







根据多篇博客整理,仅供参考学习。
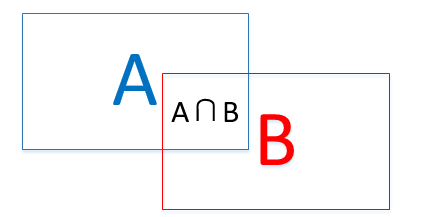
先解释什么叫IoU。如下图所示IoU即表示(A∩B)/(A∪B)
会将Roi Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时,利用L1 Loss完成bounding box regression回归操作获得物体的精确位置.
具体怎么做呢?
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
NMS(非极大值抑制)
由于锚点经常重叠,因此建议最终也会在同一个目标上重叠。为了解决重复建议的问题,我们使用一个简单的算法,称为非极大抑制(NMS)。NMS 获取按照分数排序的建议列表并对已排序的列表进行迭代,丢弃那些 IoU 值大于某个预定义阈值的建议,并提出一个具有更高分数的建议。总之,抑制的过程是一个迭代-遍历-消除的过程。如下图所示:
将所有候选框的得分进行排序,选中最高分及其所对应的BB;

遍历其余的框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们将其删除。

从没有处理的框中继续选择一个得分最高的,重复上述过程。

详解 ROI Align 的基本原理和实现细节---http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
ROI Pooling这一操作存在两次量化的过程。
- 将候选框边界量化为整数点坐标值。
- 将量化后的边界区域平均分割成 k x k 个单元(bin),对每一个单元的边界进行量化。
其整体流程如下所示:
首先对输入的图片进行裁剪操作,并将裁剪后的图片送入预训练好的分类网络中获取该图像对应的特征图;
然后在特征图上的每一个锚点上取9个候选的ROI(3个不同尺度,3个不同长宽比),并根据相应的比例将其映射到原始图像中(因为特征提取网络一般有conv和pool组成,但是只有pool会改变特征图的大小,因此最终的特征图大小和pool的个数相关);
接着将这些候选的ROI输入到RPN网络中,RPN网络对这些ROI进行分类(即确定这些ROI是前景还是背景)同时对其进行初步回归(即计算这些前景ROI与真实目标之间的BB的偏差值,包括Δx、Δy、Δw、Δh),然后做NMS(非极大值抑制,即根据分类的得分对这些ROI进行排序,然后选择其中的前N个ROI);
接着对这些不同大小的ROI进行ROI Pooling操作(即将其映射为特定大小的feature_map,文中是7x7),输出固定大小的feature_map;
最后将其输入简单的检测网络中,然后利用1x1的卷积进行分类(区分不同的类别,N+1类,多余的一类是背景,用于删除不准确的ROI),同时进行BB回归(精确的调整预测的ROI和GT的ROI之间的偏差值),从而输出一个BB集合。















 3651
3651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









