







本文主要是通过分析五级流水及流水线互锁的原理,从而可以编写出更加高效的汇编代码。
1. ARM9五级流水线
ARM7采用的是典型的三级流水线结构,包括取指、译码和执行三个部分。其中执行单元完成了大量的工作,包括与操作数相关的寄存器和存储器读写操作、ALU操作及相关器件之间的数据传输。这三个阶段每个阶段一般会占用一个时钟周期,但是三条指令同时进行三级流水的三个阶段的话,还是可以达到每个周期一条指令的。但执行单元往往会占用多个时钟周期,从而成为系统性能的瓶颈。
ARM9采用了更高效的五级流水线设计,在取指(fetch)、译码(decode)、执行(ALU)之后增加了LS1和LS2阶段,LS1负责加载和存储指令中指定的数据,LS2负责提取、符号扩展通过字节或半字加载命令加载的数据。但是LS1和LS2仅对加载和存储命令有效,其它指令不需要执行这两个阶段。比如:ldr,str就是两个加载和存储指令, ARM微处理器支持加载/存储指令用于在寄存器和存储器之间传送数据,加载指令用于将存储器中的数据传送到寄存器,存储指令则完成相反的操作。
下面是ARM官方文档的定义:-
Fetch: Fetch from memory the instruction at addresspc. The instruction is loaded intothe core and then processes down the core pipeline.
-
Decode: Decode the instruction that was fetched in the previous cycle. The processoralso reads the input operands from the register bank if they are not available via one ofthe forwarding paths.
-
ALU: Executes the instruction that was decoded in the previous cycle. Note this instruc-tion was originally fetched from addresspc−8 (ARM state) orpc−4 (Thumb state).Normally this involves calculating the answer for a data processing operation, or theaddress for a load, store, or branch operation. Some instructions may spend severalcycles in this stage. For example, multiply and register-controlled shift operations takeseveral ALU cycles.
-
LS1: Load or store the data specified by a load or store instruction. If the instruction isnot a load or store, then this stage has no effect.
-
LS2: Extract and zero- or sign-extend the data loaded by a byte or halfword loadinstruction. If the instruction is not a load of an 8-bit byte or 16-bit halfword item,then this stage has no effect.
ARM9五级流水中,读寄存器的操作转移到译码阶段,将三级流水中的执行阶段进一步细化,减少了每个时钟周期内必须完成的工作量,这样可以使流水线的各个阶段在功能上更加平衡,避免数据访问和取指的总线冲突,每条指令的平均周期数明显减少。
流水线的概念与原理
处理器按照一系列的步骤来执行每一条指令,典型的步骤如下:
1.从存储器读取指令(fetch)
2.译码以鉴别它是属于哪一条指令(decode)
3.从指令中提取指令的操作数(这些操作数往往位于寄存器中)(reg)
4.将操作数进行组合以得到结果或存储器地址(ALU)
5.如果需要,则访问存储器以存储数据(mem)
6.将结果写回到寄存器堆(res)
5级流水线ARM组织:取指令->译码->执行->缓冲/数据->回写
2. 流水线互锁问题
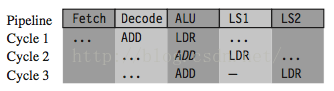
-
LDR r1, [r2, #
4]
-
ADD r0, r0, r1
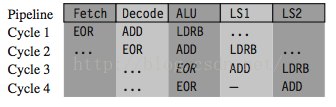
-
LDRB r1, [r2, #
1]
-
ADD r0, r0, r2
-
EOR r0, r0, r1
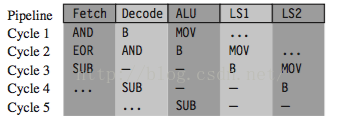
再看下面例子:
-
MOV r1, #
1
-
B case1
-
AND r0, r0, r1 EOR r2, r2, r3 ...
-
case1:
-
SUB r0, r0, r1
3. 避免流水线互锁以提高运行效率
-
void str_tolower(char *out, char *in)
-
{
-
unsigned
int c;
-
do {
-
c = *(in++);
-
if (c>=’A’ && c<=’Z’)
-
{
-
c = c + (’a’ -’A’);
-
}
-
*(out++) = (
char)c;
-
}
while (c);
-
}
-
str_tolower
-
LDRB r2,[r1],#
1 ; c = *(in++)
-
SUB r3,r2,#
0x41 ; r3=c-‘A’
-
CMP r3,#
0x19 ;
if (c <=‘Z’-‘A’)
-
ADDLS r2,r2,#
0x20 ; c +=‘a’-‘A’
-
STRB r2,[r0],#
1 ; *(out++) = (
char)c
-
CMP r2,#
0 ;
if (c!=
0)
-
BNE str_tolower ;
goto str_tolower
-
MOV pc,r14 ;
return
3.1 Load Scheduling by Preloading
-
out RN
0 ; pointer to output
string
-
in RN
1 ; pointer to input
string
-
c RN
2 ; character loaded
-
t RN
3 ; scratch
register
-
;
void str_tolower_preload(char *out, char *in)
-
str_tolower_preload
-
LDRB c, [in], #1 ; c = *(in++)
-
loop
-
SUB t, c, #’A’ ; t = c-’A’
-
CMP t, #’Z’-’A’ ;
if (t <= ’Z’-’A’)
-
ADDLS c, c, #’a’-’A’ ; c += ’a’-’A’;
-
STRB c, [out], #
1 ; *(out++) = (
char)c;
-
TEQ c, #
0 ; test
if c==
0
-
LDRNEB c, [in], #
1 ;
if (c!=
0) { c=*in++;
-
BNE loop ;
goto loop; }
-
MOV pc, lr ;
return
3.2 Load Scheduling by Unrolling
-
out RN
0 ; pointer to output
string
-
in RN
1 ; pointer to input
string
-
ca0 RN
2 ; character
0
-
t RN
3 ; scratch
register
-
ca1 RN
12 ; character
1
-
ca2 RN
14 ; character
2
-
-
;
void str_tolower_unrolled(char *out, char *in)
-
str_tolower_unrolled
-
STMFD sp!, {lr} ; function entry
-
loop_next3
-
LDRB ca0, [in], #
1 ; ca0 = *in++;
-
LDRB ca1, [in], #
1 ; ca1 = *in++;
-
LDRB ca2, [in], #
1 ; ca2 = *in++;
-
SUB t, ca0, #’A’ ; convert ca0 to lower
case
-
CMP t, #’Z’-’A’
-
ADDLS ca0, ca0, #’a’-’A’
-
SUB t, ca1, #’A’ ; convert ca1 to lower
case
-
CMP t, #’Z’-’A’
-
ADDLS ca1, ca1, #’a’-’A’
-
SUB t, ca2, #’A’ ; convert ca2 to lower
case
-
CMP t, #’Z’-’A’
-
ADDLS ca2, ca2, #’a’-’A’
-
STRB ca0, [out], #
1 ; *out++ = ca0;
-
TEQ ca0, #
0 ;
if (ca0!=
0)
-
STRNEB ca1, [out], #
1 ; *out++ = ca1;
-
TEQNE ca1, #
0 ;
if (ca0!=
0 && ca1!=
0)
-
STRNEB ca2, [out], #
1 ; *out++ = ca2;
-
TEQNE ca2, #
0 ;
if (ca0!=
0 && ca1!=
0 && ca2!=
0)
-
BNE loop_next3 ;
goto loop_next3;
-
LDMFD sp!, {pc} ;
return;














 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









