码方式可以很好地替代类别特征,或者作为新特征。
使用目标变量时,非常重要的一点是不能泄露任何验证集的信息。所有基于目标编码的特征都应该在训练集上计算,测试集则由完整的训练集来构造。更严格一点,我们在统计训练集的特征时,需要采用 K K K 折交叉统计法构造目标编码特征,从而最大限度地防止信息泄露。如下图所示,我们将样本划分为五份,对于其中每一份数据,我们都将用另外四份来计算每个类别取值对应目标变量的频次、比例或者均值,简单来说就是未知的数据(一份)在已知的数据(四份)里面取特征。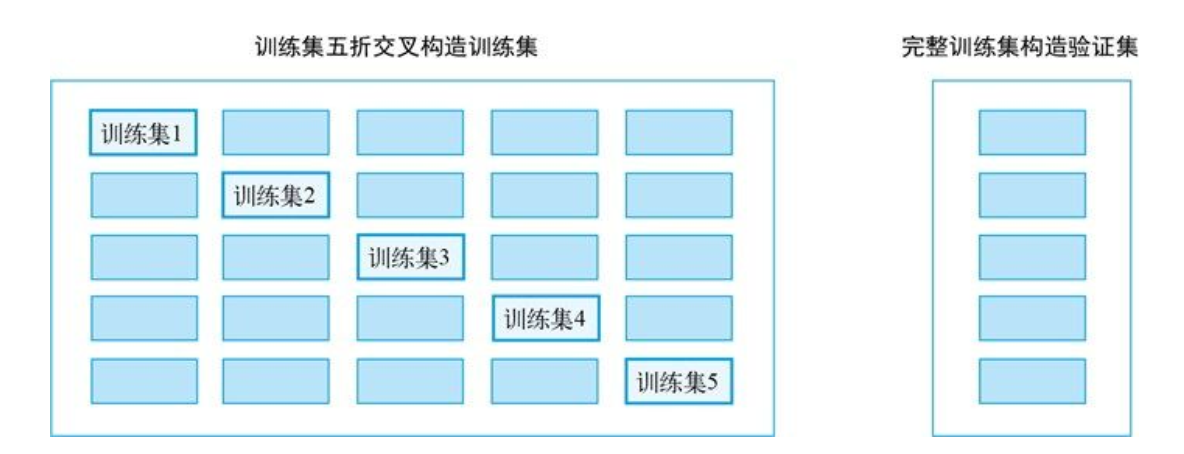
folds = KFold(n_splits=5, shuffle=True, random_state=2020) for col in columns: colname = col+'_kfold' for fold_, (trn_idx, val_idx) in enumerate(folds.split(train, train)): tmp = train.iloc[trn_idx] order_label = tmp.groupby([col])['label'].mean() train[colname] = train[col].map(order_label) order_label = train.groupby([col])['label'].mean() test[colname] = test[col].map(order_label) -
count、nunique、ratio
这三类是竞赛中类别特征经常使用的构造方式。count(计数特征)用于统计类别特征的出现频次。nunique 和 ratio 的构造相对复杂一些,经常会涉及多个类别特征的联合构造,例如在广告点击率预测问题中,对于用户 ID 和广告 ID,使用 nunique 可以反映用户对广告的兴趣宽度,也就是统计用户 ID 看过几种广告 ID;使用 ratio 可以反映用户对某类广告的偏好程度,也就是统计用户 ID 点击某类广告 ID 的频次占用户点击所有广告 ID 频次的比例。当然,这也使用于其他问题,比如恶意攻击、反欺诈和信用评分这类需要构造行为信息或分布信息描述的问题。 -
类别特征之间交叉组合
交叉组合能够描述更细粒度的内容。对类别特征进行交叉组合在竞赛中是一项非常重要的工作,这样可以进行很好的非线性特征拟合。如下图所示,用户年龄和用户性别可以组合成 “年龄_性别” 这样的新特征。一般我们可以对两个类别或三个类别特征进行组合,也称作二阶组合或三阶组合。简单来说,就是对两个类别特征进行笛卡尔积的操作,产生新的类别特征。在实际数据中,可能会有很多类别特征。如果有 10 种类别特征并考虑所有的二阶交叉组合,则能够产生 45 种组合。
3.2 数值相关的统计特征
这里所说的数值特征,我们认为是连续的,例如房价、销量、点击次数、评论次数和温度等。不同于类别特征,数值特征的大小是有意义的,通常不需要处理就可以直接 “喂” 给模型进行训练。除了在前面对数值特征进行各种变换外,还存在一些其他常见的数值特征构造方式。
- 数值特征之间的交叉组合
不同于类别特征之间的交叉组合,一般对数值特征进行加减乘除等算术操作类的交叉组合。这需要我们结合业务理解和数据分析进行构造,而不是⼀拍脑袋式的暴力构造。例如给出房屋大小(单位为平方米)和售价,就可以构造每平方米的均价;又或者给出用户过去三个月每月的消费金额,就可以构造这三个月的总消费金额和平均消费金额,以反映用户的整体消费能力。 - 类别特征和数值特征之间的交叉组合
除了类别特征之间和数值特征之间的交叉组合外,还可以构造类别特征与数值特征之间的交叉组合。这类特征通常是在类别特征的某个类别中计算数值特征的⼀些统计量,比如均值、中位数和最值等。 - 按行统计相关特征
这种方式有点类似特征交叉,都是将多列特征的信息组合起来。但是行统计在构造时会包含更多的列,直接对多列按行进行统计,例如按行统计 0 的个数、空值个数和正负值个数,又或是均值、中位数、最值或者求和等。多列特征可能是每个月的消费金额、用电量,在工业数据上可以是化学实验各阶段的温度、浓度等。对于这些含有多列相关特征的数据,我们都需要分析多列数值的变化情况,并从中提取有价值的特征。
3.3 时间特征
在实际数据中,通常给出的时间特征是时间戳属性,所以首先需要将其分离成多个维度,比如年、月、日、小时、分钟、秒钟。如果你的数据源来自不同的地理数据源,还需要利用时区将数据标准化。
除了分离出来的基本时间特征以外,还可以构造时间差特征,即计算出各个样本的时间与未来某一个时间的数值差距,这样这个差距是 UTC 的时间差,从而将时间特征转化为连续值,比如用户首次行为日期与用户注册日期的时间差、用户当前行为与用户上次行为的时间差等。
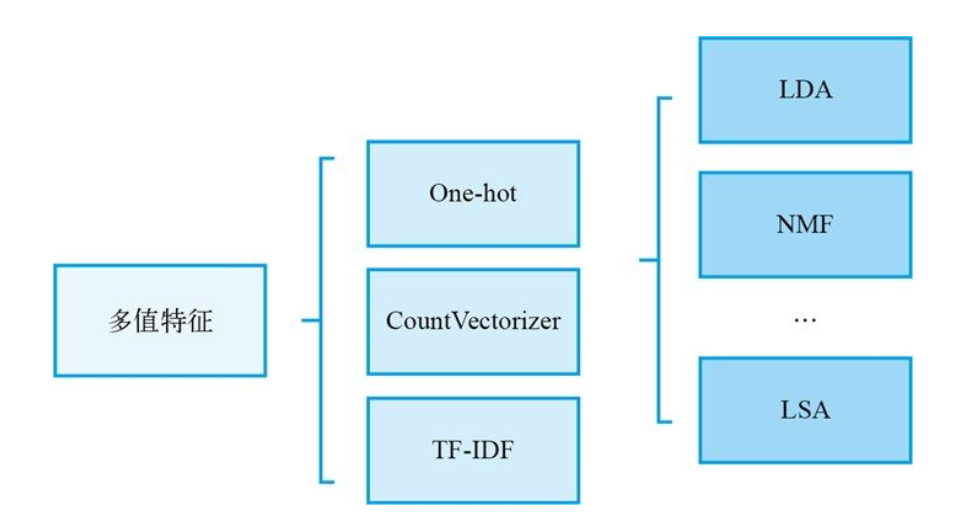
3.4 多值特征
在实际竞赛中,可能会遇到某一列特征中每行都包含多个属性的情况,这就是多值特征。例如 2018 腾讯广告算法大赛中的兴趣(interest)类目,其中包含 5 个兴趣特征组,每个兴趣特征组都包含若干个兴趣 ID。对于多值特征,通常可以进行稀疏化或者向量化的处理,这种操作一般出现在自然语言处理中,比如文本分词后使用 TF-IDF、LDA、NMF 等方式进行处理,这里则可以将多值特征看作文本分词后的结果,然后做相同的处理。
如下图所示,对多值特征最基本的处理办法是完全展开,即把这列特征所包含的
n
n
n 个属性展开成
n
n
n 维稀疏矩阵。使用 sklearn 中的 CountVectorizer 函数,可以方便地将多值特征展开,只考虑每个属性在这个特征的出现频次。
还有一种情况,比如在 2020 腾讯广告算法⼤赛中,需要根据用户的历史点击行为预测用户的属性标签。这时候用户的点击序列尤为重要,当我们构造好用户对应的历史点击序列后,除了使用上述的 TF-IDF 等方法外,还可以提取点击序列中商品或广告的嵌入表示,比如用 Word2Vec、DeepWalk 等方法获取 embedding 向量表示。因为要提取用户单个特征,所以可以对序列中的嵌入向量进行聚合统计,这种方法本质上是假设⽤用户点击过的商品或广告同等重要,是⼀种比较粗糙的处理方式。我们可以引入时间衰减因素,或者使用序列模型,如 RNN、LSTN、GRU,套⽤ NLP 的方法进行求解。
4. 特征选择
如下图所示,当我们添加新特征时,需要验证它是否确实能够提高模型预测的准确度,以确定不是加入了无用的特征,因为这样只会增加算法运算的复杂度,这时候就需要通过特征选择算法自动选择出特征集中的最优子集,帮助模型提供更好的性能。特征选择算法用于从数据中识别并删除不需要、不相关以及冗余的特征,这些特征可能会降低模型的准确度和性能。特征选择的方法主要有先验的特征关联性分析以及后验的特征重要性分析。

4.1 特征关联性分析
特征关联性分析是使用统计量来为特征之间的相关性进行评分。特征按照分数进行排序,要么保留,要么从数据集中删除。关联性分析方法通常是针对单变量的,并且独立考虑特征或者因变量。常见的特征关联性分析方法有皮尔逊相关系数、卡方检验、互信息法和信息增益等。这些方法的速度非常快,用起来也比较方便,不过忽略了特征之间的关系,以及特征和模型之间的关系。
-
皮尔逊相关系数(Pearson correlation coefficient)
这种方法不仅可以衡量变量之间的线性相关性,解决共线变量问题,还可以衡量特征与标签的相关性。共线变量是指变量之间存在高度相关关系,这会降低模型的学习可用性、可解释性以及测试集的泛化性能。很明显,这三个特性都是我们想要增加的,所以删除共线变量是一个有价值的步骤。我们将为删除共线变量建立一个基本的阈值(根据想要保留的特征数量来定),然后从高于该阈值的任何一对变量中删除一个。下面的代码用于解决特征与标签不具有相关性的问题,根据皮尔逊相关系数的计算提取 top300 的相似特征∶
def feature_select_pearson(train, features): featureSelect = features[:] # 进⾏⽪尔逊相关性计算 corr = [] for feat in featureSelect: corr.append(abs(train[[feat, 'target']].fillna(0).corr().values[0][1])) se = pd.Series(corr, index=featureSelect).sort_values(ascending=False) feature_select = se[:300].index.tolist() # 返回特征选择后的训练集 return train[feature_select] -
卡方检验
它用于检验特征变量与因变量的相关性。对于分类问题,一般假设与标签独立的特征为无关特征,而卡方检验恰好可以进行独立性检验,所以适用于特征选择。如果检验结果是某个特征与标签独立,则可以去除该特征。卡方公式如式: X 2 = ∑ ( A − E ) 2 E X^2 = \sum \frac{(A - E)^2}{E} X2=∑E(A−E)2 -
互信息法
互信息是对一个联合分布中两个变量之间相互影响关系的度量,也可以用来评价两个变量之间的相关性。
互信息法之所以能用于特征选择,可以从两个角度进行解释∶基于KL散度和基于信息增益。互信息越大说明两个变量相关性越高。互信息公式如式: M I ( x i , y ) = ∑ x i ∈ { 0 , 1 } ∑ y ∈ { 0 , 1 } p ( x i , y ) l o g ( p ( x i , y ) p ( x i ) p ( y ) ) MI(x_i, y) = \sum_{x_i \in \{ 0, 1\}} \sum_{y \in \{ 0, 1\}} p(x_i, y) log (\frac{p(x_i, y)}{p(x_i)p(y)}) MI(xi,y)=xi∈{0,1}∑y∈{0,1}∑p(xi,y)log(p(xi)p(y)p(xi,y))
这里的 p ( x i , y ) 、 p ( x i ) 、 p ( y ) p(x_i, y)、p(x_i)、p(y) p(xi,y)、p(xi)、p(y) 都是从训练集上得到的。想把互信息直接用于特征选择其实不是太方便,其主要原因有以下两点:- 它不属于度量方式,也没有办法归一化,无法对不同数据集上的结果进行比较。
- 对于连续变量的计算不是很方便( X 和 Y 都是集合, x i 、 y x_i、y xi、y 都是离散的取值),通常连续变量需要先离散化,而互信息的结果对离散化的方式很敏感。
4.2 特征重要性分析
在实际竞赛中,经常用到的一种特征选择方法是基于树模型评估特征的重要性分数。特征的重要性分数越高,说明特征在模型中被用来构建决策树的次数越多。这里我们以 XGBoost 为例来介绍树模型评估特征重三种计算方法 weight、gain和cover。(LightGBM 也可以返回特征重要性)
-
weight 计算方式
该方法比较简单,计算特征在所有树中被选为分裂特征的次数,并将此作为评估特征重要性的依据,代码示例如下:params = { 'max_depth': 10, 'subsample': 1, 'verbose_eval': True, 'seed': 12, 'objective':'binary:logistic' } xgtrain = xgb.DMatrix(x, label=y) bst = xgb.train(params, xgtrain, num_boost_round=10) importance = bst.get_score(fmap = '', importance_type='weight') -
gain 计算方式
gain 表示平均增益。在进行特征重要性评估时,使用 gain 表示特征在所有树中作为分裂节点的信息增益之和再除以该特征出现的频次。代码示例如下∶importance = bst.get_score(fmap = '', importance_type='gain') -
cover 计算方式
ocover 较复杂些,其具体合义是特征对每棵树的覆盖率,即特征被分到该节点的样本的二阶导数之和,而特征度量的标准就是平均覆盖率值。代码示例如下∶importance = bst.get_score(fmap = '', importance_type='cover')
使用技巧
虽然特征重要性可以帮助我们快速分析特征在模型训练过程中的重要性,但不能将其当作绝对的参考依据。一般而言,只要特征不会导致过拟合,我们就可以选择重要性高的特征进行分析和扩展,对于重要性低的特征,可以考虑将之从特征集中移除,然后观察线下效果,再做进一步判断。
4.3 封装方法
封装方法是一个比较耗时的特征选择方法。可以将对一组特征的选择视作一个搜索问题,在这个问题中,通过准备、评估不同的组合并对这些组合进行比较,从而找出最优的特征子集。搜索过程可以是系统性的,比如最佳优先搜索;也可以是随机的,比如随机爬山算法,或者启发式算法,比如通过向前和向后搜索来添加和删除特征(类似前剪枝和后剪枝算法)。
下面介绍两种常用的封装方法。
-
后发式方法
后发式方法分为两种:前向搜索和后向搜索。前向搜索说白了就是每次增量地从剩余未选中的特征中选出一个并将其加入特征集中,待特征集中的特征数量达到初设阈值时,意味着贪心地选出了错误率最小的特征子集。既然有增量加,就会有增量减,后者称为后向搜索,即从特征全集开始,每次删除其中的一个特征并评价,直到特征集中的特征数量达到初设阈值,就选出了最佳的特征子集。我们还可以在此基础上进行扩展。因为后发式方法会导致局部最优,所以加入模拟退火方式进行改善,这种方式不会因为新加入的特征不能改善效果而舍弃该特征,而是对其添加权重后放入已选特征集。
这种后发式方法在竞赛中尝试过,是比较耗时、耗资源的操作,一般而言可以在线上线下增益一致且数据集量级不大的情况下使用。
-
递归消除特征法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练都会先消除若干权值系数的特征,再基于新特征集进行下一轮训练。可以使用 feature_selection 库的 RFE 类来进行特征选择。代码示例如下∶from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression # 递归消除特征法,返回特征选择后的数据 # 参数estimator 为基模型 # 参数n_features_to_select 为选择的特征个数 RFE(estimator=LogisticRegression(),n_features_to_select=2).fit_transform(data, target)
使用技巧
在使用封装方法进行特征选择时,用全量数据训练并不是最明智的选择。应先对大数据进行采样,再对小数据使用封装方法。
上述三种特征选择方法需要根据实际问题选择或者组合使用,建议优先考虑特征重要性,其次是特征关联性。另外,还有一些不常见的特征选择方法,比如 Kaggle 上非常经典的 null importance 特征选择方式。
模型有时其实很蠢,很多和目标标签根本没有关联的特征,它也可以将之和目标标签关联上,这种被虚假关联到测试集上的特征会导致过拟合,从而产生负面影响。之后特征重要性分析就会变得不那么可靠,那么该如何在特征重要性分析中区分某个特征是否有用呢?
null importance 的思想其实很简单,就是将构建好的特征和正确的标签喂入树模型得到一个特征重要性分数,再将特征和打乱后的标签喂入树模型得到一个特征重要性分数,然后对比这两个分数,如果前者没有超过后者,那么这个特征就是一个无用的特征。
5. 实战案例
见代码仓库
















 5961
5961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









